faiss教程
一、faiss教程
1.1 faiss教程
Faiss是Facebook AI团队开源的针对聚类和相似性搜索库,为稠密向量提供高效相似度搜索和聚类,支持十亿级别向量的搜索,是目前最为成熟的近似近邻搜索库。它包含多种搜索任意大小向量集(备注:向量集大小由RAM内存决定)的算法,以及用于算法评估和参数调整的支持代码。Faiss用C++编写,并提供与Numpy完美衔接的Python接口。除此以外,对一些核心算法提供了GPU实现。
- 关于相似性搜索
传统的数据库是由包含符号信息的结构化数据表组成。比如,一个图片集可以表示为一个数据表,每行代表一个被索引的图片,包含图片标识符和描述文字之类的信息;每一行也可以与其他数据表中的实体关联起来,比如某个用户的一张图片可以与用户姓名表建立关联。
像文本嵌入(word2vec)或者卷积神经网络(CNN)描述符这样通过深度学习训练出的AI工具,都可以生成高维向量。这种表示远比一个固定的符号表示更加强大和灵活,正如后文将解释的那样。然而使用SQL查询的传统数据库并不适用这些新的表示方式。首先,海量多媒体信息的涌入产生了数十亿的向量;其次,且更重要的是,查找相似实体意味着查找相似的高维向量,如果只是使用标准查询语言这将非常低效和困难。
- 如何使用向量表示?
假设有一张建筑物的图片——比如某个你不记得名字的中等规模城市的市政大厅——然后你想在图片集中查找所有该建筑物的图片。由于不记得城市的名字,此时传统SQL中常用的key/value查询就帮不上忙了。这就是相似性搜索的用武之地了。图片的向量化表示旨在为相似的图片生成相似向量,这里相似向量定义为欧氏距离最近的向量。
向量化表示的另一个应用是分类。假设需要一个分类器,来判定某个相册中的哪些图片属于菊花。分类器的训练过程众所周知:给算法分别输入菊花的图片和非菊花的图片(比如汽车、羊、玫瑰、矢车菊等);如果分类器是线性的,那么就输出一个分类向量,其属性值是它与图片向量的点积,反映了该图片包含菊花的可能性;然后分类器可以与相册中所有图片计算点积,并返回点积最大的图片。这种查询就是"最大内积"搜索。
所以,对于相似性搜索和分类,我们需要做下列处理:
给定一个查询向量,返回与该向量的欧式距离最近的数据库对象列表。
给定一个查询向量,返回与该向量点积最大的数据库对象列表。
一个额外的挑战是,要在一个超大规模比如数十亿向量上做这些运算。
- 软件包
现有软件工具都不足以完成上述数据库检索操作。传统的SQL数据库系统也不太适合,因为它们是为基于哈希的检索或1维区间检索而优化的;像OpenCV等软件包中的相似性搜索功能在扩展性方面则严重受限;同时其他的相似性搜索类库主要适用于小规模数据集(比如,1百万大小的向量);另外的软件包基本是为发表论文而输出的学术研究产物,旨在展示某些特定设置下的效果。
faiss类库则解决了以上提到的种种局限,其优点如下:
提供了多种相似性搜索方法,支持各种各样的不同用法和功能集。
特别优化了内存使用和速度。
为最相关索引方法提供了最先进的GPU实现。
- 相似性搜索评估
一旦从学习系统(从图片、视频、文本文件以及其他地方)抽取出向量,就能准备将其用于相似性搜索类库。我们有一个暴力算法作为参考对比,该算法计算出了所有的相似度——非常精确和齐全——然后返回最相似的元素列表。这就提供了一个黄金标准的参考结果列表。需要注意的是,暴力算法的高效实现并不简单,一般依赖于其他组件的性能。
如果牺牲一些精度的话,比如允许与参考结果有一点点偏差,那么相似性搜索能快几个数量级。举个例子,如果一张图片的相似性搜索结果中的第一个和第二个交换了,可能并没有太大问题,因为对于一个给定的查询,它们可能都是正确结果。加快搜索速度还涉及到数据集的预处理,我们通常把这个预处理操作称作索引。
这样一来我们就关注到下面三个指标:
速度 :找到与查询最相似的10个或更多个向量要耗时多久?期望比暴力算法耗时更少,不然索引的意义何在?
内存消耗 :该方法需要消耗多少RAM?比原始向量更多还是更少?Faiss支持只在RAM上搜索,而磁盘数据库就会慢几个数量级,即便是SSD也是一样。
精确度 :返回的结果列表与暴力搜索结果匹配程度如何?精确度可以这样评估,计算返回的真正最近邻结果在查询结果第一位(这个指标一般叫做1-recall@1)的数量,或者衡量返回结果前10个(即指标10-intersection)中包含10个最近邻结果的平均占比。
通常我们都会在确定的内存资源下在速度和精准度之间权衡。faiss专注于压缩原始向量的方法,因为这是扩展到数十亿向量数据集的不二之选:当必须索引十亿个向量的时候,每个向量32字节,就会消耗很大的内存。
许多索引类库适用于百万左右向量的小规模数据集,比如nmslib就包含了一些适于这种规模数据的非常高效的算法,这比faiss快很多,但需要消耗更多的存储。
- 基于10亿向量的评估
由于工程界并没有针对这种大小数据集的公认基准,所以我们就基于研究结果来评估。
评估精度基于Deep1B,这是一个包含10亿图片的数据集。每张图片已通过CNN处理,CNN激活图之一用于图片描述。比较这些向量之间的欧氏距离,就能量化图片的相似程度。
Deep1B还带有一个较小的查询图片集,以及由暴力算法产生的真实相似性搜索结果。因此,如果运行一个搜索算法,就能评估结果中的1-recall@1。
- 选择索引
为了评估,我们把内存限制在30G以内。这个内存约束是我们选择索引方法和参数的依据。faiss中的索引方法表示为一个字符串,在本例中叫做OPQ20_80,IMI2x14,PQ20。该字符串包含的信息有,作用到向量上的预处理步骤(OPQ20_80),一个选择机制(IMI2x14)表明数据库如何分区,以及一个编码组件(PQ20)表示向量编码时使用一个产品量化器(PQ)来生成一个20字节的编码。所以在内存使用上,包括其他开销,累计少于30G。这听起来技术性较强,所以faiss文档提供了使用指南,来说明如何选择满足需求的最佳索引。
选好了索引类型,就可以开始执行索引过程了。faiss中的算法实现会处理10亿向量并把它们置于一个索引库中。索引会存在磁盘上或立即使用,检索和增加/移除索引的操作可以穿插进行。
- 查询索引
当索引准备好以后,一系列搜索时间参数就会被设置来调整算法。为方便评估,这里使用单线程搜索。由于内存消耗是受限并固定的,所以需要在精确度和搜索时间之间权衡优化。举例说来,这表示为了获取40%的1-recall@1,可以设置参数以花费尽可能短的搜索时间。
幸运的是,faiss带有一个自动调优机制,能扫描参数空间并收集提供最佳操作点的参数;也就是说,最可能的搜索时间对应某个精确度,反之亦然,最优的精确度对应某个搜索时间。Deep1B中操作点被可视化为如下图示:
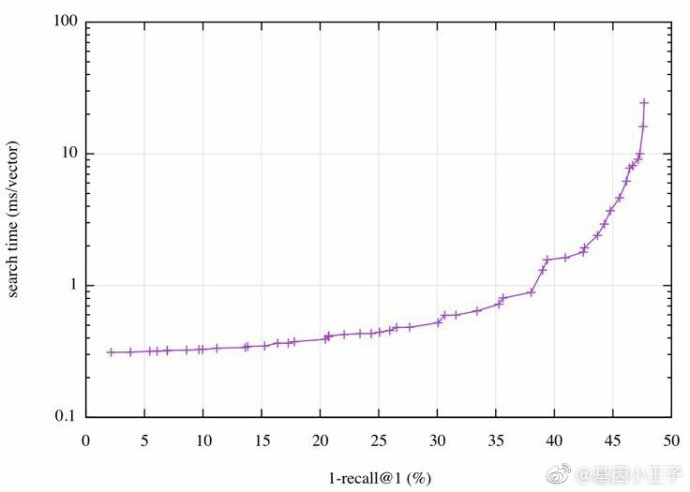
本图中我们可以看到,达到40%的1-recall@1,要求每次查询耗时必须小于2ms,或者能优化到耗时0.5ms的话,就可以达到30%的1-recall@1。一次查询耗时2ms表示单核500QPS的处理能力。
这个结果基本上能媲美目前业内最新研究成果了,即Babenko和Lempitsky在CVPR 2016发表的论文"Efficient Indexing of Billion-Scale Datasets of Deep Descriptors",这篇论文介绍了Deep1B数据集,他们达到45%的1-recall@1需要耗时20ms。
- 10亿级数据集的GPU计算
GPU实现方面也做了很大的投入,在原生多GPU的支持下能产出惊人的单机性能。GPU实现已经可以作为对应CPU设备的替代,无需了解CUDA API就能挖掘出GPU的性能。faiss支持所有Nvidia2012之后发布的GPU(Kepler,计算能力3.5+)。
我们把roofline model作为指南,它指出应当尽量让内存带宽或浮点运算单元满载。faiss的GPU实现在单GPU上的性能要比对应的CPU实现快5到10倍,像英伟达P100这样的新型Pascal架构硬件甚至会快20倍以上。
一些性能关键数字:
对于近似的索引,使用YFCC100M数据集中的9500万张图片,一个基于128D CNN描述符的暴力k近邻图(k=10),只需4个Maxwell TitanX GPU就能在35分钟内构建完成,包括索引构建时间。
十亿级向量的k近邻图现在触手可及。基于Deep1B数据集,可以构建一个暴力k-NN图(k=10),达到0.65的10-intersection,需要使用4个Maxwell TitanX GPU花费不到12小时,或者达到0.8,使用8个Pascal P100-PCIe GPU消耗不到12小时。TitanX配置可以在不到5小时生成低质量的图。
其他组件也表现出了骄人的性能。比如,构建上述Deep1B索引需要使用k均值聚类6701万个120维的向量到262,144个簇,对于25E-M迭代需要在4个Titan X GPU(12.6tflop/s)上花139分钟,或者在8个P100 GPU(40tflop/s)上花43.8分钟。注意聚类的训练数据集并不需要放在GPU内存中,因为数据可以在需要时流到GPU而没有额外的性能影响。
- 底层实现
Facebook AI研究团队2015年就开始开发faiss,这建立在许多研究成果和大量工程实践的基础之上。对于faiss类库,我们选择聚焦在一些基础技术方面的优化,特别是在CPU方面,我们重度使用了:
采用多线程来利用多核资源,并在多个GPU上执行并行检索。
使用BLAS类库通过矩阵和矩阵乘法来高效精准地完成距离计算。一个不采用BLAS的暴力实现很难达到最优。BLAS/LAPACK是Faiss唯一强制依赖的软件。
采用机器SIMD向量化和popcount加速独立向量的距离计算。
- 关于GPU
对于前述相似性搜索的GPU实现,k-selection(查找k个最小或最大元素)有一个性能问题,因为传统CPU算法(比如堆查找算法)对GPU并不友好。针对faiss GPU,我们设计了文献中已知的最快轻量k-selection算法(k<=1024)。所有的中间状态全部保存在寄存器,方便高速读写。可以对输入数据一次性完成k-select,运行至高达55%的理论峰值性能,作为输出的峰值GPU内存带宽。因为其状态单独保存在寄存器文件中,所以与其他内核很容易集成,使它成为极速的精准和近似检索算法。
大量的精力投在了为高效策略做铺垫,以及近似搜索的内核实现。通过数据分片或数据副本可以提供对多核GPU支持,而不会受限于单GPU的可用显存大小;还提供了对半精度浮点数的支持(float16),可在支持的GPU上做完整float16运算,以及早期架构上提供的中间float16存储。我们发现以float16编码向量技术可以做到精度无损加速。
简而言之,对关键因素的不断突破在实践中非常重要,faiss确实在工程细节方面下了很大的功夫。
1.2 faiss使用
参考:https://github.com/facebookresearch/faiss/wiki
这里仅使用python版,如果需要了解C++版,请参考github wiki。
faiss总体使用过程可以分为三步:
- 构建训练数据(以矩阵形式表达)
- 挑选合适的Index(Faiss的核心部件),将训练数据add进Index中。
- Search,也就是搜索,得到最后结果
构建训练数据
import numpy as np
d = 64 # dimension
nb = 100000 # database size
nq = 10000 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
上面的代码,生成了训练数据矩阵xd,以及查询数据矩阵xq。仅仅为了好玩,分别在xd和xq所有数据的第一个维度中添加了一个偏移量,并且偏移量随着id数字的增大而增大。
创建Index对象以及add训练数据
import faiss # make faiss available
index = faiss.IndexFlatL2(d) # build the index
print(index.is_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)
faiss是围绕Index对象构建的,faiss也提供了许多种类的Index,这里简单起见,使用IndexFlatL2:一个蛮力L2距离搜索的索引。所有索引都需要知道它们是何时构建的,它们运行的向量维数是多少(在我们的例子中是d),然后,大多数索引还需要训练阶段(training phase),以分析向量的分布。对于IndexFlatL2,我们可以跳过此操作。
搜索
k = 4 # we want to see 4 nearest neighbors
D, I = index.search(xb[:5], k) # sanity check
print(I)
print(D)
D, I = index.search(xq, k) # actual search
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries
可以对索引执行的基本搜索操作是k最近邻搜索,即:对于每个查询向量,在数据库中查找其k个最近邻居。所以结果集应该是一个size为nq*k的矩阵。
上述代码,做了两次搜索:
第一次的查询数据,直接使用了训练数据的前5行,这样子更加有比较性。I和D分别代表Id和Distance,也就是距离和邻居的id。结果分别如下:
[[ 0 393 363 78]
[ 1 555 277 364]
[ 2 304 101 13]
[ 3 173 18 182]
[ 4 288 370 531]]
[[ 0. 7.17517328 7.2076292 7.25116253]
[ 0. 6.32356453 6.6845808 6.79994535]
[ 0. 5.79640865 6.39173603 7.28151226]
[ 0. 7.27790546 7.52798653 7.66284657]
[ 0. 6.76380348 7.29512024 7.36881447]]
I直接显示了与搜索向量最相近的4个邻居的ID,D显示了与搜索向量之间的距离。
第二次的搜索结果如下:
[[ 381 207 210 477]
[ 526 911 142 72]
[ 838 527 1290 425]
[ 196 184 164 359]
[ 526 377 120 425]]
[[ 9900 10500 9309 9831]
[11055 10895 10812 11321]
[11353 11103 10164 9787]
[10571 10664 10632 9638]
[ 9628 9554 10036 9582]]
- 更快查询
为了加快搜索速度,我们可以按照一定规则或者顺序将数据集分段。我们可以在d维空间中定义Voronoi单元,并且每个数据库向量都会落在其中一个单元。在搜索时,查询向量x,可以经过计算,算出它会落在哪个单元格中。然后我们只需要在这个单元格以及与它相邻的一些单元格中,进行与查询向量x的比较工作就可以了。(这里可以类比HashMap的实现原理,训练就是生成hashmap的过程,查询就是getByKey的过程)。
上述工作已经通过IndexIVFFlat实现了,这种类型的索引需要一个训练阶段,可以对与数据库矢量具有相同分布的任何矢量集合执行。在这种情况下,我们只使用数据库向量本身。IndexIVFFlat同时需要另外一个Index:quantizer,来给Voronoi单元格分配向量。每个单元格由质心(centroid)定义,找某个向量落在哪个Voronoi单元格的任务,就是一个在质心集合中找这个向量最近邻居的任务。这是另一个索引的任务,通常是IndexFlatL2。
这里搜索方法有两个参数:nlist(单元格数量),nprobe(一次搜索可以访问的单元格数量,默认为1)。搜索时间大致随着nprobe的值加上一些由于量化产生的常数,进行线性增长。代码如下:
nlist = 100
k = 4
quantizer = faiss.IndexFlatL2(d) # 另外一个 Index
index = faiss.IndexIVFFlat(quantizer, d, nlist, faiss.METRIC_L2) # 这里我们指定了 METRIC_L2, 默认它执行inner-product搜索。
assert not index.is_trained
index.train(xb)
assert index.is_trained
index.add(xb) # add may be a bit slower as well
D, I = index.search(xq, k) # actual search
print(I[-5:]) # neighbors of the 5 last queries
index.nprobe = 10 # default nprobe is 1, try a few more
D, I = index.search(xq, k)
print(I[-5:]) # neighbors of the 5 last queries
运行结果
当nprobe=1的输出:
[[ 9900 10500 9831 10808]
[11055 10812 11321 10260]
[11353 10164 10719 11013]
[10571 10203 10793 10952]
[ 9582 10304 9622 9229]]
结果与蛮力搜索类似,但不完全相同(见上文),这是因为一些结果不在完全相同的Voronoi单元格中。因此,访问更多的单元格可能会有用。
把nprobe上升到10的结果:
[[ 9900 10500 9309 9831]
[11055 10895 10812 11321]
[11353 11103 10164 9787]
[10571 10664 10632 9638]
[ 9628 9554 10036 9582]]
这个就是正确的结果。请注意,在这种情况下获得完美结果仅仅是数据分布的工件,因为它在x轴上具有强大的组件,这使得它更容易处理。nprobe参数始终是调整结果的速度和准确度之间权衡的一种方法。设置nprobe=nlist会产生与暴力搜索相同的结果(但速度较慢)。
- 减少内存占用
IndexFlatL2和IndexIVFFlat都会存储所有的向量。为了扩展到非常大的数据集,Faiss提供了一些变体,它们根据产品量化器(productquantizer)压缩存储的矢量并进行有损压缩。矢量仍然存储在Voronoi单元中,但是它们的大小减小到可配置的字节数m(d必须是m的倍数)。压缩基于Product Quantizer,其可以被视为额外的量化水平,其应用于要编码的矢量的子矢量。
在这种情况下,由于矢量未精确存储,因此搜索方法返回的距离也是近似值。代码如下:
nlist = 100
m = 8 # number of bytes per vector
k = 4
quantizer = faiss.IndexFlatL2(d) # this remains the same
index = faiss.IndexIVFPQ(quantizer, d, nlist, m, 8)
# 8 specifies that each sub-vector is encoded as 8 bits
index.train(xb)
index.add(xb)
D, I = index.search(xb[:5], k) # sanity check
print(I)
print(D)
index.nprobe = 10 # make comparable with experiment above
D, I = index.search(xq, k) # search
print(I[-5:])
结果看起来时这个样子的:
[[ 0 608 220 228]
[ 1 1063 277 617]
[ 2 46 114 304]
[ 3 791 527 316]
[ 4 159 288 393]]
[[ 1.40704751 6.19361687 6.34912491 6.35771513]
[ 1.49901485 5.66632462 5.94188499 6.29570007]
[ 1.63260388 6.04126883 6.18447495 6.26815748]
[ 1.5356375 6.33165455 6.64519501 6.86594009]
[ 1.46203303 6.5022912 6.62621975 6.63154221]]
我们可以观察到我们正确找到了最近邻居(它是矢量ID本身),但是矢量与其自身的估计距离不是0,尽管它明显低于到其他邻居的距离。这是由于有损压缩造成的,这里我们将64个32位浮点数压缩为8个字节,因此压缩因子为32。搜索真实查询时,结果如下所示:
[[ 9432 9649 9900 10287]
[10229 10403 9829 9740]
[10847 10824 9787 10089]
[11268 10935 10260 10571]
[ 9582 10304 9616 9850]]
它们可以与上面的IVFFlat结果进行比较。对于这种情况,大多数结果都是错误的,但它们位于空间的正确区域,如10000左右的ID所示。实际数据的情况更好,因为:
统一数据很难索引,因为没有可用于聚类或降低维度的规律性
对于自然数据,语义最近邻居通常比不相关的结果更接近。
- 简化索引构建
由于构建索引可能变得复杂,因此有一个工厂函数在给定字符串的情况下构造它们。上述索引可以通过以下简写获得:
index = faiss.index_factory(d, "IVF100,PQ8")
把”PQ8”替换为“Flat”,就可以得到一个IndexFlat。当需要预处理(PCA)应用于输入向量时,工厂就特别有用。例如要使用PCA投影将矢量减少到32D的预处理时,工厂字符串应该时:"PCA32,IVF100,Flat"。
- 使用GPU
# 获取单个 GPU 资源
res = faiss.StandardGpuResources() # use a single GPU
# 使用GPU资源构建GPU索引
# build a flat (CPU) index
index_flat = faiss.IndexFlatL2(d)
# make it into a gpu index
gpu_index_flat = faiss.index_cpu_to_gpu(res, 0, index_flat)
# 多个索引可以使用单个GPU资源对象,只要它们不发出并发查询即可。
# 获得的GPU索引可以与CPU索引完全相同的方式使用:
gpu_index_flat.add(xb) # add vectors to the index
print(gpu_index_flat.ntotal)
k = 4 # we want to see 4 nearest neighbors
D, I = gpu_index_flat.search(xq, k) # actual search
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries
# 使用多个GPU
## 使用多个GPU主要是声明几个GPU资源,在python中,这可以使用index_cpu_to_all_gpus帮助程序隐式完成。
ngpus = faiss.get_num_gpus()
print("number of GPUs:", ngpus)
cpu_index = faiss.IndexFlatL2(d)
gpu_index = faiss.index_cpu_to_all_gpus( # build the index
cpu_index
)
gpu_index.add(xb) # add vectors to the index
print(gpu_index.ntotal)
k = 4 # we want to see 4 nearest neighbors
D, I = gpu_index.search(xq, k) # actual search
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries

二、faiss原理
2.1 faiss核心算法实现
faiss对一些基础的算法提供了非常高效的失效
- 聚类faiss提供了一个高效的k-means实现
- PCA降维算法
- PQ(Product Quantizer)编码/解码
2.2 faiss功能流程说明
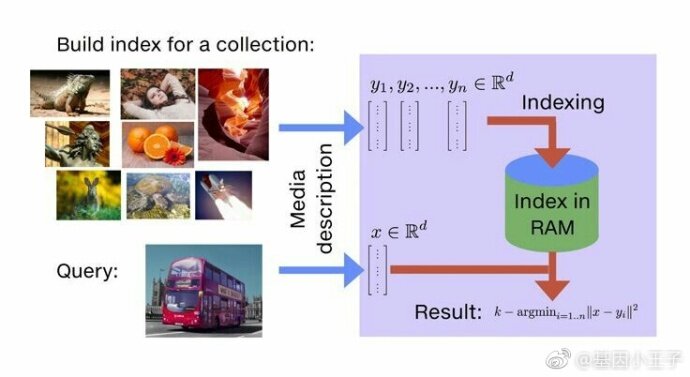
通过faiss文档介绍可以了解faiss的主要功能就是相似度搜索。如下图所示,以图片搜索为例,所谓相似度搜索,便是在给定的一堆图片中,寻找出我指定的目标最像的K张图片,也简称为KNN(K近邻)问题。
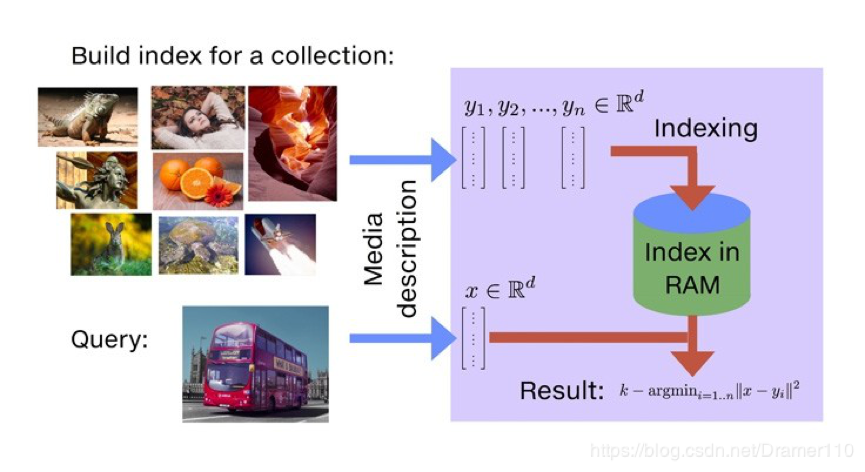
为了解决KNN问题,在工程上需要实现对已有图库的存储,当用户指定检索图片后,需要知道如何从存储的图片库中找到最相似的K张图片。基于此,我们推测faiss在应用场景中具备添加功能和搜索功能,有了添加相应的修改和删除功能也会接踵而来,从上述分析看,faiss本质上是一个向量(矢量)数据库。
对于数据库来说,时空优化是两个永恒的主题,即在存储上如何以更少的空间来存储更多的信息,在搜索上如何以更快的速度来搜索出更准确的信息。如何减少搜索所需的时间?在数据库中很最常见的操作便是加各种索引,把各种加速搜索算法的功能或空间换时间的策略都封装成各种各样的索引,以满足各种不同的引用场景。
2.3 组件分析
faiss中最常用的是索引Index,而后是PCA降维、PQ乘积量化,这里针对Index和PQ进行说明,PCA降维从流程上都可以理解。
2.3.1 索引Index
faiss中有两个基础索引类Index、IndexBinary,下面我们先从类图进行分析。下面给出Index和IndexBinary的类图如下所示:


Faiss提供了针对不同场景下应用对Index的封装类,这里我们针对Index基类进行说明。
基础索引的说明参考:faiss indexes涉及方法解释、参数说明以及推荐试用的工厂方法创建时的标识等。
索引的创建提供了工厂方法,可以通过字符串灵活的创建不同的索引。
index = faiss.index_factory(d,"PCA32,IVF100,PQ8 ")
该字符串的含义为:使用PCA算法将向量降维到32维,划分成100个nprobe(搜索空间),通过PQ算法将每个向量压缩成8bit。其他的字符串可以参考上文给出的Faiss indexes链接中给出的标识。
- 索引说明
此部分对索引id进行说明,此部分的理解是基于PQ量化及faiss创建不同的索引时选择的量化器而来,可能会稍有偏差,不影响对Faiss的使用操作。
默认情况,faiss会为每个输入的向量记录一个次序id,也可以为向量指定任意我们需要的id。部分索引类(IndexIVFFlat/IndexPQ/IndexIVFPQ等)有add_with_ids方法,可以为每个向量对应一个64-bit的id,搜索的时候返回此id。此段中说明的id从我的角度理解就是索引。(备注:id是long型数据,所有的索引id类型在Index基类中已经定义,参考类图中标注,typedef long idx_t; ///< all indices are this type)
示例:
import numpy as np
import faiss # make faiss available
# 构造数据
import time
d = 64 # dimension
nb = 1000000 # database size
nq = 1000000 # nb of queries
np.random.seed(1234) # make reproducible
xb = np.random.random((nb, d)).astype('float32')
xb[:, 0] += np.arange(nb) / 1000.
xq = np.random.random((nq, d)).astype('float32')
xq[:, 0] += np.arange(nq) / 1000.
# 为向量集构建IndexFlatL2索引,它是最简单的索引类型,只执行强力L2距离搜索
index = faiss.IndexFlatL2(d) # build the index
# #此处索引是按照默认方式,即faiss给的次序id为主
# #可以添加我们需要的索引方式,因IndexFlatL2不支持add_with_ids方法,需要借助IndexIDMap进行映射,代码如下
# ids = np.arange(100000, 200000) #id设定为6位数整数,默认id从0开始,这里我们将其设置从100000开始
# index2 = faiss.IndexIDMap(index)
# index2.add_with_ids(xb, ids)
#
# print(index2.is_trained)
# # index.add(xb) # add vectors to the index
# print(index2.ntotal)
# k = 4 # we want to see 4 nearest neighbors
# D, I = index2.search(xb[:5], k) # sanity check
# print(I) # 向量索引位置
# print(D) # 相似度矩阵
print(index.is_trained)
index.add(xb) # add vectors to the index
print(index.ntotal)
k = 4 # we want to see 4 nearest neighbors
# D, I = index.search(xb[:5], k) # sanity check
# # print(xb[:5])
# print(I) # 向量索引位置
# print(D) # 相似度矩阵
D, I = index.search(xq, 10) # actual search
# xq is the query data
# k is the num of neigbors you want to search
# D is the distance matrix between xq and k neigbors
# I is the index matrix of k neigbors
print(I[:5]) # neighbors of the 5 first queries
print(I[-5:]) # neighbors of the 5 last queries
#从index中恢复数据,indexFlatL2索引就是将向量进行排序
# print(xb[381])
# print(index.reconstruct(381))
- 索引选择
此部分没做实践验证,对Faiss给的部分说明进行翻译过来作为后续我们使用的一个参考。
如果关心返回精度,可以使用IndexFlatL2,该索引能确保返回精确结果。一般将其作为baseline与其他索引方式对比,以便在精度和时间开销之间做权衡。不支持add_with_ids,如果需要,可以用“IDMap”给予任意定义id。
如果关注内存开销,可以使用"..., Flat“的索引,"..."是聚类操作,聚类之后将每个向量映射到相应的bucket。该索引类型并不会保存压缩之后的数据,而是保存原始数据,所以内存开销与原始数据一致。通过nprobe参数控制速度/精度。
对内存开销比较关心的话,可以在聚类的基础上使用PQ成绩量化进行处理。
- 检索数据恢复
faiss检索返回的是数据的索引及数据的计算距离,在检索获得的索引后需要根据索引将原始数据取出。
faiss提供了两种方式,一种是一条一条的进行恢复,一种是批量恢复。
给定id,可以使用reconstruct进行单条取出数据;可以使用reconstruct_n方法从index中回批量复出原始向量(备注:该方法从给的示例看是恢复连续的数据(0,10),如果索引是离散的话恢复数据暂时还没做实践)。
上述方法支持IndexFlat,IndexIVFFlat(需要与make_direct_map结合),IndexIVFPQ(需要与make_direct_map结合)等几类索引类型。
2.3.2 Product quantization(乘积量化PQ)
Faiss中使用的乘积量化是Faiss的作者在2011年发表的论文,参考:Product Quantization for Nearest Neighbor Search
PQ算法可以理解为首先把原始的向量空间分解为m个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化。即是把原始D维向量(比如D=128)分成m组(比如m=4),每组就是D^*=D/m维的子向量(比如D^*=D/m=128/4=32),各自用k-means算法学习到一个码本,然后这些码本的笛卡尔积就是原始D维向量对应的码本。用qj表示第j组子向量,用Cj表示其对应学习到的码本,那么原始D维向量对应的码本就是C=C1×C2×…×Cm。用k∗表示子向量的聚类中心点数或者说码本大小,那么原始D维向量对应的聚类中心点数或者说码本大小就是k=(k^*)^m。
示例参考实例理解product quantization算法。
- 检索和距离的关系—ADC
假如做法是以图搜图,那么输入图像为x,要从数据库中找出与x最匹配的图像集\{y\},首先提取特征,特征向量就代表图像,如果特征向量之间的距离越小,图像之间相似度越大,检索就是要找出NN(x)=arg\ min_{y\in \mathcal{Y}} d(x,y),公式中d的选取可以是欧式距离。PQ(乘积量化)中ADC的做法并不是求各个分量差的平方和,而是求x与y量化后的向量之间各个分量差的平方和。用公式表示如下:
示意图如下:
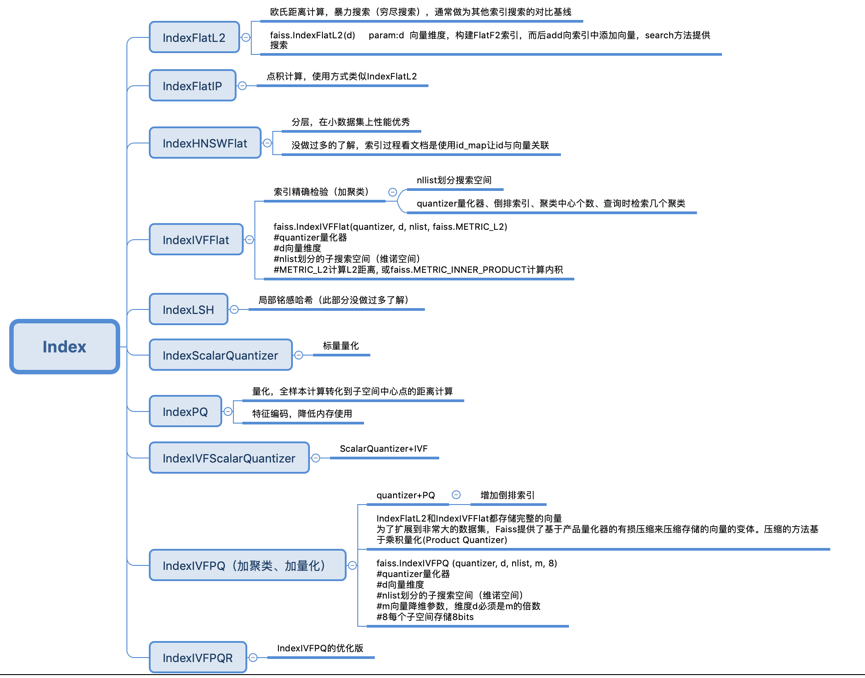
把求x与y的距离用x与q(y)的距离代替,q(y)是y量化后的结果。这样做之所以可行,论文中有详细推到,主要是两个原因:1)MSE越小,说明量化器的精度越高;2)三角形两边之和大于第三边,两边只差小于第三边。由于只是对y做量化,对x未量化,这是不对称的,这就是ADC(Asymmetric distance computation)中Asymmetric的含义,如果对y也量化,对x也量化,就是对称的。
- 索引结构
索引的建立过程如下:

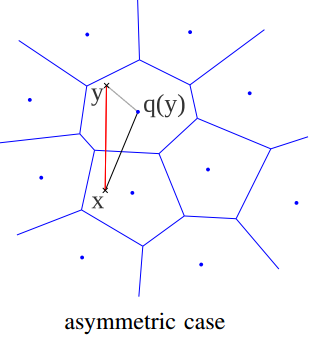
上图中主要涉及三个过程,coarse quantizer,product quantizer和append to inverted list。
coarse quantizer :对数据库中的所有特征采用K-means聚类,得到粗糙量化的类中心,比如聚类成1024类,并记录每个类的样本数和各个样本所属的类别,这个类中心的个数就是inverted list的个数,把所有类中心保存到一张表中,叫
coarse_cluster表,表中每项是d维。product quantizer :计算y的余量r(y)=y-q_c(y),用y减去y的粗糙量化的结果得到r(y)。r(y)维数与y一样,然后对所有r(y)的特征分成m组,采用乘积量化,每组内仍然使用k-means聚类,这时结果是一个m维数的向量,这就是上篇文章中提到的内容。把所有的乘积量化结果保存到一个表中,叫
pq_centroids表,表中每项是m维append to inverted list :前面的操作中记录下y在
coarse_cluster表的索引i,在pq_centroids表中的索引j,那么插入inverted list时,把(id,j)插入到第i个倒排索引中,id是y的标识符,比如文件名。list的长度就是属于第i类的样本y的数目,处理不等长list有些技巧。
- 基于IVFADC的搜索
检索过程如下:
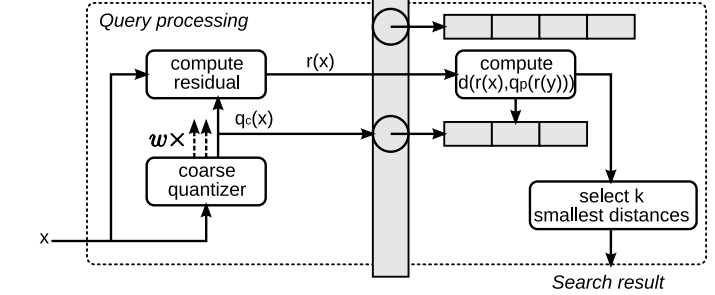
主要包括四个操作:
粗糙量化 :对查询图像x的特征进行粗糙量化,即采用KNN方法将x分到某个类或某几个类,分到几个类的话叫做multiple assignment,过程同对数据集中的y分类差不多。
计算余量 :计算x的余量r(x)。
计算d(x,y) :对r(x)分组,计算每组中r(x)的特征子集到
pq_centroids的距离。根据ADC的技巧,计算x与y的距离可以用计算x与q(y)的距离,而q(y)就是pq_centroids表中的某项,因此已经得到了x到y的近似距离。
- 最大堆排序 :堆中每个元素代表数据库中y与x的距离,堆顶元素的距离最大,只要是比堆顶元素小的元素,代替堆顶元素,调整堆,直到判断完所有的y。
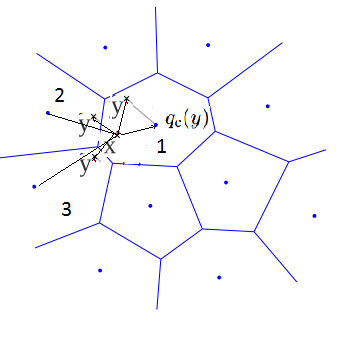
数学语言:
- PQ算法实例
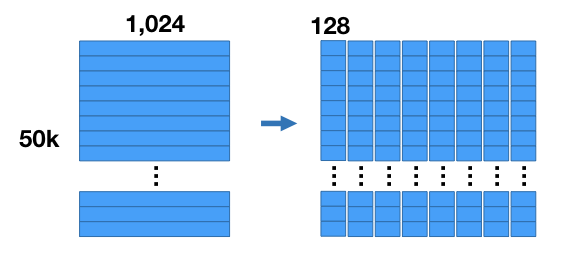
假设有50,000张图片组成的图片集,使用 CNN 提取特征后,每张图片可以由1024维的特征表示。那么整个图片集由50000*1024的向量来表示。如下图。

然后我们把1024维的向量平均分成m=8个子向量,每组子向量128维。如下图。
对于这8组子向量的每组子向量,使用kmeans方法聚成k=256类。也就是说,每个子向量有256个中心点(centroids)。如下图。
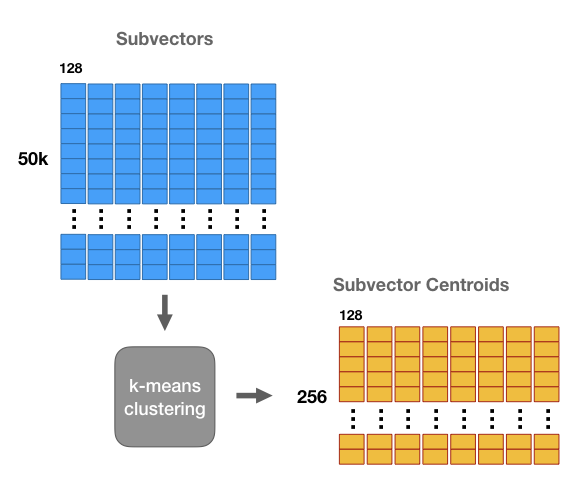
在product quantization方法中,这256个中心点构成一个码本。这些码本的笛卡尔积就是原始D维向量对应的码本。用q_j表示第j组子向量,用C_j表示其对应学习到的码本,那么原始D维向量对应的码本就是 C=C_1×C_2×\dots ×C_m,码本大小为k^m。
注意到每组子向量有其256个中心点,我们可以中心点的 ID 来表示每组子向量中的每个向量。中心点的ID只需要8位(=log_2 256)来保存即可。这样,初始一个由32位浮点数组成的1,024维向量,可以转化为8个8位整数组成。如下图。

对向量压缩后,有2种方法作相似搜索。一种是SDC(symmetric distance computation),另一种是ADC(asymmetric distance computation)。SDC算法和ADC算法的区别在于是否要对查询向量x做量化,参见公式1和公式2。如下图所示,x是查询向量(query vector),y是数据集中的某个向量,目标是要在数据集中找到x的相似向量。

- SDC算法: 先用PQ量化器对x和y表示为对应的中心点q(x)和q(y),然后用公式1来近似d(x,y)。这里 q 表示 PQ量化过程。
\hat{d}(x,y)=d(q(x),q(y))=\sqrt{\sum_jd(q_j(x),q_j(y))^2}
- ADC算法: 只对y表示为对应的中心点q(y),然后用下述公式来近似d(x,y)。
\tilde{d}(x,y)=d(x,q(y))=\sqrt{\sum_jd(u_j(x),q_j(u_j(y)))^2}
python代码:
# -*- coding:utf8 -*-
import numpy as np
from scipy.cluster.vq import vq, kmeans2
class PQ(object):
"""Pure python implementation of Product Quantization (PQ) [Jegou11]_.
For the indexing phase of database vectors,
a `D`-dim input vector is divided into `M` `D`/`M`-dim sub-vectors.
Each sub-vector is quantized into a small integer via `Ks` codewords.
For the querying phase, given a new `D`-dim query vector, the distance beween the query
and the database PQ-codes are efficiently approximated via Asymmetric Distance.
All vectors must be np.ndarray with np.float32
.. [Jegou11] H. Jegou et al., "Product Quantization for Nearest Neighbor Search", IEEE TPAMI 2011
Args:
M (int): The number of sub-space
Ks (int): The number of codewords for each subspace
(typically 256, so that each sub-vector is quantized
into 256 bits = 1 byte = uint8)
verbose (bool): Verbose flag
Attributes:
M (int): The number of sub-space
Ks (int): The number of codewords for each subspace
verbose (bool): Verbose flag
code_dtype (object): dtype of PQ-code. Either np.uint{8, 16, 32}
codewords (np.ndarray): shape=(M, Ks, Ds) with dtype=np.float32.
codewords[m][ks] means ks-th codeword (Ds-dim) for m-th subspace
Ds (int): The dim of each sub-vector, i.e., Ds=D/M
"""
def __init__(self, M, Ks=256, verbose=True):
assert 0 < Ks <= 2 ** 32
self.M, self.Ks, self.verbose = M, Ks, verbose
self.code_dtype = np.uint8 if Ks <= 2 ** 8 else (np.uint16 if Ks <= 2 ** 16 else np.uint32)
self.codewords = None
self.Ds = None
if verbose:
print("M: {}, Ks: {}, code_dtype: {}".format(M, Ks, self.code_dtype))
def __eq__(self, other):
if isinstance(other, PQ):
return (self.M, self.Ks, self.verbose, self.code_dtype, self.Ds) == \
(other.M, other.Ks, other.verbose, other.code_dtype, other.Ds) and \
np.array_equal(self.codewords, other.codewords)
else:
return False
def fit(self, vecs, iter=20, seed=123):
"""Given training vectors, run k-means for each sub-space and create
codewords for each sub-space.
This function should be run once first of all.
Args:
vecs (np.ndarray): Training vectors with shape=(N, D) and dtype=np.float32.
iter (int): The number of iteration for k-means
seed (int): The seed for random process
Returns:
object: self
"""
assert vecs.dtype == np.float32
assert vecs.ndim == 2
N, D = vecs.shape
assert self.Ks < N, "the number of training vector should be more than Ks"
assert D % self.M == 0, "input dimension must be dividable by M"
self.Ds = int(D / self.M)
np.random.seed(seed)
if self.verbose:
print("iter: {}, seed: {}".format(iter, seed))
# [m][ks][ds]: m-th subspace, ks-the codeword, ds-th dim
self.codewords = np.zeros((self.M, self.Ks, self.Ds), dtype=np.float32)
for m in range(self.M):
if self.verbose:
print("Training the subspace: {} / {}".format(m, self.M))
vecs_sub = vecs[:, m * self.Ds : (m+1) * self.Ds]
self.codewords[m], _ = kmeans2(vecs_sub, self.Ks, iter=iter, minit='points')
return self
def encode(self, vecs):
"""Encode input vectors into PQ-codes.
Args:
vecs (np.ndarray): Input vectors with shape=(N, D) and dtype=np.float32.
Returns:
np.ndarray: PQ codes with shape=(N, M) and dtype=self.code_dtype
"""
assert vecs.dtype == np.float32
assert vecs.ndim == 2
N, D = vecs.shape
assert D == self.Ds * self.M, "input dimension must be Ds * M"
# codes[n][m] : code of n-th vec, m-th subspace
codes = np.empty((N, self.M), dtype=self.code_dtype)
for m in range(self.M):
if self.verbose:
print("Encoding the subspace: {} / {}".format(m, self.M))
vecs_sub = vecs[:, m * self.Ds : (m+1) * self.Ds]
codes[:, m], _ = vq(vecs_sub, self.codewords[m])
return codes
def decode(self, codes):
"""Given PQ-codes, reconstruct original D-dimensional vectors
approximately by fetching the codewords.
Args:
codes (np.ndarray): PQ-cdoes with shape=(N, M) and dtype=self.code_dtype.
Each row is a PQ-code
Returns:
np.ndarray: Reconstructed vectors with shape=(N, D) and dtype=np.float32
"""
assert codes.ndim == 2
N, M = codes.shape
assert M == self.M
assert codes.dtype == self.code_dtype
vecs = np.empty((N, self.Ds * self.M), dtype=np.float32)
for m in range(self.M):
vecs[:, m * self.Ds : (m+1) * self.Ds] = self.codewords[m][codes[:, m], :]
return vecs
def dtable(self, query):
"""Compute a distance table for a query vector.
The distances are computed by comparing each sub-vector of the query
to the codewords for each sub-subspace.
`dtable[m][ks]` contains the squared Euclidean distance between
the `m`-th sub-vector of the query and the `ks`-th codeword
for the `m`-th sub-space (`self.codewords[m][ks]`).
Args:
query (np.ndarray): Input vector with shape=(D, ) and dtype=np.float32
Returns:
nanopq.DistanceTable:
Distance table. which contains
dtable with shape=(M, Ks) and dtype=np.float32
"""
assert query.dtype == np.float32
assert query.ndim == 1, "input must be a single vector"
D, = query.shape
assert D == self.Ds * self.M, "input dimension must be Ds * M"
# dtable[m] : distance between m-th subvec and m-th codewords (m-th subspace)
# dtable[m][ks] : distance between m-th subvec and ks-th codeword of m-th codewords
dtable = np.empty((self.M, self.Ks), dtype=np.float32)
for m in range(self.M):
query_sub = query[m * self.Ds : (m+1) * self.Ds]
dtable[m, :] = np.linalg.norm(self.codewords[m] - query_sub, axis=1) ** 2
return DistanceTable(dtable)
class DistanceTable(object):
"""Distance table from query to codeworkds.
Given a query vector, a PQ/OPQ instance compute this DistanceTable class
using :func:`PQ.dtable` or :func:`OPQ.dtable`.
The Asymmetric Distance from query to each database codes can be computed
by :func:`DistanceTable.adist`.
Args:
dtable (np.ndarray): Distance table with shape=(M, Ks) and dtype=np.float32
computed by :func:`PQ.dtable` or :func:`OPQ.dtable`
Attributes:
dtable (np.ndarray): Distance table with shape=(M, Ks) and dtype=np.float32.
Note that dtable[m][ks] contains the squared Euclidean distance between
(1) m-th sub-vector of query and (2) ks-th codeword for m-th subspace.
"""
def __init__(self, dtable):
assert dtable.ndim == 2
assert dtable.dtype == np.float32
self.dtable = dtable
def adist(self, codes):
"""Given PQ-codes, compute Asymmetric Distances between the query (self.dtable)
and the PQ-codes.
Args:
codes (np.ndarray): PQ codes with shape=(N, M) and
dtype=pq.code_dtype where pq is a pq instance that creates the codes
Returns:
np.ndarray: Asymmetric Distances with shape=(N, ) and dtype=np.float32
"""
assert codes.ndim == 2
N, M = codes.shape
assert M == self.dtable.shape[0]
# Fetch distance values using codes. The following codes are
dists = np.sum(self.dtable[range(M), codes], axis=1)
return dists
三、源码介绍
3.1 utils目录
3.1.1 random.h和random.cpp文件
此文件描述生成随机数相关代码:float_rand,float_randn(Marsaglia's method),int64_rand,byte_rand,int64_rand_max,rand_perm。
3.1.1.1 random.h文件
/* Random generators. Implemented here for speed and to make sequences reproducible. */
#pragma once
#include <random>
#include <stdint.h>
namespace faiss {
/**************************************************
* Random data generation functions
**************************************************/
/// random generator that can be used in multithreaded contexts
struct RandomGenerator {
std::mt19937 mt;
/// random positive integer
int rand_int ();
/// random int64_t
int64_t rand_int64 ();
/// generate random integer between 0 and max-1
int rand_int (int max);
/// between 0 and 1
float rand_float ();
double rand_double ();
explicit RandomGenerator (int64_t seed = 1234);
};
/* Generate an array of uniform random floats / multi-threaded implementation */
void float_rand (float * x, size_t n, int64_t seed);
void float_randn (float * x, size_t n, int64_t seed);
void int64_rand (int64_t * x, size_t n, int64_t seed);
void byte_rand (uint8_t * x, size_t n, int64_t seed);
// max is actually the maximum value + 1
void int64_rand_max (int64_t * x, size_t n, uint64_t max, int64_t seed);
/* random permutation */
void rand_perm (int * perm, size_t n, int64_t seed);
} // namespace faiss
3.1.1.2 random.cpp文件
#include <faiss/utils/random.h>
namespace faiss {
/**************************************************
* Random data generation functions
**************************************************/
RandomGenerator::RandomGenerator (int64_t seed) : mt((unsigned int)seed) {}
int RandomGenerator::rand_int () { return mt() & 0x7fffffff; }
int64_t RandomGenerator::rand_int64 () {
return int64_t(rand_int()) | int64_t(rand_int()) << 31;
}
int RandomGenerator::rand_int (int max) { return mt() % max; }
float RandomGenerator::rand_float () { return mt() / float(mt.max()); }
double RandomGenerator::rand_double () { return mt() / double(mt.max()); }
/***********************************************************************
* Random functions in this C file only exist because Torch
* counterparts are slow and not multi-threaded. Typical use is for
* more than 1-100 billion values. */
/* Generate a set of random floating point values such that x[i] in [0,1]
multi-threading. For this reason, we rely on re-entreant functions. */
void float_rand (float * x, size_t n, int64_t seed) {
// only try to parallelize on large enough arrays
const size_t nblock = n < 1024 ? 1 : 1024;
RandomGenerator rng0 (seed);
int a0 = rng0.rand_int (), b0 = rng0.rand_int ();
#pragma omp parallel for
for (size_t j = 0; j < nblock; j++) {
RandomGenerator rng (a0 + j * b0);
const size_t istart = j * n / nblock;
const size_t iend = (j + 1) * n / nblock;
for (size_t i = istart; i < iend; i++)
x[i] = rng.rand_float ();
}
}
void float_randn (float * x, size_t n, int64_t seed) {
// only try to parallelize on large enough arrays
const size_t nblock = n < 1024 ? 1 : 1024;
RandomGenerator rng0 (seed);
int a0 = rng0.rand_int (), b0 = rng0.rand_int ();
#pragma omp parallel for
for (size_t j = 0; j < nblock; j++) {
RandomGenerator rng (a0 + j * b0);
double a = 0, b = 0, s = 0;
int state = 0; /* generate two number per "do-while" loop */
const size_t istart = j * n / nblock;
const size_t iend = (j + 1) * n / nblock;
for (size_t i = istart; i < iend; i++) {
/* Marsaglia's method (see Knuth) */
if (state == 0) {
do {
a = 2.0 * rng.rand_double () - 1;
b = 2.0 * rng.rand_double () - 1;
s = a * a + b * b;
} while (s >= 1.0);
x[i] = a * sqrt(-2.0 * log(s) / s);
}
else
x[i] = b * sqrt(-2.0 * log(s) / s);
state = 1 - state;
}
}
}
/* Integer versions */
void int64_rand (int64_t * x, size_t n, int64_t seed) {
// only try to parallelize on large enough arrays
const size_t nblock = n < 1024 ? 1 : 1024;
RandomGenerator rng0 (seed);
int a0 = rng0.rand_int (), b0 = rng0.rand_int ();
#pragma omp parallel for
for (size_t j = 0; j < nblock; j++) {
RandomGenerator rng (a0 + j * b0);
const size_t istart = j * n / nblock;
const size_t iend = (j + 1) * n / nblock;
for (size_t i = istart; i < iend; i++)
x[i] = rng.rand_int64 ();
}
}
void int64_rand_max (int64_t * x, size_t n, uint64_t max, int64_t seed) {
// only try to parallelize on large enough arrays
const size_t nblock = n < 1024 ? 1 : 1024;
RandomGenerator rng0 (seed);
int a0 = rng0.rand_int (), b0 = rng0.rand_int ();
#pragma omp parallel for
for (size_t j = 0; j < nblock; j++) {
RandomGenerator rng (a0 + j * b0);
const size_t istart = j * n / nblock;
const size_t iend = (j + 1) * n / nblock;
for (size_t i = istart; i < iend; i++)
x[i] = rng.rand_int64 () % max;
}
}
void rand_perm (int *perm, size_t n, int64_t seed) {
for (size_t i = 0; i < n; i++) perm[i] = i;
RandomGenerator rng (seed);
for (size_t i = 0; i + 1 < n; i++) {
int i2 = i + rng.rand_int (n - i);
std::swap(perm[i], perm[i2]);
}
}
void byte_rand (uint8_t * x, size_t n, int64_t seed) {
// only try to parallelize on large enough arrays
const size_t nblock = n < 1024 ? 1 : 1024;
RandomGenerator rng0 (seed);
int a0 = rng0.rand_int (), b0 = rng0.rand_int ();
#pragma omp parallel for
for (size_t j = 0; j < nblock; j++) {
RandomGenerator rng (a0 + j * b0);
const size_t istart = j * n / nblock;
const size_t iend = (j + 1) * n / nblock;
size_t i;
for (i = istart; i < iend; i++)
x[i] = rng.rand_int64 ();
}
}
} // namespace faiss
3.1.1.3 test_random.cpp文件
#include<utils/random.h>
#include <cstdlib>
#include <cstdio>
int main(){
int num=10;
float* x =new float[num];
faiss::float_rand(x, num, 0);
printf("rand float: ");
for(int i=0;i<num;i++){ printf("%f ",x[i]); }
printf("\n");
delete [] x;
float* y =new float[num];
faiss::float_randn(y, num, 0);
printf("randn float: ");
for(int i=0;i<num;i++){ printf("%f ",y[i]); }
printf("\n");
delete [] y;
int64_t* z =new int64_t[num];
faiss::int64_rand_max(z, num, 10, 0);
printf("rand int64(max=10): ");
for(int i=0;i<num;i++){ printf("%ld ",z[i]); }
printf("\n");
delete [] z;
int* w = new int[num];
faiss::rand_perm(w,num,0);
printf("rand perm: ");
for(int i=0;i<num;i++){ printf("%d ",w[i]);}
printf("\n");
delete [] w;
return 0;
}
3.1.2 Heap.h,Heap.cpp文件
此文件定义了heap_pop, heap_push,heap_heapify(建堆),heap_addn,heap_reorder以及HeapArray。
3.1.2.1 Heap.h文件
/*
* C++ support for heaps. The set of functions is tailored for
* efficient similarity search.
*
* There is no specific object for a heap, and the functions that
* operate on a signle heap are inlined, because heaps are often
* small. More complex functions are implemented in Heaps.cpp
*/
#ifndef FAISS_Heap_h
#define FAISS_Heap_h
#include <climits>
#include <cstring>
#include <cmath>
#include <cassert>
#include <cstdio>
#include <stdint.h>
#include <limits>
namespace faiss {
/*******************************************************************
* C object: uniform handling of min and max heap
*******************************************************************/
/** The C object gives the type T of the values in the heap, the type
* of the keys, TI and the comparison that is done: > for the minheap
* and < for the maxheap. The neutral value will always be dropped in
* favor of any other value in the heap.
*/
template <typename T_, typename TI_>
struct CMax;
// traits of minheaps = heaps where the minimum value is stored on top
// useful to find the *max* values of an array
template <typename T_, typename TI_>
struct CMin {
typedef T_ T;
typedef TI_ TI;
typedef CMax<T_, TI_> Crev;
inline static bool cmp (T a, T b) {
return a < b;
}
// value that will be popped first -> must be smaller than all others
// for int types this is not strictly the smallest val (-max - 1)
inline static T neutral () {
return -std::numeric_limits<T>::max();
}
};
template <typename T_, typename TI_>
struct CMax {
typedef T_ T;
typedef TI_ TI;
typedef CMin<T_, TI_> Crev;
inline static bool cmp (T a, T b) {
return a > b;
}
inline static T neutral () {
return std::numeric_limits<T>::max();
}
};
/*******************************************************************
* Basic heap ops: push and pop
*******************************************************************/
/** Pops the top element from the heap defined by bh_val[0..k-1] and
* bh_ids[0..k-1]. on output the element at k-1 is undefined.
*/
template <class C> inline
void heap_pop (size_t k, typename C::T * bh_val, typename C::TI * bh_ids) {
bh_val--; /* Use 1-based indexing for easier node->child translation */
bh_ids--;
typename C::T val = bh_val[k];
size_t i = 1, i1, i2;
while (1) {
i1 = i << 1;
i2 = i1 + 1;
if (i1 > k)
break;
if (i2 == k + 1 || C::cmp(bh_val[i1], bh_val[i2])) {
if (C::cmp(val, bh_val[i1]))
break;
bh_val[i] = bh_val[i1];
bh_ids[i] = bh_ids[i1];
i = i1;
}
else {
if (C::cmp(val, bh_val[i2]))
break;
bh_val[i] = bh_val[i2];
bh_ids[i] = bh_ids[i2];
i = i2;
}
}
bh_val[i] = bh_val[k];
bh_ids[i] = bh_ids[k];
}
/** Pushes the element (val, ids) into the heap bh_val[0..k-2] and
* bh_ids[0..k-2]. on output the element at k-1 is defined.
*/
template <class C> inline
void heap_push (size_t k,typename C::T * bh_val, typename C::TI * bh_ids, typename C::T val, typename C::TI ids) {
bh_val--; /* Use 1-based indexing for easier node->child translation */
bh_ids--;
size_t i = k, i_father;
while (i > 1) {
i_father = i >> 1;
if (!C::cmp (val, bh_val[i_father])) /* the heap structure is ok */
break;
bh_val[i] = bh_val[i_father];
bh_ids[i] = bh_ids[i_father];
i = i_father;
}
bh_val[i] = val;
bh_ids[i] = ids;
}
/* Partial instanciation for heaps with TI = int64_t */
template <typename T> inline
void minheap_pop (size_t k, T * bh_val, int64_t * bh_ids) {
heap_pop<CMin<T, int64_t> > (k, bh_val, bh_ids);
}
template <typename T> inline
void minheap_push (size_t k, T * bh_val, int64_t * bh_ids, T val, int64_t ids) {
heap_push<CMin<T, int64_t> > (k, bh_val, bh_ids, val, ids);
}
template <typename T> inline
void maxheap_pop (size_t k, T * bh_val, int64_t * bh_ids) {
heap_pop<CMax<T, int64_t> > (k, bh_val, bh_ids);
}
template <typename T> inline
void maxheap_push (size_t k, T * bh_val, int64_t * bh_ids, T val, int64_t ids) {
heap_push<CMax<T, int64_t> > (k, bh_val, bh_ids, val, ids);
}
/*******************************************************************
* Heap initialization
*******************************************************************/
/* Initialization phase for the heap (with unconditionnal pushes).
* Store k0 elements in a heap containing up to k values. Note that
* (bh_val, bh_ids) can be the same as (x, ids) */
template <class C> inline
void heap_heapify (size_t k, typename C::T * bh_val, typename C::TI * bh_ids, const typename C::T * x = nullptr,
const typename C::TI * ids = nullptr, size_t k0 = 0) {
if (k0 > 0) assert (x);
if (ids) {
for (size_t i = 0; i < k0; i++)
heap_push<C> (i+1, bh_val, bh_ids, x[i], ids[i]);
} else {
for (size_t i = 0; i < k0; i++)
heap_push<C> (i+1, bh_val, bh_ids, x[i], i);
}
for (size_t i = k0; i < k; i++) {
bh_val[i] = C::neutral();
bh_ids[i] = -1;
}
}
template <typename T> inline
void minheap_heapify (size_t k, T * bh_val, int64_t * bh_ids, const T * x = nullptr,
const int64_t * ids = nullptr, size_t k0 = 0) {
heap_heapify< CMin<T, int64_t> > (k, bh_val, bh_ids, x, ids, k0);
}
template <typename T> inline
void maxheap_heapify (size_t k, T * bh_val, int64_t * bh_ids, const T * x = nullptr,
const int64_t * ids = nullptr, size_t k0 = 0) {
heap_heapify< CMax<T, int64_t> > (k, bh_val, bh_ids, x, ids, k0);
}
/*******************************************************************
* Add n elements to the heap
*******************************************************************/
/* Add some elements to the heap */
template <class C> inline
void heap_addn (size_t k, typename C::T * bh_val, typename C::TI * bh_ids,
const typename C::T * x, const typename C::TI * ids, size_t n) {
size_t i;
if (ids)
for (i = 0; i < n; i++) {
if (C::cmp (bh_val[0], x[i])) {
heap_pop<C> (k, bh_val, bh_ids);
heap_push<C> (k, bh_val, bh_ids, x[i], ids[i]);
}
} else
for (i = 0; i < n; i++) {
if (C::cmp (bh_val[0], x[i])) {
heap_pop<C> (k, bh_val, bh_ids);
heap_push<C> (k, bh_val, bh_ids, x[i], i);
}
}
}
/* Partial instanciation for heaps with TI = int64_t */
template <typename T> inline
void minheap_addn (size_t k, T * bh_val, int64_t * bh_ids, const T * x, const int64_t * ids, size_t n) {
heap_addn<CMin<T, int64_t> > (k, bh_val, bh_ids, x, ids, n);
}
template <typename T> inline
void maxheap_addn (size_t k, T * bh_val, int64_t * bh_ids, const T * x, const int64_t * ids, size_t n) {
heap_addn<CMax<T, int64_t> > (k, bh_val, bh_ids, x, ids, n);
}
/*******************************************************************
* Heap finalization (reorder elements)
*******************************************************************/
/* This function maps a binary heap into an sorted structure. It returns the number */
template <typename C> inline
size_t heap_reorder (size_t k, typename C::T * bh_val, typename C::TI * bh_ids) {
size_t i, ii;
for (i = 0, ii = 0; i < k; i++) {
/* top element should be put at the end of the list */
typename C::T val = bh_val[0];
typename C::TI id = bh_ids[0];
/* boundary case: we will over-ride this value if not a true element */
heap_pop<C> (k-i, bh_val, bh_ids);
bh_val[k-ii-1] = val;
bh_ids[k-ii-1] = id;
if (id != -1) ii++;
}
/* Count the number of elements which are effectively returned */
size_t nel = ii;
memmove (bh_val, bh_val+k-ii, ii * sizeof(*bh_val));
memmove (bh_ids, bh_ids+k-ii, ii * sizeof(*bh_ids));
for (; ii < k; ii++) {
bh_val[ii] = C::neutral();
bh_ids[ii] = -1;
}
return nel;
}
template <typename T> inline
size_t minheap_reorder (size_t k, T * bh_val, int64_t * bh_ids) {
return heap_reorder< CMin<T, int64_t> > (k, bh_val, bh_ids);
}
template <typename T> inline
size_t maxheap_reorder (size_t k, T * bh_val, int64_t * bh_ids) {
return heap_reorder< CMax<T, int64_t> > (k, bh_val, bh_ids);
}
/*******************************************************************
* Operations on heap arrays
*******************************************************************/
/** a template structure for a set of [min|max]-heaps it is tailored
* so that the actual data of the heaps can just live in compact arrays.
*/
template <typename C>
struct HeapArray {
typedef typename C::TI TI;
typedef typename C::T T;
size_t nh; ///< number of heaps
size_t k; ///< allocated size per heap
TI * ids; ///< identifiers (size nh * k)
T * val; ///< values (distances or similarities), size nh * k
/// Return the list of values for a heap
T * get_val (size_t key) { return val + key * k; }
/// Correspponding identifiers
TI * get_ids (size_t key) { return ids + key * k; }
/// prepare all the heaps before adding
void heapify ();
/** add nj elements to heaps i0:i0+ni, with sequential ids
*
* @param nj nb of elements to add to each heap
* @param vin elements to add, size ni * nj
* @param j0 add this to the ids that are added
* @param i0 first heap to update
* @param ni nb of elements to update (-1 = use nh)
*/
void addn (size_t nj, const T *vin, TI j0 = 0, size_t i0 = 0, int64_t ni = -1);
/** same as addn
*
* @param id_in ids of the elements to add, size ni * nj
* @param id_stride stride for id_in
*/
void addn_with_ids (size_t nj, const T *vin, const TI *id_in = nullptr,
int64_t id_stride = 0, size_t i0 = 0, int64_t ni = -1);
/// reorder all the heaps
void reorder ();
/** this is not really a heap function. It just finds the per-line
* extrema of each line of array D
* @param vals_out extreme value of each line (size nh, or NULL)
* @param idx_out index of extreme value (size nh or NULL)
*/
void per_line_extrema (T *vals_out, TI *idx_out) const;
};
/* Define useful heaps */
typedef HeapArray<CMin<float, int64_t> > float_minheap_array_t;
typedef HeapArray<CMin<int, int64_t> > int_minheap_array_t;
typedef HeapArray<CMax<float, int64_t> > float_maxheap_array_t;
typedef HeapArray<CMax<int, int64_t> > int_maxheap_array_t;
// The heap templates are instanciated explicitly in Heap.cpp
/*********************************************************************
* Indirect heaps: instead of having
* node i = (bh_ids[i], bh_val[i]),
* in indirect heaps,
* node i = (bh_ids[i], bh_val[bh_ids[i]]),
*********************************************************************/
template <class C>
inline void indirect_heap_pop ( size_t k, const typename C::T * bh_val, typename C::TI * bh_ids) {
bh_ids--; /* Use 1-based indexing for easier node->child translation */
typename C::T val = bh_val[bh_ids[k]];
size_t i = 1;
while (1) {
size_t i1 = i << 1;
size_t i2 = i1 + 1;
if (i1 > k)
break;
typename C::TI id1 = bh_ids[i1], id2 = bh_ids[i2];
if (i2 == k + 1 || C::cmp(bh_val[id1], bh_val[id2])) {
if (C::cmp(val, bh_val[id1]))
break;
bh_ids[i] = id1;
i = i1;
} else {
if (C::cmp(val, bh_val[id2]))
break;
bh_ids[i] = id2;
i = i2;
}
}
bh_ids[i] = bh_ids[k];
}
template <class C>
inline void indirect_heap_push (size_t k, const typename C::T * bh_val, typename C::TI * bh_ids, typename C::TI id) {
bh_ids--; /* Use 1-based indexing for easier node->child translation */
typename C::T val = bh_val[id];
size_t i = k;
while (i > 1) {
size_t i_father = i >> 1;
if (!C::cmp (val, bh_val[bh_ids[i_father]]))
break;
bh_ids[i] = bh_ids[i_father];
i = i_father;
}
bh_ids[i] = id;
}
} // namespace faiss
#endif /* FAISS_Heap_h */
3.1.2.2 Heap.cpp文件
/* Function for soft heap */
#include <faiss/utils/Heap.h>
namespace faiss {
template <typename C>
void HeapArray<C>::heapify () {
#pragma omp parallel for
for (size_t j = 0; j < nh; j++)
heap_heapify<C> (k, val + j * k, ids + j * k);
}
template <typename C>
void HeapArray<C>::reorder () {
#pragma omp parallel for
for (size_t j = 0; j < nh; j++)
heap_reorder<C> (k, val + j * k, ids + j * k);
}
template <typename C>
void HeapArray<C>::addn (size_t nj, const T *vin, TI j0, size_t i0, int64_t ni) {
if (ni == -1) ni = nh;
assert (i0 >= 0 && i0 + ni <= nh);
#pragma omp parallel for
for (size_t i = i0; i < i0 + ni; i++) {
T * __restrict simi = get_val(i);
TI * __restrict idxi = get_ids (i);
const T *ip_line = vin + (i - i0) * nj;
for (size_t j = 0; j < nj; j++) {
T ip = ip_line [j];
if (C::cmp(simi[0], ip)) {
heap_pop<C> (k, simi, idxi);
heap_push<C> (k, simi, idxi, ip, j + j0);
}
}
}
}
template <typename C>
void HeapArray<C>::addn_with_ids ( size_t nj, const T *vin, const TI *id_in, int64_t id_stride, size_t i0, int64_t ni) {
if (id_in == nullptr) {
addn (nj, vin, 0, i0, ni);
return;
}
if (ni == -1) ni = nh;
assert (i0 >= 0 && i0 + ni <= nh);
#pragma omp parallel for
for (size_t i = i0; i < i0 + ni; i++) {
T * __restrict simi = get_val(i);
TI * __restrict idxi = get_ids (i);
const T *ip_line = vin + (i - i0) * nj;
const TI *id_line = id_in + (i - i0) * id_stride;
for (size_t j = 0; j < nj; j++) {
T ip = ip_line [j];
if (C::cmp(simi[0], ip)) {
heap_pop<C> (k, simi, idxi);
heap_push<C> (k, simi, idxi, ip, id_line [j]);
}
}
}
}
template <typename C>
void HeapArray<C>::per_line_extrema ( T * out_val, TI * out_ids) const {
#pragma omp parallel for
for (size_t j = 0; j < nh; j++) {
int64_t imin = -1;
typename C::T xval = C::Crev::neutral ();
const typename C::T * x_ = val + j * k;
for (size_t i = 0; i < k; i++)
if (C::cmp (x_[i], xval)) {
xval = x_[i];
imin = i;
}
if (out_val)
out_val[j] = xval;
if (out_ids) {
if (ids && imin != -1)
out_ids[j] = ids [j * k + imin];
else
out_ids[j] = imin;
}
}
}
// explicit instanciations
template struct HeapArray<CMin <float, int64_t> >;
template struct HeapArray<CMax <float, int64_t> >;
template struct HeapArray<CMin <int, int64_t> >;
template struct HeapArray<CMax <int, int64_t> >;
} // END namespace fasis
3.1.2.3 test_heap.cpp文件
#include<cstdio>
#include<utils/Heap.h>
#include<utils/random.h>
void print_dis(float* array, int num){
printf("\t\tdis array is: ");
for(int i=0;i<num;i++){
printf("%f ", array[i]);
}
printf("\n");
}
void print_ids(int64_t* array, int num){
printf("\t\tids array is: ");
for(int i=0;i<num;i++){
printf("%ld ", array[i]);
}
printf("\n");
}
int main(){
int num=10;
float* dis =new float[num-1];
int64_t* ids = new int64_t[num-1];
float* new_dis =new float[num];
int64_t* new_ids = new int64_t[num];
for(int i=0;i<num-1;i++){
ids[i] =i;
faiss::float_rand(dis+i, 1, i+1);
}
print_dis(dis, num-1);
print_ids(ids, num-1);
printf("min heap: \n\tminheap_heapify:\n");
// 最小堆操作
faiss::minheap_heapify<float>(num, new_dis, new_ids, dis,ids,num-1);
print_dis(new_dis, num);
print_ids(new_ids, num);
printf("\tminheap_pop:\n");
faiss::minheap_pop<float>(num, new_dis, new_ids);
print_dis(new_dis, num);
print_ids(new_ids, num);
printf("\tminheap_push:\n");
faiss::minheap_push<float>(num, new_dis, new_ids, 0.1, 9);
print_dis(new_dis, num);
print_ids(new_ids, num);
delete [] dis;
delete [] ids;
delete [] new_dis;
delete [] new_ids;
return 0;
}
4.1.3 WorkerThread.h和WorkerThread.cpp文件
- WorkerThread.h文件
#pragma once
#include <condition_variable>
#include <future>
#include <deque>
#include <thread>
namespace faiss {
class WorkerThread {
public:
WorkerThread();
/// Stops and waits for the worker thread to exit, flushing all pending lambdas
~WorkerThread();
/// Request that the worker thread stop itself
void stop();
/// Blocking waits in the current thread for the worker thread to stop
void waitForThreadExit();
/// Adds a lambda to run on the worker thread; returns a future that
/// can be used to block on its completion.
/// Future status is `true` if the lambda was run in the worker
/// thread; `false` if it was not run, because the worker thread is
/// exiting or has exited.
std::future<bool> add(std::function<void()> f);
private:
void startThread();
void threadMain();
void threadLoop();
/// Thread that all queued lambdas are run on
std::thread thread_;
/// Mutex for the queue and exit status
std::mutex mutex_;
/// Monitor for the exit status and the queue
std::condition_variable monitor_;
/// Whether or not we want the thread to exit
bool wantStop_;
/// Queue of pending lambdas to call
std::deque<std::pair<std::function<void()>, std::promise<bool>>> queue_;
};
} // namespace
- WorkerThread.cpp文件
#include <faiss/utils/WorkerThread.h>
#include <faiss/impl/FaissAssert.h>
#include <exception>
namespace faiss {
namespace {
// Captures any exceptions thrown by the lambda and returns them via the promise
void runCallback(std::function<void()>& fn, std::promise<bool>& promise) {
try {
fn();
promise.set_value(true);
} catch (...) {
promise.set_exception(std::current_exception());
}
}
} // namespace
WorkerThread::WorkerThread() : wantStop_(false) {
startThread();
// Make sure that the thread has started before continuing
add([](){}).get();
}
WorkerThread::~WorkerThread() {
stop();
waitForThreadExit();
}
void WorkerThread::startThread() {
thread_ = std::thread([this](){ threadMain(); });
}
void WorkerThread::stop() {
std::lock_guard<std::mutex> guard(mutex_);
wantStop_ = true;
monitor_.notify_one();
}
std::future<bool> WorkerThread::add(std::function<void()> f) {
std::lock_guard<std::mutex> guard(mutex_);
if (wantStop_) {
// The timer thread has been stopped, or we want to stop; we can't schedule anything else
std::promise<bool> p;
auto fut = p.get_future();
// did not execute
p.set_value(false);
return fut;
}
auto pr = std::promise<bool>();
auto fut = pr.get_future();
queue_.emplace_back(std::make_pair(std::move(f), std::move(pr)));
// Wake up our thread
monitor_.notify_one();
return fut;
}
void WorkerThread::threadMain() {
threadLoop();
// Call all pending tasks
FAISS_ASSERT(wantStop_);
// flush all pending operations
for (auto& f : queue_) {
runCallback(f.first, f.second);
}
}
void WorkerThread::threadLoop() {
while (true) {
std::pair<std::function<void()>, std::promise<bool>> data;
{
std::unique_lock<std::mutex> lock(mutex_);
while (!wantStop_ && queue_.empty()) {
monitor_.wait(lock);
}
if (wantStop_) {
return;
}
data = std::move(queue_.front());
queue_.pop_front();
}
runCallback(data.first, data.second);
}
}
void WorkerThread::waitForThreadExit() {
try {
thread_.join();
} catch (...) {
}
}
} // namespace
4.1.4 distances.h、distances_simd.cpp和distances.cpp文件
此文件定义了相关距离
h、distances_simd.cpp文件定义了fvec_L2sqr(s-s向量L2距离),fvec_inner_product(s-s),fvec_L1,fvec_Linf,fvec_norm_L2sqr,fvec_L2sqr_ny(s-mL2距离)。
4.1.4.1 distances.h文件
/* All distance functions for L2 and IP distances.
* The actual functions are implemented in distances.cpp and distances_simd.cpp */
#pragma once
#include <stdint.h>
#include <faiss/utils/Heap.h>
namespace faiss {
/*********************************************************
* Optimized distance/norm/inner prod computations
*********************************************************/
/// Squared L2 distance between two vectors
float fvec_L2sqr ( const float * x, const float * y, size_t d);
/// inner product
float fvec_inner_product ( const float * x, const float * y, size_t d);
/// L1 distance
float fvec_L1 (const float * x, const float * y, size_t d);
float fvec_Linf (const float * x, const float * y, size_t d);
/** Compute pairwise distances between sets of vectors
*
* @param d dimension of the vectors
* @param nq nb of query vectors
* @param nb nb of database vectors
* @param xq query vectors (size nq * d)
* @param xb database vectros (size nb * d)
* @param dis output distances (size nq * nb)
* @param ldq,ldb, ldd strides for the matrices
*/
void pairwise_L2sqr (int64_t d, int64_t nq, const float *xq, int64_t nb,
const float *xb, float *dis, int64_t ldq = -1, int64_t ldb = -1, int64_t ldd = -1);
/* compute the inner product between nx vectors x and one y */
void fvec_inner_products_ny ( float * ip, /* output inner product */
const float * x, const float * y, size_t d, size_t ny);
/* compute ny square L2 distance bewteen x and a set of contiguous y vectors */
void fvec_L2sqr_ny ( float * dis, const float * x, const float * y, size_t d, size_t ny);
/** squared norm of a vector */
float fvec_norm_L2sqr (const float * x, size_t d);
/** compute the L2 norms for a set of vectors
*
* @param ip output norms, size nx
* @param x set of vectors, size nx * d
*/
void fvec_norms_L2 (float * ip, const float * x, size_t d, size_t nx);
/// same as fvec_norms_L2, but computes square norms
void fvec_norms_L2sqr (float * ip, const float * x, size_t d, size_t nx);
/* L2-renormalize a set of vector. Nothing done if the vector is 0-normed */
void fvec_renorm_L2 (size_t d, size_t nx, float * x);
/* This function exists because the Torch counterpart is extremly slow
(not multi-threaded + unexpected overhead even in single thread).
It is here to implement the usual property |x-y|^2=|x|^2+|y|^2-2<x|y> */
void inner_product_to_L2sqr (float * dis, const float * nr1, const float * nr2,size_t n1, size_t n2);
/***************************************************************************
* Compute a subset of distances
***************************************************************************/
/* compute the inner product between x and a subset y of ny vectors, whose indices are given by idy. */
void fvec_inner_products_by_idx (float * ip, const float * x, const float * y, const int64_t *ids, size_t d, size_t nx, size_t ny);
/* same but for a subset in y indexed by idsy (ny vectors in total) */
void fvec_L2sqr_by_idx ( float * dis, const float * x, const float * y, const int64_t *ids, /* ids of y vecs */
size_t d, size_t nx, size_t ny);
/** compute dis[j] = L2sqr(x[ix[j]], y[iy[j]]) forall j=0..n-1
*
* @param x size (max(ix) + 1, d)
* @param y size (max(iy) + 1, d)
* @param ix size n
* @param iy size n
* @param dis size n
*/
void pairwise_indexed_L2sqr (size_t d, size_t n, const float * x, const int64_t *ix,
const float * y, const int64_t *iy, float *dis);
/* same for inner product */
void pairwise_indexed_inner_product (size_t d, size_t n,const float * x, const int64_t *ix,
const float * y, const int64_t *iy,float *dis);
/***************************************************************************
* KNN functions
***************************************************************************/
// threshold on nx above which we switch to BLAS to compute distances
extern int distance_compute_blas_threshold;
/** Return the k nearest neighors of each of the nx vectors x among the ny
* vector y, w.r.t to max inner product
*
* @param x query vectors, size nx * d
* @param y database vectors, size ny * d
* @param res result array, which also provides k. Sorted on output
*/
void knn_inner_product (const float * x,const float * y,size_t d, size_t nx, size_t ny,float_minheap_array_t * res);
/** Same as knn_inner_product, for the L2 distance */
void knn_L2sqr (const float * x,const float * y,size_t d, size_t nx, size_t ny,float_maxheap_array_t * res);
/** same as knn_L2sqr, but base_shift[bno] is subtracted to all
* computed distances.
*
* @param base_shift size ny
*/
void knn_L2sqr_base_shift (const float * x, const float * y, size_t d, size_t nx,
size_t ny, float_maxheap_array_t * res, const float *base_shift);
/* Find the nearest neighbors for nx queries in a set of ny vectors
* indexed by ids. May be useful for re-ranking a pre-selected vector list
*/
void knn_inner_products_by_idx (const float * x,const float * y,const int64_t * ids,
size_t d, size_t nx, size_t ny,float_minheap_array_t * res);
void knn_L2sqr_by_idx (const float * x, const float * y, const int64_t * ids,
size_t d, size_t nx, size_t ny,float_maxheap_array_t * res);
/***************************************************************************
* Range search
***************************************************************************/
/// Forward declaration, see AuxIndexStructures.h
struct RangeSearchResult;
/** Return the k nearest neighors of each of the nx vectors x among the ny
* vector y, w.r.t to max inner product
*
* @param x query vectors, size nx * d
* @param y database vectors, size ny * d
* @param radius search radius around the x vectors
* @param result result structure
*/
void range_search_L2sqr (const float * x, const float * y,
size_t d, size_t nx, size_t ny,float radius, RangeSearchResult *result);
/// same as range_search_L2sqr for the inner product similarity
void range_search_inner_product (const float * x,const float * y,
size_t d, size_t nx, size_t ny,float radius, RangeSearchResult *result);
} // namespace faiss
4.1.4.2 distances_simd.cpp文件
#include <faiss/utils/distances.h>
#include <cstdio>
#include <cassert>
#include <cstring>
#include <cmath>
#ifdef __SSE__
#include <immintrin.h>
#endif
#ifdef __aarch64__
#include <arm_neon.h>
#endif
namespace faiss {
#ifdef __AVX__
#define USE_AVX
#endif
/*********************************************************
* Optimized distance computations
*********************************************************/
/* Functions to compute:
- L2 distance between 2 vectors
- inner product between 2 vectors
- L2 norm of a vector
The functions should probably not be invoked when a large number of
vectors are be processed in batch (in which case Matrix multiply
is faster), but may be useful for comparing vectors isolated in
memory.
Works with any vectors of any dimension, even unaligned (in which
case they are slower).
*/
/// Reference implementations
float fvec_L2sqr_ref (const float * x, const float * y, size_t d) {
size_t i;
float res = 0;
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += tmp * tmp;
}
return res;
}
float fvec_L1_ref (const float * x, const float * y, size_t d) {
size_t i;
float res = 0;
for (i = 0; i < d; i++) {
const float tmp = x[i] - y[i];
res += fabs(tmp);
}
return res;
}
float fvec_Linf_ref (const float * x,const float * y, size_t d) {
size_t i;
float res = 0;
for (i = 0; i < d; i++) {
res = fmax(res, fabs(x[i] - y[i]));
}
return res;
}
float fvec_inner_product_ref (const float * x, const float * y, size_t d) {
size_t i;
float res = 0;
for (i = 0; i < d; i++)
res += x[i] * y[i];
return res;
}
float fvec_norm_L2sqr_ref (const float *x, size_t d) {
size_t i;
double res = 0;
for (i = 0; i < d; i++)
res += x[i] * x[i];
return res;
}
void fvec_L2sqr_ny_ref (float * dis, const float * x, const float * y, size_t d, size_t ny) {
for (size_t i = 0; i < ny; i++) {
dis[i] = fvec_L2sqr (x, y, d);
y += d;
}
}
/* SSE and AVX implementations */
#ifdef __SSE__
// reads 0 <= d < 4 floats as __m128
static inline __m128 masked_read (int d, const float *x) {
assert (0 <= d && d < 4);
__attribute__((__aligned__(16))) float buf[4] = {0, 0, 0, 0};
switch (d) {
case 3:
buf[2] = x[2];
case 2:
buf[1] = x[1];
case 1:
buf[0] = x[0];
}
return _mm_load_ps (buf);
// cannot use AVX2 _mm_mask_set1_epi32
}
float fvec_norm_L2sqr (const float * x, size_t d) {
__m128 mx;
__m128 msum1 = _mm_setzero_ps();
while (d >= 4) {
mx = _mm_loadu_ps (x); x += 4;
msum1 = _mm_add_ps (msum1, _mm_mul_ps (mx, mx));
d -= 4;
}
mx = masked_read (d, x);
msum1 = _mm_add_ps (msum1, _mm_mul_ps (mx, mx));
msum1 = _mm_hadd_ps (msum1, msum1);
msum1 = _mm_hadd_ps (msum1, msum1);
return _mm_cvtss_f32 (msum1);
}
namespace {
float sqr (float x) { return x * x; }
void fvec_L2sqr_ny_D1 (float * dis, const float * x, const float * y, size_t ny) {
float x0s = x[0];
__m128 x0 = _mm_set_ps (x0s, x0s, x0s, x0s);
size_t i;
for (i = 0; i + 3 < ny; i += 4) {
__m128 tmp, accu;
tmp = x0 - _mm_loadu_ps (y); y += 4;
accu = tmp * tmp;
dis[i] = _mm_cvtss_f32 (accu);
tmp = _mm_shuffle_ps (accu, accu, 1);
dis[i + 1] = _mm_cvtss_f32 (tmp);
tmp = _mm_shuffle_ps (accu, accu, 2);
dis[i + 2] = _mm_cvtss_f32 (tmp);
tmp = _mm_shuffle_ps (accu, accu, 3);
dis[i + 3] = _mm_cvtss_f32 (tmp);
}
while (i < ny) { // handle non-multiple-of-4 case
dis[i++] = sqr(x0s - *y++);
}
}
void fvec_L2sqr_ny_D2 (float * dis, const float * x, const float * y, size_t ny) {
__m128 x0 = _mm_set_ps (x[1], x[0], x[1], x[0]);
size_t i;
for (i = 0; i + 1 < ny; i += 2) {
__m128 tmp, accu;
tmp = x0 - _mm_loadu_ps (y); y += 4;
accu = tmp * tmp;
accu = _mm_hadd_ps (accu, accu);
dis[i] = _mm_cvtss_f32 (accu);
accu = _mm_shuffle_ps (accu, accu, 3);
dis[i + 1] = _mm_cvtss_f32 (accu);
}
if (i < ny) { // handle odd case
dis[i] = sqr(x[0] - y[0]) + sqr(x[1] - y[1]);
}
}
void fvec_L2sqr_ny_D4 (float * dis, const float * x,const float * y, size_t ny){
__m128 x0 = _mm_loadu_ps(x);
for (size_t i = 0; i < ny; i++) {
__m128 tmp, accu;
tmp = x0 - _mm_loadu_ps (y); y += 4;
accu = tmp * tmp;
accu = _mm_hadd_ps (accu, accu);
accu = _mm_hadd_ps (accu, accu);
dis[i] = _mm_cvtss_f32 (accu);
}
}
void fvec_L2sqr_ny_D8 (float * dis, const float * x, const float * y, size_t ny) {
__m128 x0 = _mm_loadu_ps(x);
__m128 x1 = _mm_loadu_ps(x + 4);
for (size_t i = 0; i < ny; i++) {
__m128 tmp, accu;
tmp = x0 - _mm_loadu_ps (y); y += 4;
accu = tmp * tmp;
tmp = x1 - _mm_loadu_ps (y); y += 4;
accu += tmp * tmp;
accu = _mm_hadd_ps (accu, accu);
accu = _mm_hadd_ps (accu, accu);
dis[i] = _mm_cvtss_f32 (accu);
}
}
void fvec_L2sqr_ny_D12 (float * dis, const float * x, const float * y, size_t ny) {
__m128 x0 = _mm_loadu_ps(x);
__m128 x1 = _mm_loadu_ps(x + 4);
__m128 x2 = _mm_loadu_ps(x + 8);
for (size_t i = 0; i < ny; i++) {
__m128 tmp, accu;
tmp = x0 - _mm_loadu_ps (y); y += 4;
accu = tmp * tmp;
tmp = x1 - _mm_loadu_ps (y); y += 4;
accu += tmp * tmp;
tmp = x2 - _mm_loadu_ps (y); y += 4;
accu += tmp * tmp;
accu = _mm_hadd_ps (accu, accu);
accu = _mm_hadd_ps (accu, accu);
dis[i] = _mm_cvtss_f32 (accu);
}
}
} // anonymous namespace
void fvec_L2sqr_ny (float * dis, const float * x, const float * y, size_t d, size_t ny) {
// optimized for a few special cases
switch(d) {
case 1:
fvec_L2sqr_ny_D1 (dis, x, y, ny);
return;
case 2:
fvec_L2sqr_ny_D2 (dis, x, y, ny);
return;
case 4:
fvec_L2sqr_ny_D4 (dis, x, y, ny);
return;
case 8:
fvec_L2sqr_ny_D8 (dis, x, y, ny);
return;
case 12:
fvec_L2sqr_ny_D12 (dis, x, y, ny);
return;
default:
fvec_L2sqr_ny_ref (dis, x, y, d, ny);
return;
}
}
#endif
#ifdef USE_AVX
// reads 0 <= d < 8 floats as __m256
static inline __m256 masked_read_8 (int d, const float *x) {
assert (0 <= d && d < 8);
if (d < 4) {
__m256 res = _mm256_setzero_ps ();
res = _mm256_insertf128_ps (res, masked_read (d, x), 0);
return res;
} else {
__m256 res = _mm256_setzero_ps ();
res = _mm256_insertf128_ps (res, _mm_loadu_ps (x), 0);
res = _mm256_insertf128_ps (res, masked_read (d - 4, x + 4), 1);
return res;
}
}
float fvec_inner_product (const float * x,const float * y, size_t d){
__m256 msum1 = _mm256_setzero_ps();
while (d >= 8) {
__m256 mx = _mm256_loadu_ps (x); x += 8;
__m256 my = _mm256_loadu_ps (y); y += 8;
msum1 = _mm256_add_ps (msum1, _mm256_mul_ps (mx, my));
d -= 8;
}
__m128 msum2 = _mm256_extractf128_ps(msum1, 1);
msum2 += _mm256_extractf128_ps(msum1, 0);
if (d >= 4) {
__m128 mx = _mm_loadu_ps (x); x += 4;
__m128 my = _mm_loadu_ps (y); y += 4;
msum2 = _mm_add_ps (msum2, _mm_mul_ps (mx, my));
d -= 4;
}
if (d > 0) {
__m128 mx = masked_read (d, x);
__m128 my = masked_read (d, y);
msum2 = _mm_add_ps (msum2, _mm_mul_ps (mx, my));
}
msum2 = _mm_hadd_ps (msum2, msum2);
msum2 = _mm_hadd_ps (msum2, msum2);
return _mm_cvtss_f32 (msum2);
}
float fvec_L2sqr (const float * x, const float * y, size_t d) {
__m256 msum1 = _mm256_setzero_ps();
while (d >= 8) {
__m256 mx = _mm256_loadu_ps (x); x += 8;
__m256 my = _mm256_loadu_ps (y); y += 8;
const __m256 a_m_b1 = mx - my;
msum1 += a_m_b1 * a_m_b1;
d -= 8;
}
__m128 msum2 = _mm256_extractf128_ps(msum1, 1);
msum2 += _mm256_extractf128_ps(msum1, 0);
if (d >= 4) {
__m128 mx = _mm_loadu_ps (x); x += 4;
__m128 my = _mm_loadu_ps (y); y += 4;
const __m128 a_m_b1 = mx - my;
msum2 += a_m_b1 * a_m_b1;
d -= 4;
}
if (d > 0) {
__m128 mx = masked_read (d, x);
__m128 my = masked_read (d, y);
__m128 a_m_b1 = mx - my;
msum2 += a_m_b1 * a_m_b1;
}
msum2 = _mm_hadd_ps (msum2, msum2);
msum2 = _mm_hadd_ps (msum2, msum2);
return _mm_cvtss_f32 (msum2);
}
float fvec_L1 (const float * x, const float * y, size_t d) {
__m256 msum1 = _mm256_setzero_ps();
__m256 signmask = __m256(_mm256_set1_epi32 (0x7fffffffUL));
while (d >= 8) {
__m256 mx = _mm256_loadu_ps (x); x += 8;
__m256 my = _mm256_loadu_ps (y); y += 8;
const __m256 a_m_b = mx - my;
msum1 += _mm256_and_ps(signmask, a_m_b);
d -= 8;
}
__m128 msum2 = _mm256_extractf128_ps(msum1, 1);
msum2 += _mm256_extractf128_ps(msum1, 0);
__m128 signmask2 = __m128(_mm_set1_epi32 (0x7fffffffUL));
if (d >= 4) {
__m128 mx = _mm_loadu_ps (x); x += 4;
__m128 my = _mm_loadu_ps (y); y += 4;
const __m128 a_m_b = mx - my;
msum2 += _mm_and_ps(signmask2, a_m_b);
d -= 4;
}
if (d > 0) {
__m128 mx = masked_read (d, x);
__m128 my = masked_read (d, y);
__m128 a_m_b = mx - my;
msum2 += _mm_and_ps(signmask2, a_m_b);
}
msum2 = _mm_hadd_ps (msum2, msum2);
msum2 = _mm_hadd_ps (msum2, msum2);
return _mm_cvtss_f32 (msum2);
}
float fvec_Linf (const float * x, const float * y, size_t d) {
__m256 msum1 = _mm256_setzero_ps();
__m256 signmask = __m256(_mm256_set1_epi32 (0x7fffffffUL));
while (d >= 8) {
__m256 mx = _mm256_loadu_ps (x); x += 8;
__m256 my = _mm256_loadu_ps (y); y += 8;
const __m256 a_m_b = mx - my;
msum1 = _mm256_max_ps(msum1, _mm256_and_ps(signmask, a_m_b));
d -= 8;
}
__m128 msum2 = _mm256_extractf128_ps(msum1, 1);
msum2 = _mm_max_ps (msum2, _mm256_extractf128_ps(msum1, 0));
__m128 signmask2 = __m128(_mm_set1_epi32 (0x7fffffffUL));
if (d >= 4) {
__m128 mx = _mm_loadu_ps (x); x += 4;
__m128 my = _mm_loadu_ps (y); y += 4;
const __m128 a_m_b = mx - my;
msum2 = _mm_max_ps(msum2, _mm_and_ps(signmask2, a_m_b));
d -= 4;
}
if (d > 0) {
__m128 mx = masked_read (d, x);
__m128 my = masked_read (d, y);
__m128 a_m_b = mx - my;
msum2 = _mm_max_ps(msum2, _mm_and_ps(signmask2, a_m_b));
}
msum2 = _mm_max_ps(_mm_movehl_ps(msum2, msum2), msum2);
msum2 = _mm_max_ps(msum2, _mm_shuffle_ps (msum2, msum2, 1));
return _mm_cvtss_f32 (msum2);
}
#elif defined(__SSE__) // But not AVX
float fvec_L1 (const float * x, const float * y, size_t d) {
return fvec_L1_ref (x, y, d);
}
float fvec_Linf (const float * x, const float * y, size_t d) {
return fvec_Linf_ref (x, y, d);
}
float fvec_L2sqr (const float * x, const float * y, size_t d) {
__m128 msum1 = _mm_setzero_ps();
while (d >= 4) {
__m128 mx = _mm_loadu_ps (x); x += 4;
__m128 my = _mm_loadu_ps (y); y += 4;
const __m128 a_m_b1 = mx - my;
msum1 += a_m_b1 * a_m_b1;
d -= 4;
}
if (d > 0) {
// add the last 1, 2 or 3 values
__m128 mx = masked_read (d, x);
__m128 my = masked_read (d, y);
__m128 a_m_b1 = mx - my;
msum1 += a_m_b1 * a_m_b1;
}
msum1 = _mm_hadd_ps (msum1, msum1);
msum1 = _mm_hadd_ps (msum1, msum1);
return _mm_cvtss_f32 (msum1);
}
float fvec_inner_product (const float * x,const float * y, size_t d){
__m128 mx, my;
__m128 msum1 = _mm_setzero_ps();
while (d >= 4) {
mx = _mm_loadu_ps (x); x += 4;
my = _mm_loadu_ps (y); y += 4;
msum1 = _mm_add_ps (msum1, _mm_mul_ps (mx, my));
d -= 4;
}
// add the last 1, 2, or 3 values
mx = masked_read (d, x);
my = masked_read (d, y);
__m128 prod = _mm_mul_ps (mx, my);
msum1 = _mm_add_ps (msum1, prod);
msum1 = _mm_hadd_ps (msum1, msum1);
msum1 = _mm_hadd_ps (msum1, msum1);
return _mm_cvtss_f32 (msum1);
}
#elif defined(__aarch64__)
float fvec_L2sqr (const float * x, const float * y, size_t d) {
if (d & 3) return fvec_L2sqr_ref (x, y, d);
float32x4_t accu = vdupq_n_f32 (0);
for (size_t i = 0; i < d; i += 4) {
float32x4_t xi = vld1q_f32 (x + i);
float32x4_t yi = vld1q_f32 (y + i);
float32x4_t sq = vsubq_f32 (xi, yi);
accu = vfmaq_f32 (accu, sq, sq);
}
float32x4_t a2 = vpaddq_f32 (accu, accu);
return vdups_laneq_f32 (a2, 0) + vdups_laneq_f32 (a2, 1);
}
float fvec_inner_product (const float * x, const float * y, size_t d) {
if (d & 3) return fvec_inner_product_ref (x, y, d);
float32x4_t accu = vdupq_n_f32 (0);
for (size_t i = 0; i < d; i += 4) {
float32x4_t xi = vld1q_f32 (x + i);
float32x4_t yi = vld1q_f32 (y + i);
accu = vfmaq_f32 (accu, xi, yi);
}
float32x4_t a2 = vpaddq_f32 (accu, accu);
return vdups_laneq_f32 (a2, 0) + vdups_laneq_f32 (a2, 1);
}
float fvec_norm_L2sqr (const float *x, size_t d) {
if (d & 3) return fvec_norm_L2sqr_ref (x, d);
float32x4_t accu = vdupq_n_f32 (0);
for (size_t i = 0; i < d; i += 4) {
float32x4_t xi = vld1q_f32 (x + i);
accu = vfmaq_f32 (accu, xi, xi);
}
float32x4_t a2 = vpaddq_f32 (accu, accu);
return vdups_laneq_f32 (a2, 0) + vdups_laneq_f32 (a2, 1);
}
// not optimized for ARM
void fvec_L2sqr_ny (float * dis, const float * x, const float * y, size_t d, size_t ny) {
fvec_L2sqr_ny_ref (dis, x, y, d, ny);
}
float fvec_L1 (const float * x, const float * y, size_t d) {
return fvec_L1_ref (x, y, d);
}
float fvec_Linf (const float * x, const float * y, size_t d) {
return fvec_Linf_ref (x, y, d);
}
#else
// scalar implementation
float fvec_L2sqr (const float * x,const float * y,size_t d){
return fvec_L2sqr_ref (x, y, d);
}
float fvec_L1 (const float * x, const float * y, size_t d){
return fvec_L1_ref (x, y, d);
}
float fvec_Linf (const float * x, const float * y, size_t d) {
return fvec_Linf_ref (x, y, d);
}
float fvec_inner_product (const float * x, const float * y,size_t d) {
return fvec_inner_product_ref (x, y, d);
}
float fvec_norm_L2sqr (const float *x, size_t d) {
return fvec_norm_L2sqr_ref (x, d);
}
void fvec_L2sqr_ny (float * dis, const float * x, const float * y, size_t d, size_t ny) {
fvec_L2sqr_ny_ref (dis, x, y, d, ny);
}
#endif
/***************************************************************************
* heavily optimized table computations
***************************************************************************/
static inline void fvec_madd_ref (size_t n, const float *a, float bf, const float *b, float *c) {
for (size_t i = 0; i < n; i++)
c[i] = a[i] + bf * b[i];
}
#ifdef __SSE__
static inline void fvec_madd_sse (size_t n, const float *a,float bf, const float *b, float *c) {
n >>= 2;
__m128 bf4 = _mm_set_ps1 (bf);
__m128 * a4 = (__m128*)a;
__m128 * b4 = (__m128*)b;
__m128 * c4 = (__m128*)c;
while (n--) {
*c4 = _mm_add_ps (*a4, _mm_mul_ps (bf4, *b4));
b4++;
a4++;
c4++;
}
}
void fvec_madd (size_t n, const float *a, float bf, const float *b, float *c) {
if ((n & 3) == 0 && ((((long)a) | ((long)b) | ((long)c)) & 15) == 0)
fvec_madd_sse (n, a, bf, b, c);
else
fvec_madd_ref (n, a, bf, b, c);
}
#else
void fvec_madd (size_t n, const float *a, float bf, const float *b, float *c) {
fvec_madd_ref (n, a, bf, b, c);
}
#endif
static inline int fvec_madd_and_argmin_ref (size_t n, const float *a, float bf, const float *b, float *c) {
float vmin = 1e20;
int imin = -1;
for (size_t i = 0; i < n; i++) {
c[i] = a[i] + bf * b[i];
if (c[i] < vmin) {
vmin = c[i];
imin = i;
}
}
return imin;
}
#ifdef __SSE__
static inline int fvec_madd_and_argmin_sse (size_t n, const float *a,float bf, const float *b, float *c) {
n >>= 2;
__m128 bf4 = _mm_set_ps1 (bf);
__m128 vmin4 = _mm_set_ps1 (1e20);
__m128i imin4 = _mm_set1_epi32 (-1);
__m128i idx4 = _mm_set_epi32 (3, 2, 1, 0);
__m128i inc4 = _mm_set1_epi32 (4);
__m128 * a4 = (__m128*)a;
__m128 * b4 = (__m128*)b;
__m128 * c4 = (__m128*)c;
while (n--) {
__m128 vc4 = _mm_add_ps (*a4, _mm_mul_ps (bf4, *b4));
*c4 = vc4;
__m128i mask = (__m128i)_mm_cmpgt_ps (vmin4, vc4);
// imin4 = _mm_blendv_epi8 (imin4, idx4, mask); // slower!
imin4 = _mm_or_si128 (_mm_and_si128 (mask, idx4), _mm_andnot_si128 (mask, imin4));
vmin4 = _mm_min_ps (vmin4, vc4);
b4++;
a4++;
c4++;
idx4 = _mm_add_epi32 (idx4, inc4);
}
// 4 values -> 2
{
idx4 = _mm_shuffle_epi32 (imin4, 3 << 2 | 2);
__m128 vc4 = _mm_shuffle_ps (vmin4, vmin4, 3 << 2 | 2);
__m128i mask = (__m128i)_mm_cmpgt_ps (vmin4, vc4);
imin4 = _mm_or_si128 (_mm_and_si128 (mask, idx4),
_mm_andnot_si128 (mask, imin4));
vmin4 = _mm_min_ps (vmin4, vc4);
}
// 2 values -> 1
{
idx4 = _mm_shuffle_epi32 (imin4, 1);
__m128 vc4 = _mm_shuffle_ps (vmin4, vmin4, 1);
__m128i mask = (__m128i)_mm_cmpgt_ps (vmin4, vc4);
imin4 = _mm_or_si128 (_mm_and_si128 (mask, idx4),
_mm_andnot_si128 (mask, imin4));
// vmin4 = _mm_min_ps (vmin4, vc4);
}
return _mm_cvtsi128_si32 (imin4);
}
int fvec_madd_and_argmin (size_t n, const float *a, float bf, const float *b, float *c) {
if ((n & 3) == 0 &&
((((long)a) | ((long)b) | ((long)c)) & 15) == 0)
return fvec_madd_and_argmin_sse (n, a, bf, b, c);
else
return fvec_madd_and_argmin_ref (n, a, bf, b, c);
}
#else
int fvec_madd_and_argmin (size_t n, const float *a,float bf, const float *b, float *c) {
return fvec_madd_and_argmin_ref (n, a, bf, b, c);
}
#endif
} // namespace faiss
4.1.4.1 distances.cpp文件
4.1.5 utils.h和utils.cpp文件
4.1.5.1 utils.h文件
/* A few utilitary functions for similarity search:
* - optimized exhaustive distance and knn search functions
* - some functions reimplemented from torch for speed
*/
#ifndef FAISS_utils_h
#define FAISS_utils_h
#include <stdint.h>
#include <utils/Heap.h>
namespace faiss {
/**************************************************
* Get some stats about the system
**************************************************/
/// ms elapsed since some arbitrary epoch
double getmillisecs ();
/// get current RSS usage in kB
size_t get_mem_usage_kb ();
uint64_t get_cycles ();
/***************************************************************************
* Misc matrix and vector manipulation functions
***************************************************************************/
/** compute c := a + bf * b for a, b and c tables
*
* @param n size of the tables
* @param a size n
* @param b size n
* @param c restult table, size n
*/
void fvec_madd (size_t n, const float *a, float bf, const float *b, float *c);
/** same as fvec_madd, also return index of the min of the result table
* @return index of the min of table c
*/
int fvec_madd_and_argmin (size_t n, const float *a, float bf, const float *b, float *c);
/* perform a reflection (not an efficient implementation, just for test ) */
void reflection (const float * u, float * x, size_t n, size_t d, size_t nu);
/** compute the Q of the QR decomposition for m > n
* @param a size n * m: input matrix and output Q
*/
void matrix_qr (int m, int n, float *a);
/** distances are supposed to be sorted. Sorts indices with same distance*/
void ranklist_handle_ties (int k, int64_t *idx, const float *dis);
/** count the number of comon elements between v1 and v2
* algorithm = sorting + bissection to avoid double-counting duplicates
*/
size_t ranklist_intersection_size (size_t k1, const int64_t *v1, size_t k2, const int64_t *v2);
/** merge a result table into another one
*
* @param I0, D0 first result table, size (n, k)
* @param I1, D1 second result table, size (n, k)
* @param keep_min if true, keep min values, otherwise keep max
* @param translation add this value to all I1's indexes
* @return nb of values that were taken from the second table
*/
size_t merge_result_table_with (size_t n, size_t k, int64_t *I0, float *D0, const int64_t *I1,
const float *D1, bool keep_min = true, int64_t translation = 0);
/// a balanced assignment has a IF of 1
double imbalance_factor (int n, int k, const int64_t *assign);
/// same, takes a histogram as input
double imbalance_factor (int k, const int *hist);
void fvec_argsort (size_t n, const float *vals, size_t *perm);
void fvec_argsort_parallel (size_t n, const float *vals, size_t *perm);
/// compute histogram on v
int ivec_hist (size_t n, const int * v, int vmax, int *hist);
/** Compute histogram of bits on a code array
*
* @param codes size(n, nbits / 8)
* @param hist size(nbits): nb of 1s in the array of codes
*/
void bincode_hist(size_t n, size_t nbits, const uint8_t *codes, int *hist);
/// compute a checksum on a table.
size_t ivec_checksum (size_t n, const int *a);
/** random subsamples a set of vectors if there are too many of them
*
* @param d dimension of the vectors
* @param n on input: nb of input vectors, output: nb of output vectors
* @param nmax max nb of vectors to keep
* @param x input array, size *n-by-d
* @param seed random seed to use for sampling
* @return x or an array allocated with new [] with *n vectors
*/
const float *fvecs_maybe_subsample ( size_t d, size_t *n, size_t nmax, const float *x,
bool verbose = false, int64_t seed = 1234);
/** Convert binary vector to +1/-1 valued float vector.
*
* @param d dimension of the vector (multiple of 8)
* @param x_in input binary vector (uint8_t table of size d / 8)
* @param x_out output float vector (float table of size d)
*/
void binary_to_real(size_t d, const uint8_t *x_in, float *x_out);
/** Convert float vector to binary vector. Components > 0 are converted to 1,
* others to 0.
*
* @param d dimension of the vector (multiple of 8)
* @param x_in input float vector (float table of size d)
* @param x_out output binary vector (uint8_t table of size d / 8)
*/
void real_to_binary(size_t d, const float *x_in, uint8_t *x_out);
/** A reasonable hashing function */
uint64_t hash_bytes (const uint8_t *bytes, int64_t n);
/** Whether OpenMP annotations were respected. */
bool check_openmp();
} // namspace faiss
#endif /* FAISS_utils_h */
4.1.5.1 utils.cpp文件
#include <utils/utils.h>
#include <cstdio>
#include <cassert>
#include <cstring>
#include <cmath>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
#include <omp.h>
#include <algorithm>
#include <vector>
#include <impl/AuxIndexStructures.h>
#include <impl/FaissAssert.h>
#include <utils/random.h>
#ifndef FINTEGER
#define FINTEGER long
#endif
extern "C" {
/* declare BLAS functions, see http://www.netlib.org/clapack/cblas/ */
int sgemm_ (const char *transa, const char *transb, FINTEGER *m, FINTEGER *
n, FINTEGER *k, const float *alpha, const float *a,
FINTEGER *lda, const float *b, FINTEGER *
ldb, float *beta, float *c, FINTEGER *ldc);
/* Lapack functions, see http://www.netlib.org/clapack/old/single/sgeqrf.c */
int sgeqrf_ (FINTEGER *m, FINTEGER *n, float *a, FINTEGER *lda,
float *tau, float *work, FINTEGER *lwork, FINTEGER *info);
int sorgqr_(FINTEGER *m, FINTEGER *n, FINTEGER *k, float *a,
FINTEGER *lda, float *tau, float *work,
FINTEGER *lwork, FINTEGER *info);
int sgemv_(const char *trans, FINTEGER *m, FINTEGER *n, float *alpha,
const float *a, FINTEGER *lda, const float *x, FINTEGER *incx,
float *beta, float *y, FINTEGER *incy);
}
/**************************************************
* Get some stats about the system
**************************************************/
namespace faiss {
double getmillisecs () {
struct timeval tv;
gettimeofday (&tv, nullptr);
return tv.tv_sec * 1e3 + tv.tv_usec * 1e-3;
}
uint64_t get_cycles () {
#ifdef __x86_64__
uint32_t high, low;
asm volatile("rdtsc \n\t":"=a" (low),"=d" (high));
return ((uint64_t)high << 32) | (low);
#else
return 0;
#endif
}
#ifdef __linux__
size_t get_mem_usage_kb () {
int pid = getpid ();
char fname[256];
snprintf (fname, 256, "/proc/%d/status", pid);
FILE * f = fopen (fname, "r");
FAISS_THROW_IF_NOT_MSG (f, "cannot open proc status file");
size_t sz = 0;
for (;;) {
char buf [256];
if (!fgets (buf, 256, f)) break;
if (sscanf (buf, "VmRSS: %ld kB", &sz) == 1) break;
}
fclose (f);
return sz;
}
#elif __APPLE__
size_t get_mem_usage_kb () {
fprintf(stderr, "WARN: get_mem_usage_kb not implemented on the mac\n");
return 0;
}
#endif
void reflection (const float * __restrict u, float * __restrict x, size_t n, size_t d, size_t nu) {
size_t i, j, l;
for (i = 0; i < n; i++) {
const float * up = u;
for (l = 0; l < nu; l++) {
float ip1 = 0, ip2 = 0;
for (j = 0; j < d; j+=2) {
ip1 += up[j] * x[j];
ip2 += up[j+1] * x[j+1];
}
float ip = 2 * (ip1 + ip2);
for (j = 0; j < d; j++)
x[j] -= ip * up[j];
up += d;
}
x += d;
}
}
/* Reference implementation (slower) */
void reflection_ref (const float * u, float * x, size_t n, size_t d, size_t nu) {
size_t i, j, l;
for (i = 0; i < n; i++) {
const float * up = u;
for (l = 0; l < nu; l++) {
double ip = 0;
for (j = 0; j < d; j++)
ip += up[j] * x[j];
ip *= 2;
for (j = 0; j < d; j++)
x[j] -= ip * up[j];
up += d;
}
x += d;
}
}
/***************************************************************************
* Some matrix manipulation functions
***************************************************************************/
/* This function exists because the Torch counterpart is extremly slow
(not multi-threaded + unexpected overhead even in single thread).
It is here to implement the usual property |x-y|^2=|x|^2+|y|^2-2<x|y> */
void inner_product_to_L2sqr (float * __restrict dis, const float * nr1, const float * nr2, size_t n1, size_t n2) {
#pragma omp parallel for
for (size_t j = 0 ; j < n1 ; j++) {
float * disj = dis + j * n2;
for (size_t i = 0 ; i < n2 ; i++)
disj[i] = nr1[j] + nr2[i] - 2 * disj[i];
}
}
void matrix_qr (int m, int n, float *a) {
FAISS_THROW_IF_NOT (m >= n);
FINTEGER mi = m, ni = n, ki = mi < ni ? mi : ni;
std::vector<float> tau (ki);
FINTEGER lwork = -1, info;
float work_size;
sgeqrf_ (&mi, &ni, a, &mi, tau.data(), &work_size, &lwork, &info);
lwork = size_t(work_size);
std::vector<float> work (lwork);
sgeqrf_ (&mi, &ni, a, &mi, tau.data(), work.data(), &lwork, &info);
sorgqr_ (&mi, &ni, &ki, a, &mi, tau.data(), work.data(), &lwork, &info);
}
/***************************************************************************
* Result list routines
***************************************************************************/
void ranklist_handle_ties (int k, int64_t *idx, const float *dis) {
float prev_dis = -1e38;
int prev_i = -1;
for (int i = 0; i < k; i++) {
if (dis[i] != prev_dis) {
if (i > prev_i + 1) {
// sort between prev_i and i - 1
std::sort (idx + prev_i, idx + i);
}
prev_i = i;
prev_dis = dis[i];
}
}
}
size_t merge_result_table_with (size_t n, size_t k, int64_t *I0, float *D0, const int64_t *I1, const float *D1,
bool keep_min, int64_t translation) {
size_t n1 = 0;
#pragma omp parallel reduction(+:n1)
{
std::vector<int64_t> tmpI (k);
std::vector<float> tmpD (k);
#pragma omp for
for (size_t i = 0; i < n; i++) {
int64_t *lI0 = I0 + i * k;
float *lD0 = D0 + i * k;
const int64_t *lI1 = I1 + i * k;
const float *lD1 = D1 + i * k;
size_t r0 = 0;
size_t r1 = 0;
if (keep_min) {
for (size_t j = 0; j < k; j++) {
if (lI0[r0] >= 0 && lD0[r0] < lD1[r1]) {
tmpD[j] = lD0[r0];
tmpI[j] = lI0[r0];
r0++;
} else if (lD1[r1] >= 0) {
tmpD[j] = lD1[r1];
tmpI[j] = lI1[r1] + translation;
r1++;
} else { // both are NaNs
tmpD[j] = NAN;
tmpI[j] = -1;
}
}
} else {
for (size_t j = 0; j < k; j++) {
if (lI0[r0] >= 0 && lD0[r0] > lD1[r1]) {
tmpD[j] = lD0[r0];
tmpI[j] = lI0[r0];
r0++;
} else if (lD1[r1] >= 0) {
tmpD[j] = lD1[r1];
tmpI[j] = lI1[r1] + translation;
r1++;
} else { // both are NaNs
tmpD[j] = NAN;
tmpI[j] = -1;
}
}
}
n1 += r1;
memcpy (lD0, tmpD.data(), sizeof (lD0[0]) * k);
memcpy (lI0, tmpI.data(), sizeof (lI0[0]) * k);
}
}
return n1;
}
size_t ranklist_intersection_size (size_t k1, const int64_t *v1, size_t k2, const int64_t *v2_in) {
if (k2 > k1) return ranklist_intersection_size (k2, v2_in, k1, v1);
int64_t *v2 = new int64_t [k2];
memcpy (v2, v2_in, sizeof (int64_t) * k2);
std::sort (v2, v2 + k2);
{ // de-dup v2
int64_t prev = -1;
size_t wp = 0;
for (size_t i = 0; i < k2; i++) {
if (v2 [i] != prev) {
v2[wp++] = prev = v2 [i];
}
}
k2 = wp;
}
const int64_t seen_flag = 1L << 60;
size_t count = 0;
for (size_t i = 0; i < k1; i++) {
int64_t q = v1 [i];
size_t i0 = 0, i1 = k2;
while (i0 + 1 < i1) {
size_t imed = (i1 + i0) / 2;
int64_t piv = v2 [imed] & ~seen_flag;
if (piv <= q) i0 = imed;
else i1 = imed;
}
if (v2 [i0] == q) {
count++;
v2 [i0] |= seen_flag;
}
}
delete [] v2;
return count;
}
double imbalance_factor (int k, const int *hist) {
double tot = 0, uf = 0;
for (int i = 0 ; i < k ; i++) {
tot += hist[i];
uf += hist[i] * (double) hist[i];
}
uf = uf * k / (tot * tot);
return uf;
}
double imbalance_factor (int n, int k, const int64_t *assign) {
std::vector<int> hist(k, 0);
for (int i = 0; i < n; i++) {
hist[assign[i]]++;
}
return imbalance_factor (k, hist.data());
}
int ivec_hist (size_t n, const int * v, int vmax, int *hist) {
memset (hist, 0, sizeof(hist[0]) * vmax);
int nout = 0;
while (n--) {
if (v[n] < 0 || v[n] >= vmax) nout++;
else hist[v[n]]++;
}
return nout;
}
void bincode_hist(size_t n, size_t nbits, const uint8_t *codes, int *hist) {
FAISS_THROW_IF_NOT (nbits % 8 == 0);
size_t d = nbits / 8;
std::vector<int> accu(d * 256);
const uint8_t *c = codes;
for (size_t i = 0; i < n; i++)
for(int j = 0; j < d; j++)
accu[j * 256 + *c++]++;
memset (hist, 0, sizeof(*hist) * nbits);
for (int i = 0; i < d; i++) {
const int *ai = accu.data() + i * 256;
int * hi = hist + i * 8;
for (int j = 0; j < 256; j++)
for (int k = 0; k < 8; k++)
if ((j >> k) & 1)
hi[k] += ai[j];
}
}
size_t ivec_checksum (size_t n, const int *a) {
size_t cs = 112909;
while (n--) cs = cs * 65713 + a[n] * 1686049;
return cs;
}
namespace {
struct ArgsortComparator {
const float *vals;
bool operator() (const size_t a, const size_t b) const {
return vals[a] < vals[b];
}
};
struct SegmentS {
size_t i0; // begin pointer in the permutation array
size_t i1; // end
size_t len() const {
return i1 - i0;
}
};
// see https://en.wikipedia.org/wiki/Merge_algorithm#Parallel_merge
// extended to > 1 merge thread
// merges 2 ranges that should be consecutive on the source into
// the union of the two on the destination
template<typename T>
void parallel_merge (const T *src, T *dst, SegmentS &s1, SegmentS & s2, int nt, const ArgsortComparator & comp) {
if (s2.len() > s1.len()) { // make sure that s1 larger than s2
std::swap(s1, s2);
}
// compute sub-ranges for each thread
SegmentS s1s[nt], s2s[nt], sws[nt];
s2s[0].i0 = s2.i0;
s2s[nt - 1].i1 = s2.i1;
// not sure parallel actually helps here
#pragma omp parallel for num_threads(nt)
for (int t = 0; t < nt; t++) {
s1s[t].i0 = s1.i0 + s1.len() * t / nt;
s1s[t].i1 = s1.i0 + s1.len() * (t + 1) / nt;
if (t + 1 < nt) {
T pivot = src[s1s[t].i1];
size_t i0 = s2.i0, i1 = s2.i1;
while (i0 + 1 < i1) {
size_t imed = (i1 + i0) / 2;
if (comp (pivot, src[imed])) {i1 = imed; }
else {i0 = imed; }
}
s2s[t].i1 = s2s[t + 1].i0 = i1;
}
}
s1.i0 = std::min(s1.i0, s2.i0);
s1.i1 = std::max(s1.i1, s2.i1);
s2 = s1;
sws[0].i0 = s1.i0;
for (int t = 0; t < nt; t++) {
sws[t].i1 = sws[t].i0 + s1s[t].len() + s2s[t].len();
if (t + 1 < nt) {
sws[t + 1].i0 = sws[t].i1;
}
}
assert(sws[nt - 1].i1 == s1.i1);
// do the actual merging
#pragma omp parallel for num_threads(nt)
for (int t = 0; t < nt; t++) {
SegmentS sw = sws[t];
SegmentS s1t = s1s[t];
SegmentS s2t = s2s[t];
if (s1t.i0 < s1t.i1 && s2t.i0 < s2t.i1) {
for (;;) {
// assert (sw.len() == s1t.len() + s2t.len());
if (comp(src[s1t.i0], src[s2t.i0])) {
dst[sw.i0++] = src[s1t.i0++];
if (s1t.i0 == s1t.i1) break;
} else {
dst[sw.i0++] = src[s2t.i0++];
if (s2t.i0 == s2t.i1) break;
}
}
}
if (s1t.len() > 0) {
assert(s1t.len() == sw.len());
memcpy(dst + sw.i0, src + s1t.i0, s1t.len() * sizeof(dst[0]));
} else if (s2t.len() > 0) {
assert(s2t.len() == sw.len());
memcpy(dst + sw.i0, src + s2t.i0, s2t.len() * sizeof(dst[0]));
}
}
}
};
void fvec_argsort (size_t n, const float *vals, size_t *perm) {
for (size_t i = 0; i < n; i++) perm[i] = i;
ArgsortComparator comp = {vals};
std::sort (perm, perm + n, comp);
}
void fvec_argsort_parallel (size_t n, const float *vals, size_t *perm) {
size_t * perm2 = new size_t[n];
// 2 result tables, during merging, flip between them
size_t *permB = perm2, *permA = perm;
int nt = omp_get_max_threads();
{ // prepare correct permutation so that the result ends in perm
// at final iteration
int nseg = nt;
while (nseg > 1) {
nseg = (nseg + 1) / 2;
std::swap (permA, permB);
}
}
#pragma omp parallel
for (size_t i = 0; i < n; i++) permA[i] = i;
ArgsortComparator comp = {vals};
SegmentS segs[nt];
// independent sorts
#pragma omp parallel for
for (int t = 0; t < nt; t++) {
size_t i0 = t * n / nt;
size_t i1 = (t + 1) * n / nt;
SegmentS seg = {i0, i1};
std::sort (permA + seg.i0, permA + seg.i1, comp);
segs[t] = seg;
}
int prev_nested = omp_get_nested();
omp_set_nested(1);
int nseg = nt;
while (nseg > 1) {
int nseg1 = (nseg + 1) / 2;
int sub_nt = nseg % 2 == 0 ? nt : nt - 1;
int sub_nseg1 = nseg / 2;
#pragma omp parallel for num_threads(nseg1)
for (int s = 0; s < nseg; s += 2) {
if (s + 1 == nseg) { // otherwise isolated segment
memcpy(permB + segs[s].i0, permA + segs[s].i0,
segs[s].len() * sizeof(size_t));
} else {
int t0 = s * sub_nt / sub_nseg1;
int t1 = (s + 1) * sub_nt / sub_nseg1;
printf("merge %d %d, %d threads\n", s, s + 1, t1 - t0);
parallel_merge(permA, permB, segs[s], segs[s + 1],
t1 - t0, comp);
}
}
for (int s = 0; s < nseg; s += 2)
segs[s / 2] = segs[s];
nseg = nseg1;
std::swap (permA, permB);
}
assert (permA == perm);
omp_set_nested(prev_nested);
delete [] perm2;
}
const float *fvecs_maybe_subsample ( size_t d, size_t *n, size_t nmax, const float *x, bool verbose, int64_t seed) {
if (*n <= nmax) return x; // nothing to do
size_t n2 = nmax;
if (verbose) {
printf (" Input training set too big (max size is %ld), sampling %ld / %ld vectors\n", nmax, n2, *n);
}
std::vector<int> subset (*n);
rand_perm (subset.data (), *n, seed);
float *x_subset = new float[n2 * d];
for (int64_t i = 0; i < n2; i++)
memcpy (&x_subset[i * d], &x[subset[i] * size_t(d)], sizeof (x[0]) * d);
*n = n2;
return x_subset;
}
void binary_to_real(size_t d, const uint8_t *x_in, float *x_out) {
for (size_t i = 0; i < d; ++i) {
x_out[i] = 2 * ((x_in[i >> 3] >> (i & 7)) & 1) - 1;
}
}
void real_to_binary(size_t d, const float *x_in, uint8_t *x_out) {
for (size_t i = 0; i < d / 8; ++i) {
uint8_t b = 0;
for (int j = 0; j < 8; ++j) {
if (x_in[8 * i + j] > 0) {
b |= (1 << j);
}
}
x_out[i] = b;
}
}
// from Python's stringobject.c
uint64_t hash_bytes (const uint8_t *bytes, int64_t n) {
const uint8_t *p = bytes;
uint64_t x = (uint64_t)(*p) << 7;
int64_t len = n;
while (--len >= 0) {
x = (1000003*x) ^ *p++;
}
x ^= n;
return x;
}
bool check_openmp() {
omp_set_num_threads(10);
if (omp_get_max_threads() != 10) {
return false;
}
std::vector<int> nt_per_thread(10);
size_t sum = 0;
bool in_parallel = true;
#pragma omp parallel reduction(+: sum)
{
if (!omp_in_parallel()) {
in_parallel = false;
}
int nt = omp_get_num_threads();
int rank = omp_get_thread_num();
nt_per_thread[rank] = nt;
#pragma omp for
for(int i = 0; i < 1000 * 1000 * 10; i++) {
sum += i;
}
}
if (!in_parallel) {
return false;
}
if (nt_per_thread[0] != 10) {
return false;
}
if (sum == 0) {
return false;
}
return true;
}
} // namespace faiss
4.1.5.3 test_utils.cpp文件
4.2 impl目录
4.2.1 FaissException.h,FaissException.cpp和FaissException.cpp文件
此文件主要描述异常的处理方式:FaissException,handleExceptions以及ScopeDeleter,ScopeDeleter1。定义某些宏: FAISS_ASSERT,FAISS_ASSERT_MSG,FAISS_ASSERT_FMT; FAISS_THROW_MSG,FAISS_THROW_FMT; FAISS_THROW_IF_NOT_FMT,FAISS_THROW_IF_NOT_MSG,FAISS_THROW_IF_NOT_FMT。
4.2.1.1 FaissException.h文件
#ifndef FAISS_EXCEPTION_INCLUDED
#define FAISS_EXCEPTION_INCLUDED
#include <exception>
#include <string>
#include <vector>
#include <utility>
namespace faiss {
/// Base class for Faiss exceptions
class FaissException : public std::exception {
public:
explicit FaissException(const std::string& msg);
FaissException(const std::string& msg, const char* funcName,const char* file, int line);
/// from std::exception
const char* what() const noexcept override;
std::string msg;
};
/// Handle multiple exceptions from worker threads, throwing an appropriate
/// exception that aggregates the information
/// The pair int is the thread that generated the exception
void handleExceptions(std::vector<std::pair<int, std::exception_ptr>>& exceptions);
/** bare-bones unique_ptr this one deletes with delete [] */
template<class T>
struct ScopeDeleter {
const T * ptr;
explicit ScopeDeleter (const T* ptr = nullptr): ptr (ptr) {}
void release () {ptr = nullptr; }
void set (const T * ptr_in) { ptr = ptr_in; }
void swap (ScopeDeleter<T> &other) {std::swap (ptr, other.ptr); }
~ScopeDeleter () {
delete [] ptr;
}
};
/** same but deletes with the simple delete (least common case) */
template<class T>
struct ScopeDeleter1 {
const T * ptr;
explicit ScopeDeleter1 (const T* ptr = nullptr): ptr (ptr) {}
void release () {ptr = nullptr; }
void set (const T * ptr_in) { ptr = ptr_in; }
void swap (ScopeDeleter1<T> &other) {std::swap (ptr, other.ptr); }
~ScopeDeleter1 () {
delete ptr;
}
};
}
#endif
4.2.1.2 FaissException.cpp文件
#include <impl/FaissException.h>
#include <sstream>
namespace faiss {
FaissException::FaissException(const std::string& m) : msg(m) { }
FaissException::FaissException(const std::string& m,const char* funcName, const char* file,int line) {
int size = snprintf(nullptr, 0, "Error in %s at %s:%d: %s", funcName, file, line, m.c_str());
msg.resize(size + 1);
snprintf(&msg[0], msg.size(), "Error in %s at %s:%d: %s", funcName, file, line, m.c_str());
}
const char* FaissException::what() const noexcept {
return msg.c_str();
}
void handleExceptions(std::vector<std::pair<int, std::exception_ptr>>& exceptions) {
if (exceptions.size() == 1) {
// throw the single received exception directly
std::rethrow_exception(exceptions.front().second);
} else if (exceptions.size() > 1) {
// multiple exceptions; aggregate them and return a single exception
std::stringstream ss;
for (auto& p : exceptions) {
try {
std::rethrow_exception(p.second);
} catch (std::exception& ex) {
if (ex.what()) {
// exception message available
ss << "Exception thrown from index " << p.first << ": " << ex.what() << "\n";
} else {
// No message available
ss << "Unknown exception thrown from index " << p.first << "\n";
}
} catch (...) {
ss << "Unknown exception thrown from index " << p.first << "\n";
}
}
throw FaissException(ss.str());
}
}
}
4.2.1.3 FaissAssert.h文件
#ifndef FAISS_ASSERT_INCLUDED
#define FAISS_ASSERT_INCLUDED
#include <impl/FaissException.h>
#include <cstdlib>
#include <cstdio>
#include <string>
/// Assertions
#define FAISS_ASSERT(X) \
do { \
if (! (X)) { \
fprintf(stderr, "Faiss assertion '%s' failed in %s " \
"at %s:%d\n", \
#X, __PRETTY_FUNCTION__, __FILE__, __LINE__); \
abort(); \
} \
} while (false)
#define FAISS_ASSERT_MSG(X, MSG) \
do { \
if (! (X)) { \
fprintf(stderr, "Faiss assertion '%s' failed in %s " \
"at %s:%d; details: " MSG "\n", \
#X, __PRETTY_FUNCTION__, __FILE__, __LINE__); \
abort(); \
} \
} while (false)
#define FAISS_ASSERT_FMT(X, FMT, ...) \
do { \
if (! (X)) { \
fprintf(stderr, "Faiss assertion '%s' failed in %s " \
"at %s:%d; details: " FMT "\n", \
#X, __PRETTY_FUNCTION__, __FILE__, __LINE__, __VA_ARGS__); \
abort(); \
} \
} while (false)
///
/// Exceptions for returning user errors
///
#define FAISS_THROW_MSG(MSG) \
do { \
throw faiss::FaissException(MSG, __PRETTY_FUNCTION__, __FILE__, __LINE__); \
} while (false)
#define FAISS_THROW_FMT(FMT, ...) \
do { \
std::string __s; \
int __size = snprintf(nullptr, 0, FMT, __VA_ARGS__); \
__s.resize(__size + 1); \
snprintf(&__s[0], __s.size(), FMT, __VA_ARGS__); \
throw faiss::FaissException(__s, __PRETTY_FUNCTION__, __FILE__, __LINE__); \
} while (false)
///
/// Exceptions thrown upon a conditional failure
///
#define FAISS_THROW_IF_NOT(X) \
do { \
if (!(X)) { \
FAISS_THROW_FMT("Error: '%s' failed", #X); \
} \
} while (false)
#define FAISS_THROW_IF_NOT_MSG(X, MSG) \
do { \
if (!(X)) { \
FAISS_THROW_FMT("Error: '%s' failed: " MSG, #X); \
} \
} while (false)
#define FAISS_THROW_IF_NOT_FMT(X, FMT, ...) \
do { \
if (!(X)) { \
FAISS_THROW_FMT("Error: '%s' failed: " FMT, #X, __VA_ARGS__); \
} \
} while (false)
#endif
4.2.1.4 test_assert_exception.cpp文件
#include<cstdio>
#include<impl/FaissAssert.h>
int main(){
int* x=0;
try{
FAISS_ASSERT(x);
}catch (...) {
FAISS_ASSERT_MSG(x,"test");
}
return 0;
}
4.2.2 AuxIndexStructures.h和AuxIndexStructures.cpp文件
此文件定义了ID选择器:IDSelector,IDSelectorRange,IDSelectorArray,IDSelectorBatch 和检索结果RangeSearchResult,RangeSearchPartialResult以及相关的BufferList,DistanceComputer。
4.2.2.1 AuxIndexStructures.h文件
// Auxiliary index structures, that are used in indexes but that can be forward-declared
#ifndef FAISS_AUX_INDEX_STRUCTURES_H
#define FAISS_AUX_INDEX_STRUCTURES_H
#include <stdint.h>
#include <vector>
#include <unordered_set>
#include <memory>
#include <mutex>
#include <faiss/Index.h>
namespace faiss {
/** The objective is to have a simple result structure while
* minimizing the number of mem copies in the result. The method
* do_allocation can be overloaded to allocate the result tables in
* the matrix type of a scripting language like Lua or Python. */
struct RangeSearchResult {
size_t nq; ///< nb of queries
size_t *lims; ///< size (nq + 1)
typedef Index::idx_t idx_t;
idx_t *labels; ///< result for query i is labels[lims[i]:lims[i+1]]
float *distances; ///< corresponding distances (not sorted)
size_t buffer_size; ///< size of the result buffers used
/// lims must be allocated on input to range_search.
explicit RangeSearchResult (idx_t nq, bool alloc_lims=true);
/// called when lims contains the nb of elements result entries for each query
virtual void do_allocation ();
virtual ~RangeSearchResult ();
};
/** Encapsulates a set of ids to remove. */
struct IDSelector {
typedef Index::idx_t idx_t;
virtual bool is_member (idx_t id) const = 0;
virtual ~IDSelector() {}
};
/** remove ids between [imni, imax) */
struct IDSelectorRange: IDSelector {
idx_t imin, imax;
IDSelectorRange (idx_t imin, idx_t imax);
bool is_member(idx_t id) const override;
~IDSelectorRange() override {}
};
/** simple list of elements to remove
*
* this is inefficient in most cases, except for IndexIVF with
* maintain_direct_map
*/
struct IDSelectorArray: IDSelector {
size_t n;
const idx_t *ids;
IDSelectorArray (size_t n, const idx_t *ids);
bool is_member(idx_t id) const override;
~IDSelectorArray() override {}
};
/** Remove ids from a set. Repetitions of ids in the indices set
* passed to the constructor does not hurt performance. The hash
* function used for the bloom filter and GCC's implementation of
* unordered_set are just the least significant bits of the id. This
* works fine for random ids or ids in sequences but will produce many
* hash collisions if lsb's are always the same */
struct IDSelectorBatch: IDSelector {
std::unordered_set<idx_t> set;
typedef unsigned char uint8_t;
std::vector<uint8_t> bloom; // assumes low bits of id are a good hash value
int nbits;
idx_t mask;
IDSelectorBatch (size_t n, const idx_t *indices);
bool is_member(idx_t id) const override;
~IDSelectorBatch() override {}
};
/****************************************************************
* Result structures for range search.
*
* The main constraint here is that we want to support parallel
* queries from different threads in various ways: 1 thread per query,
* several threads per query. We store the actual results in blocks of
* fixed size rather than exponentially increasing memory. At the end,
* we copy the block content to a linear result array.
*****************************************************************/
/** List of temporary buffers used to store results before they are
* copied to the RangeSearchResult object. */
struct BufferList {
typedef Index::idx_t idx_t;
// buffer sizes in # entries
size_t buffer_size;
struct Buffer {
idx_t *ids;
float *dis;
};
std::vector<Buffer> buffers;
size_t wp; ///< write pointer in the last buffer.
explicit BufferList (size_t buffer_size);
~BufferList ();
/// create a new buffer
void append_buffer ();
/// add one result, possibly appending a new buffer if needed
void add (idx_t id, float dis);
/// copy elemnts ofs:ofs+n-1 seen as linear data in the buffers to
/// tables dest_ids, dest_dis
void copy_range (size_t ofs, size_t n,idx_t * dest_ids, float *dest_dis);
};
struct RangeSearchPartialResult;
/// result structure for a single query
struct RangeQueryResult {
using idx_t = Index::idx_t;
idx_t qno; //< id of the query
size_t nres; //< nb of results for this query
RangeSearchPartialResult * pres;
/// called by search function to report a new result
void add (float dis, idx_t id);
};
/// the entries in the buffers are split per query
struct RangeSearchPartialResult: BufferList {
RangeSearchResult * res;
/// eventually the result will be stored in res_in
explicit RangeSearchPartialResult (RangeSearchResult * res_in);
/// query ids + nb of results per query.
std::vector<RangeQueryResult> queries;
/// begin a new result
RangeQueryResult & new_result (idx_t qno);
/*****************************************
* functions used at the end of the search to merge the result
* lists */
void finalize ();
/// called by range_search before do_allocation
void set_lims ();
/// called by range_search after do_allocation
void copy_result (bool incremental = false);
/// merge a set of PartialResult's into one RangeSearchResult
/// on ouptut the partialresults are empty!
static void merge (std::vector <RangeSearchPartialResult *> &partial_results, bool do_delete=true);
};
/***********************************************************
* The distance computer maintains a current query and computes
* distances to elements in an index that supports random access.
*
* The DistanceComputer is not intended to be thread-safe (eg. because
* it maintains counters) so the distance functions are not const,
* instanciate one from each thread if needed.
***********************************************************/
struct DistanceComputer {
using idx_t = Index::idx_t;
/// called before computing distances
virtual void set_query(const float *x) = 0;
/// compute distance of vector i to current query
virtual float operator () (idx_t i) = 0;
/// compute distance between two stored vectors
virtual float symmetric_dis (idx_t i, idx_t j) = 0;
virtual ~DistanceComputer() {}
};
/***********************************************************
* Interrupt callback
***********************************************************/
struct InterruptCallback {
virtual bool want_interrupt () = 0;
virtual ~InterruptCallback() {}
// lock that protects concurrent calls to is_interrupted
static std::mutex lock;
static std::unique_ptr<InterruptCallback> instance;
static void clear_instance ();
/** check if:
* - an interrupt callback is set
* - the callback retuns true
* if this is the case, then throw an exception. Should not be called
* from multiple threds.
*/
static void check ();
/// same as check() but return true if is interrupted instead of
/// throwing. Can be called from multiple threads.
static bool is_interrupted ();
/** assuming each iteration takes a certain number of flops, what
* is a reasonable interval to check for interrupts?
*/
static size_t get_period_hint (size_t flops);
};
}; // namespace faiss
#endif
4.2.2.2 AuxIndexStructures.cpp文件
#include <cstring>
#include <faiss/impl/AuxIndexStructures.h>
#include <faiss/impl/FaissAssert.h>
namespace faiss {
/***********************************************************************
* RangeSearchResult
***********************************************************************/
RangeSearchResult::RangeSearchResult (idx_t nq, bool alloc_lims): nq (nq) {
if (alloc_lims) {
lims = new size_t [nq + 1];
memset (lims, 0, sizeof(*lims) * (nq + 1));
} else {
lims = nullptr;
}
labels = nullptr;
distances = nullptr;
buffer_size = 1024 * 256;
}
/// called when lims contains the nb of elements result entries for each query
void RangeSearchResult::do_allocation () {
size_t ofs = 0;
for (int i = 0; i < nq; i++) {
size_t n = lims[i];
lims [i] = ofs;
ofs += n;
}
lims [nq] = ofs;
labels = new idx_t [ofs];
distances = new float [ofs];
}
RangeSearchResult::~RangeSearchResult () {
delete [] labels;
delete [] distances;
delete [] lims;
}
/***********************************************************************
* BufferList
***********************************************************************/
BufferList::BufferList (size_t buffer_size): buffer_size (buffer_size) {
wp = buffer_size;
}
BufferList::~BufferList () {
for (int i = 0; i < buffers.size(); i++) {
delete [] buffers[i].ids;
delete [] buffers[i].dis;
}
}
void BufferList::add (idx_t id, float dis) {
if (wp == buffer_size) { // need new buffer
append_buffer();
}
Buffer & buf = buffers.back();
buf.ids [wp] = id;
buf.dis [wp] = dis;
wp++;
}
void BufferList::append_buffer ()
{
Buffer buf = {new idx_t [buffer_size], new float [buffer_size]};
buffers.push_back (buf);
wp = 0;
}
/// copy elemnts ofs:ofs+n-1 seen as linear data in the buffers to
/// tables dest_ids, dest_dis
void BufferList::copy_range (size_t ofs, size_t n, idx_t * dest_ids, float *dest_dis) {
size_t bno = ofs / buffer_size;
ofs -= bno * buffer_size;
while (n > 0) {
size_t ncopy = ofs + n < buffer_size ? n : buffer_size - ofs;
Buffer buf = buffers [bno];
memcpy (dest_ids, buf.ids + ofs, ncopy * sizeof(*dest_ids));
memcpy (dest_dis, buf.dis + ofs, ncopy * sizeof(*dest_dis));
dest_ids += ncopy;
dest_dis += ncopy;
ofs = 0;
bno ++;
n -= ncopy;
}
}
/***********************************************************************
* RangeSearchPartialResult
***********************************************************************/
void RangeQueryResult::add (float dis, idx_t id) {
nres++;
pres->add (id, dis);
}
RangeSearchPartialResult::RangeSearchPartialResult (RangeSearchResult * res_in):
BufferList(res_in->buffer_size), res(res_in) {}
/// begin a new result
RangeQueryResult & RangeSearchPartialResult::new_result (idx_t qno) {
RangeQueryResult qres = {qno, 0, this};
queries.push_back (qres);
return queries.back();
}
void RangeSearchPartialResult::finalize () {
set_lims ();
#pragma omp barrier
#pragma omp single
res->do_allocation ();
#pragma omp barrier
copy_result ();
}
/// called by range_search before do_allocation
void RangeSearchPartialResult::set_lims () {
for (int i = 0; i < queries.size(); i++) {
RangeQueryResult & qres = queries[i];
res->lims[qres.qno] = qres.nres;
}
}
/// called by range_search after do_allocation
void RangeSearchPartialResult::copy_result (bool incremental) {
size_t ofs = 0;
for (int i = 0; i < queries.size(); i++) {
RangeQueryResult & qres = queries[i];
copy_range (ofs, qres.nres,
res->labels + res->lims[qres.qno],
res->distances + res->lims[qres.qno]);
if (incremental) {
res->lims[qres.qno] += qres.nres;
}
ofs += qres.nres;
}
}
void RangeSearchPartialResult::merge (std::vector <RangeSearchPartialResult *> &
partial_results, bool do_delete) {
int npres = partial_results.size();
if (npres == 0) return;
RangeSearchResult *result = partial_results[0]->res;
size_t nx = result->nq;
// count
for (const RangeSearchPartialResult * pres : partial_results) {
if (!pres) continue;
for (const RangeQueryResult &qres : pres->queries) {
result->lims[qres.qno] += qres.nres;
}
}
result->do_allocation ();
for (int j = 0; j < npres; j++) {
if (!partial_results[j]) continue;
partial_results[j]->copy_result (true);
if (do_delete) {
delete partial_results[j];
partial_results[j] = nullptr;
}
}
// reset the limits
for (size_t i = nx; i > 0; i--) {
result->lims [i] = result->lims [i - 1];
}
result->lims [0] = 0;
}
/***********************************************************************
* IDSelectorRange
***********************************************************************/
IDSelectorRange::IDSelectorRange (idx_t imin, idx_t imax): imin (imin), imax (imax) { }
bool IDSelectorRange::is_member (idx_t id) const {
return id >= imin && id < imax;
}
/***********************************************************************
* IDSelectorArray
***********************************************************************/
IDSelectorArray::IDSelectorArray (size_t n, const idx_t *ids): n (n), ids(ids) { }
bool IDSelectorArray::is_member (idx_t id) const {
for (idx_t i = 0; i < n; i++) {
if (ids[i] == id) return true;
}
return false;
}
/***********************************************************************
* IDSelectorBatch
***********************************************************************/
IDSelectorBatch::IDSelectorBatch (size_t n, const idx_t *indices) {
nbits = 0;
while (n > (1L << nbits)) nbits++;
nbits += 5;
// for n = 1M, nbits = 25 is optimal, see P56659518
mask = (1L << nbits) - 1;
bloom.resize (1UL << (nbits - 3), 0);
for (long i = 0; i < n; i++) {
Index::idx_t id = indices[i];
set.insert(id);
id &= mask;
bloom[id >> 3] |= 1 << (id & 7);
}
}
bool IDSelectorBatch::is_member (idx_t i) const {
long im = i & mask;
if(!(bloom[im>>3] & (1 << (im & 7)))) {
return 0;
}
return set.count(i);
}
/***********************************************************
* Interrupt callback
***********************************************************/
std::unique_ptr<InterruptCallback> InterruptCallback::instance;
std::mutex InterruptCallback::lock;
void InterruptCallback::clear_instance () {
delete instance.release ();
}
void InterruptCallback::check () {
if (!instance.get()) {
return;
}
if (instance->want_interrupt ()) {
FAISS_THROW_MSG ("computation interrupted");
}
}
bool InterruptCallback::is_interrupted () {
if (!instance.get()) {
return false;
}
std::lock_guard<std::mutex> guard(lock);
return instance->want_interrupt();
}
size_t InterruptCallback::get_period_hint (size_t flops) {
if (!instance.get()) {
return 1L << 30; // never check
}
// for 10M flops, it is reasonable to check once every 10 iterations
return std::max((size_t)10 * 10 * 1000 * 1000 / (flops + 1), (size_t)1);
}
} // namespace faiss
4.2.4 ProductQuantizer.h,ProductQuantizer-inl.h和ProductQuantizer.cpp文件
- ProductQuantizer.h文件
#ifndef FAISS_PRODUCT_QUANTIZER_H
#define FAISS_PRODUCT_QUANTIZER_H
#include <stdint.h>
#include <vector>
#include <faiss/Clustering.h>
#include <faiss/utils/Heap.h>
namespace faiss {
/** Product Quantizer. Implemented only for METRIC_L2 */
struct ProductQuantizer {
using idx_t = Index::idx_t;
size_t d; ///< size of the input vectors
size_t M; ///< number of subquantizers
size_t nbits; ///< number of bits per quantization index
// values derived from the above
size_t dsub; ///< dimensionality of each subvector
size_t code_size; ///< bytes per indexed vector
size_t ksub; ///< number of centroids for each subquantizer
bool verbose; ///< verbose during training?
/// initialization
enum train_type_t {
Train_default,
Train_hot_start, ///< the centroids are already initialized
Train_shared, ///< share dictionary accross PQ segments
Train_hypercube, ///< intialize centroids with nbits-D hypercube
Train_hypercube_pca, ///< intialize centroids with nbits-D hypercube
};
train_type_t train_type;
ClusteringParameters cp; ///< parameters used during clustering
/// if non-NULL, use this index for assignment (should be of size d / M)
Index *assign_index;
/// Centroid table, size M * ksub * dsub
std::vector<float> centroids;
/// return the centroids associated with subvector m
float * get_centroids (size_t m, size_t i) {
return ¢roids [(m * ksub + i) * dsub];
}
const float * get_centroids (size_t m, size_t i) const {
return ¢roids [(m * ksub + i) * dsub];
}
// Train the product quantizer on a set of points. A clustering
// can be set on input to define non-default clustering parameters
void train (int n, const float *x);
ProductQuantizer(size_t d, /* dimensionality of the input vectors */
size_t M, /* number of subquantizers */
size_t nbits); /* number of bit per subvector index */
ProductQuantizer ();
/// compute derived values when d, M and nbits have been set
void set_derived_values ();
/// Define the centroids for subquantizer m
void set_params (const float * centroids, int m);
/// Quantize one vector with the product quantizer
void compute_code (const float * x, uint8_t * code) const ;
/// same as compute_code for several vectors
void compute_codes (const float * x, uint8_t * codes, size_t n) const ;
/// speed up code assignment using assign_index (non-const because the index is changed)
void compute_codes_with_assign_index (const float * x, uint8_t * codes, size_t n);
/// decode a vector from a given code (or n vectors if third argument)
void decode (const uint8_t *code, float *x) const;
void decode (const uint8_t *code, float *x, size_t n) const;
/// If we happen to have the distance tables precomputed, this is more efficient to compute the codes.
void compute_code_from_distance_table (const float *tab, uint8_t *code) const;
/** Compute distance table for one vector.
*
* The distance table for x = [x_0 x_1 .. x_(M-1)] is a M * ksub
* matrix that contains
*
* dis_table (m, j) = || x_m - c_(m, j)||^2
* for m = 0..M-1 and j = 0 .. ksub - 1
*
* where c_(m, j) is the centroid no j of sub-quantizer m.
*
* @param x input vector size d
* @param dis_table output table, size M * ksub
*/
void compute_distance_table (const float * x, float * dis_table) const;
void compute_inner_prod_table (const float * x, float * dis_table) const;
/** compute distance table for several vectors
* @param nx nb of input vectors
* @param x input vector size nx * d
* @param dis_table output table, size nx * M * ksub
*/
void compute_distance_tables (size_t nx, const float * x, float * dis_tables) const;
void compute_inner_prod_tables (size_t nx, const float * x, float * dis_tables) const;
/** perform a search (L2 distance)
* @param x query vectors, size nx * d
* @param nx nb of queries
* @param codes database codes, size ncodes * code_size
* @param ncodes nb of nb vectors
* @param res heap array to store results (nh == nx)
* @param init_finalize_heap initialize heap (input) and sort (output)?
*/
void search (const float * x, size_t nx, const uint8_t * codes,const size_t ncodes,
float_maxheap_array_t *res, bool init_finalize_heap = true) const;
/** same as search, but with inner product similarity */
void search_ip (const float * x, size_t nx, const uint8_t * codes, const size_t ncodes,
float_minheap_array_t *res, bool init_finalize_heap = true) const;
/// Symmetric Distance Table
std::vector<float> sdc_table;
// intitialize the SDC table from the centroids
void compute_sdc_table ();
void search_sdc (const uint8_t * qcodes, size_t nq, const uint8_t * bcodes, const size_t ncodes,
float_maxheap_array_t * res, bool init_finalize_heap = true) const;
};
/*************************************************
* Objects to encode / decode strings of bits
*************************************************/
struct PQEncoderGeneric {
uint8_t *code; ///< code for this vector
uint8_t offset;
const int nbits; ///< number of bits per subquantizer index
uint8_t reg;
PQEncoderGeneric(uint8_t *code, int nbits, uint8_t offset = 0);
void encode(uint64_t x);
~PQEncoderGeneric();
};
struct PQEncoder8 {
uint8_t *code;
PQEncoder8(uint8_t *code, int nbits);
void encode(uint64_t x);
};
struct PQEncoder16 {
uint16_t *code;
PQEncoder16(uint8_t *code, int nbits);
void encode(uint64_t x);
};
struct PQDecoderGeneric {
const uint8_t *code;
uint8_t offset;
const int nbits;
const uint64_t mask;
uint8_t reg;
PQDecoderGeneric(const uint8_t *code, int nbits);
uint64_t decode();
};
struct PQDecoder8 {
const uint8_t *code;
PQDecoder8(const uint8_t *code, int nbits);
uint64_t decode();
};
struct PQDecoder16 {
const uint16_t *code;
PQDecoder16(const uint8_t *code, int nbits);
uint64_t decode();
};
} // namespace faiss
#include <faiss/impl/ProductQuantizer-inl.h>
#endif
- ProductQuantizer-inl.h文件
namespace faiss {
inline PQEncoderGeneric::PQEncoderGeneric(uint8_t *code, int nbits, uint8_t offset)
: code(code), offset(offset), nbits(nbits), reg(0) {
assert(nbits <= 64);
if (offset > 0) {
reg = (*code & ((1 << offset) - 1));
}
}
inline void PQEncoderGeneric::encode(uint64_t x) {
reg |= (uint8_t)(x << offset);
x >>= (8 - offset);
if (offset + nbits >= 8) {
*code++ = reg;
for (int i = 0; i < (nbits - (8 - offset)) / 8; ++i) {
*code++ = (uint8_t)x;
x >>= 8;
}
offset += nbits;
offset &= 7;
reg = (uint8_t)x;
} else {
offset += nbits;
}
}
inline PQEncoderGeneric::~PQEncoderGeneric() {
if (offset > 0) {
*code = reg;
}
}
inline PQEncoder8::PQEncoder8(uint8_t *code, int nbits) : code(code) {
assert(8 == nbits);
}
inline void PQEncoder8::encode(uint64_t x) {
*code++ = (uint8_t)x;
}
inline PQEncoder16::PQEncoder16(uint8_t *code, int nbits) : code((uint16_t *)code) {
assert(16 == nbits);
}
inline void PQEncoder16::encode(uint64_t x) {
*code++ = (uint16_t)x;
}
inline PQDecoderGeneric::PQDecoderGeneric(const uint8_t *code, int nbits)
: code(code), offset(0), nbits(nbits), mask((1ull << nbits) - 1), reg(0) {
assert(nbits <= 64);
}
inline uint64_t PQDecoderGeneric::decode() {
if (offset == 0) {
reg = *code;
}
uint64_t c = (reg >> offset);
if (offset + nbits >= 8) {
uint64_t e = 8 - offset;
++code;
for (int i = 0; i < (nbits - (8 - offset)) / 8; ++i) {
c |= ((uint64_t)(*code++) << e);
e += 8;
}
offset += nbits;
offset &= 7;
if (offset > 0) {
reg = *code;
c |= ((uint64_t)reg << e);
}
} else {
offset += nbits;
}
return c & mask;
}
inline PQDecoder8::PQDecoder8(const uint8_t *code, int nbits) : code(code) {
assert(8 == nbits);
}
inline uint64_t PQDecoder8::decode() {
return (uint64_t)(*code++);
}
inline PQDecoder16::PQDecoder16(const uint8_t *code, int nbits) : code((uint16_t *)code) {
assert(16 == nbits);
}
inline uint64_t PQDecoder16::decode() {
return (uint64_t)(*code++);
}
} // namespace faiss
- ProductQuantizer.cpp文件
#include <faiss/impl/ProductQuantizer.h>
#include <cstddef>
#include <cstring>
#include <cstdio>
#include <memory>
#include <algorithm>
#include <faiss/impl/FaissAssert.h>
#include <faiss/VectorTransform.h>
#include <faiss/IndexFlat.h>
#include <faiss/utils/distances.h>
extern "C" {
/* declare BLAS functions, see http://www.netlib.org/clapack/cblas/ */
int sgemm_ (const char *transa, const char *transb, FINTEGER *m, FINTEGER *
n, FINTEGER *k, const float *alpha, const float *a,
FINTEGER *lda, const float *b, FINTEGER *
ldb, float *beta, float *c, FINTEGER *ldc);
}
namespace faiss {
/* compute an estimator using look-up tables for typical values of M */
template <typename CT, class C>
void pq_estimators_from_tables_Mmul4 (int M, const CT * codes, size_t ncodes, const float * __restrict dis_table,
size_t ksub, size_t k, float * heap_dis, int64_t * heap_ids)
{
for (size_t j = 0; j < ncodes; j++) {
float dis = 0;
const float *dt = dis_table;
for (size_t m = 0; m < M; m+=4) {
float dism = 0;
dism = dt[*codes++]; dt += ksub;
dism += dt[*codes++]; dt += ksub;
dism += dt[*codes++]; dt += ksub;
dism += dt[*codes++]; dt += ksub;
dis += dism;
}
if (C::cmp (heap_dis[0], dis)) {
heap_pop<C> (k, heap_dis, heap_ids);
heap_push<C> (k, heap_dis, heap_ids, dis, j);
}
}
}
template <typename CT, class C>
void pq_estimators_from_tables_M4 (const CT * codes, size_t ncodes, const float * __restrict dis_table,
size_t ksub, size_t k, float * heap_dis, int64_t * heap_ids)
{
for (size_t j = 0; j < ncodes; j++) {
float dis = 0;
const float *dt = dis_table;
dis = dt[*codes++]; dt += ksub;
dis += dt[*codes++]; dt += ksub;
dis += dt[*codes++]; dt += ksub;
dis += dt[*codes++];
if (C::cmp (heap_dis[0], dis)) {
heap_pop<C> (k, heap_dis, heap_ids);
heap_push<C> (k, heap_dis, heap_ids, dis, j);
}
}
}
template <typename CT, class C>
static inline void pq_estimators_from_tables (const ProductQuantizer& pq, const CT * codes,
size_t ncodes, const float * dis_table, size_t k, float * heap_dis, int64_t * heap_ids)
{
if (pq.M == 4) {
pq_estimators_from_tables_M4<CT, C> (codes, ncodes, dis_table, pq.ksub, k, heap_dis, heap_ids);
return;
}
if (pq.M % 4 == 0) {
pq_estimators_from_tables_Mmul4<CT, C> (pq.M, codes, ncodes, dis_table, pq.ksub, k, heap_dis, heap_ids);
return;
}
/* Default is relatively slow */
const size_t M = pq.M;
const size_t ksub = pq.ksub;
for (size_t j = 0; j < ncodes; j++) {
float dis = 0;
const float * __restrict dt = dis_table;
for (int m = 0; m < M; m++) {
dis += dt[*codes++];
dt += ksub;
}
if (C::cmp (heap_dis[0], dis)) {
heap_pop<C> (k, heap_dis, heap_ids);
heap_push<C> (k, heap_dis, heap_ids, dis, j);
}
}
}
template <class C>
static inline void pq_estimators_from_tables_generic(const ProductQuantizer& pq, size_t nbits, const uint8_t *codes,
size_t ncodes, const float *dis_table, size_t k, float *heap_dis, int64_t *heap_ids)
{
const size_t M = pq.M;
const size_t ksub = pq.ksub;
for (size_t j = 0; j < ncodes; ++j) {
PQDecoderGeneric decoder( codes + j * pq.code_size, nbits);
float dis = 0;
const float * __restrict dt = dis_table;
for (size_t m = 0; m < M; m++) {
uint64_t c = decoder.decode();
dis += dt[c];
dt += ksub;
}
if (C::cmp(heap_dis[0], dis)) {
heap_pop<C>(k, heap_dis, heap_ids);
heap_push<C>(k, heap_dis, heap_ids, dis, j);
}
}
}
/*********************************************
* PQ implementation
*********************************************/
ProductQuantizer::ProductQuantizer (size_t d, size_t M, size_t nbits):
d(d), M(M), nbits(nbits), assign_index(nullptr)
{
set_derived_values ();
}
ProductQuantizer::ProductQuantizer () : ProductQuantizer(0, 1, 0) {}
void ProductQuantizer::set_derived_values () {
// quite a few derived values
FAISS_THROW_IF_NOT (d % M == 0);
dsub = d / M;
code_size = (nbits * M + 7) / 8;
ksub = 1 << nbits;
centroids.resize (d * ksub);
verbose = false;
train_type = Train_default;
}
void ProductQuantizer::set_params (const float * centroids_, int m) {
memcpy (get_centroids(m, 0), centroids_, ksub * dsub * sizeof (centroids_[0]));
}
static void init_hypercube (int d, int nbits,
int n, const float * x,
float *centroids)
{
std::vector<float> mean (d);
for (int i = 0; i < n; i++)
for (int j = 0; j < d; j++)
mean [j] += x[i * d + j];
float maxm = 0;
for (int j = 0; j < d; j++) {
mean [j] /= n;
if (fabs(mean[j]) > maxm) maxm = fabs(mean[j]);
}
for (int i = 0; i < (1 << nbits); i++) {
float * cent = centroids + i * d;
for (int j = 0; j < nbits; j++)
cent[j] = mean [j] + (((i >> j) & 1) ? 1 : -1) * maxm;
for (int j = nbits; j < d; j++)
cent[j] = mean [j];
}
}
static void init_hypercube_pca (int d, int nbits,
int n, const float * x,
float *centroids)
{
PCAMatrix pca (d, nbits);
pca.train (n, x);
for (int i = 0; i < (1 << nbits); i++) {
float * cent = centroids + i * d;
for (int j = 0; j < d; j++) {
cent[j] = pca.mean[j];
float f = 1.0;
for (int k = 0; k < nbits; k++)
cent[j] += f *
sqrt (pca.eigenvalues [k]) *
(((i >> k) & 1) ? 1 : -1) *
pca.PCAMat [j + k * d];
}
}
}
void ProductQuantizer::train (int n, const float * x) {
if (train_type != Train_shared) {
train_type_t final_train_type;
final_train_type = train_type;
if (train_type == Train_hypercube || train_type == Train_hypercube_pca) {
if (dsub < nbits) {
final_train_type = Train_default;
printf ("cannot train hypercube: nbits=%ld > log2(d=%ld)\n",nbits, dsub);
}
}
float * xslice = new float[n * dsub];
ScopeDeleter<float> del (xslice);
for (int m = 0; m < M; m++) {
for (int j = 0; j < n; j++)
memcpy (xslice + j * dsub, x + j * d + m * dsub, dsub * sizeof(float));
Clustering clus (dsub, ksub, cp);
// we have some initialization for the centroids
if (final_train_type != Train_default) {
clus.centroids.resize (dsub * ksub);
}
switch (final_train_type) {
case Train_hypercube:
init_hypercube (dsub, nbits, n, xslice, clus.centroids.data ());
break;
case Train_hypercube_pca:
init_hypercube_pca (dsub, nbits, n, xslice, clus.centroids.data ());
break;
case Train_hot_start:
memcpy (clus.centroids.data(), get_centroids (m, 0), dsub * ksub * sizeof (float));
break;
default: ;
}
if(verbose) {
clus.verbose = true;
printf ("Training PQ slice %d/%zd\n", m, M);
}
IndexFlatL2 index (dsub);
clus.train (n, xslice, assign_index ? *assign_index : index);
set_params (clus.centroids.data(), m);
}
} else {
Clustering clus (dsub, ksub, cp);
if(verbose) {
clus.verbose = true;
printf ("Training all PQ slices at once\n");
}
IndexFlatL2 index (dsub);
clus.train (n * M, x, assign_index ? *assign_index : index);
for (int m = 0; m < M; m++) {
set_params (clus.centroids.data(), m);
}
}
}
template<class PQEncoder>
void compute_code(const ProductQuantizer& pq, const float *x, uint8_t *code) {
float distances [pq.ksub];
PQEncoder encoder(code, pq.nbits);
for (size_t m = 0; m < pq.M; m++) {
float mindis = 1e20;
uint64_t idxm = 0;
const float * xsub = x + m * pq.dsub;
fvec_L2sqr_ny(distances, xsub, pq.get_centroids(m, 0), pq.dsub, pq.ksub);
/* Find best centroid */
for (size_t i = 0; i < pq.ksub; i++) {
float dis = distances[i];
if (dis < mindis) {
mindis = dis;
idxm = i;
}
}
encoder.encode(idxm);
}
}
void ProductQuantizer::compute_code(const float * x, uint8_t * code) const {
switch (nbits) {
case 8:
faiss::compute_code<PQEncoder8>(*this, x, code);
break;
case 16:
faiss::compute_code<PQEncoder16>(*this, x, code);
break;
default:
faiss::compute_code<PQEncoderGeneric>(*this, x, code);
break;
}
}
template<class PQDecoder>
void decode(const ProductQuantizer& pq, const uint8_t *code, float *x) {
PQDecoder decoder(code, pq.nbits);
for (size_t m = 0; m < pq.M; m++) {
uint64_t c = decoder.decode();
memcpy(x + m * pq.dsub, pq.get_centroids(m, c), sizeof(float) * pq.dsub);
}
}
void ProductQuantizer::decode (const uint8_t *code, float *x) const {
switch (nbits) {
case 8:
faiss::decode<PQDecoder8>(*this, code, x);
break;
case 16:
faiss::decode<PQDecoder16>(*this, code, x);
break;
default:
faiss::decode<PQDecoderGeneric>(*this, code, x);
break;
}
}
void ProductQuantizer::decode (const uint8_t *code, float *x, size_t n) const {
for (size_t i = 0; i < n; i++) {
this->decode (code + code_size * i, x + d * i);
}
}
void ProductQuantizer::compute_code_from_distance_table (const float *tab, uint8_t *code) const {
PQEncoderGeneric encoder(code, nbits);
for (size_t m = 0; m < M; m++) {
float mindis = 1e20;
uint64_t idxm = 0;
/* Find best centroid */
for (size_t j = 0; j < ksub; j++) {
float dis = *tab++;
if (dis < mindis) {
mindis = dis;
idxm = j;
}
}
encoder.encode(idxm);
}
}
void ProductQuantizer::compute_codes_with_assign_index ( const float * x, uint8_t * codes, size_t n) {
FAISS_THROW_IF_NOT (assign_index && assign_index->d == dsub);
for (size_t m = 0; m < M; m++) {
assign_index->reset ();
assign_index->add (ksub, get_centroids (m, 0));
size_t bs = 65536;
float * xslice = new float[bs * dsub];
ScopeDeleter<float> del (xslice);
idx_t *assign = new idx_t[bs];
ScopeDeleter<idx_t> del2 (assign);
for (size_t i0 = 0; i0 < n; i0 += bs) {
size_t i1 = std::min(i0 + bs, n);
for (size_t i = i0; i < i1; i++) {
memcpy (xslice + (i - i0) * dsub, x + i * d + m * dsub, dsub * sizeof(float));
}
assign_index->assign (i1 - i0, xslice, assign);
if (nbits == 8) {
uint8_t *c = codes + code_size * i0 + m;
for (size_t i = i0; i < i1; i++) {
*c = assign[i - i0];
c += M;
}
} else if (nbits == 16) {
uint16_t *c = (uint16_t*)(codes + code_size * i0 + m * 2);
for (size_t i = i0; i < i1; i++) {
*c = assign[i - i0];
c += M;
}
} else {
for (size_t i = i0; i < i1; ++i) {
uint8_t *c = codes + code_size * i + ((m * nbits) / 8);
uint8_t offset = (m * nbits) % 8;
uint64_t ass = assign[i - i0];
PQEncoderGeneric encoder(c, nbits, offset);
encoder.encode(ass);
}
}
}
}
}
void ProductQuantizer::compute_codes (const float * x, uint8_t * codes, size_t n) const {
// process by blocks to avoid using too much RAM
size_t bs = 256 * 1024;
if (n > bs) {
for (size_t i0 = 0; i0 < n; i0 += bs) {
size_t i1 = std::min(i0 + bs, n);
compute_codes (x + d * i0, codes + code_size * i0, i1 - i0);
}
return;
}
if (dsub < 16) { // simple direct computation
#pragma omp parallel for
for (size_t i = 0; i < n; i++)
compute_code (x + i * d, codes + i * code_size);
} else { // worthwile to use BLAS
float *dis_tables = new float [n * ksub * M];
ScopeDeleter<float> del (dis_tables);
compute_distance_tables (n, x, dis_tables);
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
uint8_t * code = codes + i * code_size;
const float * tab = dis_tables + i * ksub * M;
compute_code_from_distance_table (tab, code);
}
}
}
void ProductQuantizer::compute_distance_table (const float * x, float * dis_table) const {
size_t m;
for (m = 0; m < M; m++) {
fvec_L2sqr_ny (dis_table + m * ksub, x + m * dsub, get_centroids(m, 0),dsub, ksub);
}
}
void ProductQuantizer::compute_inner_prod_table (const float * x, float * dis_table) const {
size_t m;
for (m = 0; m < M; m++) {
fvec_inner_products_ny (dis_table + m * ksub, x + m * dsub, get_centroids(m, 0), dsub, ksub);
}
}
void ProductQuantizer::compute_distance_tables (size_t nx, const float * x, float * dis_tables) const {
if (dsub < 16) {
#pragma omp parallel for
for (size_t i = 0; i < nx; i++) {
compute_distance_table (x + i * d, dis_tables + i * ksub * M);
}
} else { // use BLAS
for (int m = 0; m < M; m++) {
pairwise_L2sqr (dsub, nx, x + dsub * m, ksub, centroids.data() + m * dsub * ksub,
dis_tables + ksub * m, d, dsub, ksub * M);
}
}
}
void ProductQuantizer::compute_inner_prod_tables (size_t nx, const float * x, float * dis_tables) const {
if (dsub < 16) {
#pragma omp parallel for
for (size_t i = 0; i < nx; i++) {
compute_inner_prod_table (x + i * d, dis_tables + i * ksub * M);
}
} else { // use BLAS
// compute distance tables
for (int m = 0; m < M; m++) {
FINTEGER ldc = ksub * M, nxi = nx, ksubi = ksub, dsubi = dsub, di = d;
float one = 1.0, zero = 0;
sgemm_ ("Transposed", "Not transposed", &ksubi, &nxi, &dsubi,
&one, ¢roids [m * dsub * ksub], &dsubi,
x + dsub * m, &di, &zero, dis_tables + ksub * m, &ldc);
}
}
}
template <class C>
static void pq_knn_search_with_tables ( const ProductQuantizer& pq, size_t nbits,
const float *dis_tables, const uint8_t * codes,
const size_t ncodes, HeapArray<C> * res, bool init_finalize_heap)
{
size_t k = res->k, nx = res->nh;
size_t ksub = pq.ksub, M = pq.M;
#pragma omp parallel for
for (size_t i = 0; i < nx; i++) {
/* query preparation for asymmetric search: compute look-up tables */
const float* dis_table = dis_tables + i * ksub * M;
/* Compute distances and keep smallest values */
int64_t * __restrict heap_ids = res->ids + i * k;
float * __restrict heap_dis = res->val + i * k;
if (init_finalize_heap) {
heap_heapify<C> (k, heap_dis, heap_ids);
}
switch (nbits) {
case 8:
pq_estimators_from_tables<uint8_t, C> (pq, codes, ncodes, dis_table, k, heap_dis, heap_ids);
break;
case 16:
pq_estimators_from_tables<uint16_t, C> (pq,(uint16_t*)codes, ncodes, dis_table,k, heap_dis, heap_ids);
break;
default:
pq_estimators_from_tables_generic<C> (pq, nbits, codes, ncodes, dis_table, k, heap_dis, heap_ids);
break;
}
if (init_finalize_heap) {
heap_reorder<C> (k, heap_dis, heap_ids);
}
}
}
void ProductQuantizer::search (const float * __restrict x, size_t nx, const uint8_t * codes, const size_t ncodes, float_maxheap_array_t * res, bool init_finalize_heap) const {
FAISS_THROW_IF_NOT (nx == res->nh);
std::unique_ptr<float[]> dis_tables(new float [nx * ksub * M]);
compute_distance_tables (nx, x, dis_tables.get());
pq_knn_search_with_tables<CMax<float, int64_t>> (*this, nbits, dis_tables.get(), codes, ncodes, res, init_finalize_heap);
}
void ProductQuantizer::search_ip (const float * __restrict x, size_t nx, const uint8_t * codes, const size_t ncodes, float_minheap_array_t * res, bool init_finalize_heap) const {
FAISS_THROW_IF_NOT (nx == res->nh);
std::unique_ptr<float[]> dis_tables(new float [nx * ksub * M]);
compute_inner_prod_tables (nx, x, dis_tables.get());
pq_knn_search_with_tables<CMin<float, int64_t> > (*this, nbits, dis_tables.get(), codes, ncodes, res, init_finalize_heap);
}
static float sqr (float x) {
return x * x;
}
void ProductQuantizer::compute_sdc_table () {
sdc_table.resize (M * ksub * ksub);
for (int m = 0; m < M; m++) {
const float *cents = centroids.data() + m * ksub * dsub;
float * dis_tab = sdc_table.data() + m * ksub * ksub;
// TODO optimize with BLAS
for (int i = 0; i < ksub; i++) {
const float *centi = cents + i * dsub;
for (int j = 0; j < ksub; j++) {
float accu = 0;
const float *centj = cents + j * dsub;
for (int k = 0; k < dsub; k++)
accu += sqr (centi[k] - centj[k]);
dis_tab [i + j * ksub] = accu;
}
}
}
}
void ProductQuantizer::search_sdc (const uint8_t * qcodes, size_t nq, const uint8_t * bcodes, const size_t nb, float_maxheap_array_t * res, bool init_finalize_heap) const {
FAISS_THROW_IF_NOT (sdc_table.size() == M * ksub * ksub);
FAISS_THROW_IF_NOT (nbits == 8);
size_t k = res->k;
#pragma omp parallel for
for (size_t i = 0; i < nq; i++) {
/* Compute distances and keep smallest values */
idx_t * heap_ids = res->ids + i * k;
float * heap_dis = res->val + i * k;
const uint8_t * qcode = qcodes + i * code_size;
if (init_finalize_heap)
maxheap_heapify (k, heap_dis, heap_ids);
const uint8_t * bcode = bcodes;
for (size_t j = 0; j < nb; j++) {
float dis = 0;
const float * tab = sdc_table.data();
for (int m = 0; m < M; m++) {
dis += tab[bcode[m] + qcode[m] * ksub];
tab += ksub * ksub;
}
if (dis < heap_dis[0]) {
maxheap_pop (k, heap_dis, heap_ids);
maxheap_push (k, heap_dis, heap_ids, dis, j);
}
bcode += code_size;
}
if (init_finalize_heap)
maxheap_reorder (k, heap_dis, heap_ids);
}
}
} // namespace faiss
4.3 Index其他文件
4.3.1 MetricType.h文件
#ifndef FAISS_METRIC_TYPE_H
#define FAISS_METRIC_TYPE_H
namespace faiss {
/// The metric space for vector comparison for Faiss indices and algorithms.
///
/// Most algorithms support both inner product and L2, with the flat
/// (brute-force) indices supporting additional metric types for vector
/// comparison.
enum MetricType {
METRIC_INNER_PRODUCT = 0, ///< maximum inner product search
METRIC_L2 = 1, ///< squared L2 search
METRIC_L1, ///< L1 (aka cityblock)
METRIC_Linf, ///< infinity distance
METRIC_Lp, ///< L_p distance, p is given by a faiss::Index
/// metric_arg
/// some additional metrics defined in scipy.spatial.distance
METRIC_Canberra = 20,
METRIC_BrayCurtis,
METRIC_JensenShannon,
};
}
#endif
4.3.2 VectorTransform.h和VectorTransform.cpp文件
4.3.2.1 VectorTransform.h文件
4.3.2.2 VectorTransform.cpp文件
4.3.2.3 test_VectorTransform.cpp文件
4.3.3 Clustering.h和Clustering.cpp文件
此文件主要描述k-means的方法: kmeans_clustering,主要使用的是IndexFlatL2, 另外定义了ClusteringParameters(定义参数),ClusteringIterationStats(定义状态)和Clustering(主要的类)。
4.3.3.1 Clustering.h文件
#ifndef FAISS_CLUSTERING_H
#define FAISS_CLUSTERING_H
#include <Index.h>
#include <vector>
namespace faiss {
/** Class for the clustering parameters. Can be passed to the
* constructor of the Clustering object. */
struct ClusteringParameters {
int niter; ///< clustering iterations
int nredo; ///< redo clustering this many times and keep best
bool verbose;
bool spherical; ///< do we want normalized centroids?
bool int_centroids; ///< round centroids coordinates to integer
bool update_index; ///< re-train index after each iteration?
bool frozen_centroids; ///< use the centroids provided as input and do not change them during iterations
int min_points_per_centroid; ///< otherwise you get a warning
int max_points_per_centroid; ///< to limit size of dataset
int seed; ///< seed for the random number generator
size_t decode_block_size; ///< how many vectors at a time to decode
/// sets reasonable defaults
ClusteringParameters ();
};
struct ClusteringIterationStats {
float obj; ///< objective values (sum of distances reported by index)
double time; ///< seconds for iteration
double time_search; ///< seconds for just search
double imbalance_factor; ///< imbalance factor of iteration
int nsplit; ///< number of cluster splits
};
/** K-means clustering based on assignment - centroid update iterations
*
* The clustering is based on an Index object that assigns training
* points to the centroids. Therefore, at each iteration the centroids
* are added to the index.
*
* On output, the centoids table is set to the latest version
* of the centroids and they are also added to the index. If the
* centroids table it is not empty on input, it is also used for
* initialization.
*
*/
struct Clustering: ClusteringParameters {
typedef Index::idx_t idx_t;
size_t d; ///< dimension of the vectors
size_t k; ///< nb of centroids
/** centroids (k * d)
* if centroids are set on input to train, they will be used as initialization
*/
std::vector<float> centroids;
/// stats at every iteration of clustering
std::vector<ClusteringIterationStats> iteration_stats;
Clustering (int d, int k);
Clustering (int d, int k, const ClusteringParameters &cp);
/** run k-means training
*
* @param x training vectors, size n * d
* @param index index used for assignment
* @param x_weights weight associated to each vector: NULL or size n
*/
virtual void train (idx_t n, const float * x, faiss::Index & index, const float *x_weights = nullptr);
/** run with encoded vectors
*
* win addition to train()'s parameters takes a codec as parameter
* to decode the input vectors.
*
* @param codec codec used to decode the vectors (nullptr = vectors are in fact floats)
*/
void train_encoded (idx_t nx, const uint8_t *x_in,const Index * codec, Index & index, const float *weights = nullptr);
/// Post-process the centroids after each centroid update.
/// includes optional L2 normalization and nearest integer rounding
void post_process_centroids ();
virtual ~Clustering() {}
};
/** simplified interface
*
* @param d dimension of the data
* @param n nb of training vectors
* @param k nb of output centroids
* @param x training set (size n * d)
* @param centroids output centroids (size k * d)
* @return final quantization error
*/
float kmeans_clustering (size_t d, size_t n, size_t k, const float *x, float *centroids);
}
#endif
4.3.3.2 Clustering.cpp文件
#include <Clustering.h>
#include <impl/AuxIndexStructures.h>
#include <cmath>
#include <cstdio>
#include <cstring>
#include <omp.h>
#include <utils/utils.h>
#include <utils/random.h>
#include <utils/distances.h>
#include <impl/FaissAssert.h>
#include <IndexFlat.h>
namespace faiss {
ClusteringParameters::ClusteringParameters ():
niter(25), nredo(1), verbose(false), spherical(false),
int_centroids(false), update_index(false), frozen_centroids(false),
min_points_per_centroid(39), max_points_per_centroid(256),
seed(1234), decode_block_size(32768)
{}
// 39 corresponds to 10000 / 256 -> to avoid warnings on PQ tests with randu10k
Clustering::Clustering (int d, int k): d(d), k(k) {}
Clustering::Clustering (int d, int k, const ClusteringParameters &cp):
ClusteringParameters (cp), d(d), k(k) {}
static double imbalance_factor (int n, int k, int64_t *assign) {
std::vector<int> hist(k, 0);
for (int i = 0; i < n; i++)
hist[assign[i]]++;
double tot = 0, uf = 0;
for (int i = 0 ; i < k ; i++) {
tot += hist[i];
uf += hist[i] * (double) hist[i];
}
uf = uf * k / (tot * tot);
return uf;
}
void Clustering::post_process_centroids () {
if (spherical) {
fvec_renorm_L2 (d, k, centroids.data());
}
if (int_centroids) {
for (size_t i = 0; i < centroids.size(); i++)
centroids[i] = roundf (centroids[i]);
}
}
void Clustering::train (idx_t nx, const float *x_in, Index & index, const float *weights) {
train_encoded (nx, reinterpret_cast<const uint8_t *>(x_in), nullptr, index, weights);
}
namespace {
using idx_t = Clustering::idx_t;
idx_t subsample_training_set( const Clustering &clus, idx_t nx, const uint8_t *x, size_t line_size, const float * weights, uint8_t **x_out, float **weights_out){
if (clus.verbose) {
printf("Sampling a subset of %ld / %ld for training\n", clus.k * clus.max_points_per_centroid, nx);
}
std::vector<int> perm (nx);
rand_perm (perm.data (), nx, clus.seed);
nx = clus.k * clus.max_points_per_centroid;
uint8_t * x_new = new uint8_t [nx * line_size];
*x_out = x_new;
for (idx_t i = 0; i < nx; i++) {
memcpy (x_new + i * line_size, x + perm[i] * line_size, line_size);
}
if (weights) {
float *weights_new = new float[nx];
for (idx_t i = 0; i < nx; i++) {
weights_new[i] = weights[perm[i]];
}
*weights_out = weights_new;
} else {
*weights_out = nullptr;
}
return nx;
}
/** compute centroids as (weighted) sum of training points
*
* @param x training vectors, size n * code_size (from codec)
* @param codec how to decode the vectors (if NULL then cast to float*)
* @param weights per-training vector weight, size n (or NULL)
* @param assign nearest centroid for each training vector, size n
* @param k_frozen do not update the k_frozen first centroids
* @param centroids centroid vectors (output only), size k * d
* @param hassign histogram of assignments per centroid (size k),
* should be 0 on input
*/
void compute_centroids (size_t d, size_t k, size_t n, size_t k_frozen, const uint8_t * x, const Index *codec,
const int64_t * assign, const float * weights, float * hassign,float * centroids){
k -= k_frozen;
centroids += k_frozen * d;
memset (centroids, 0, sizeof(*centroids) * d * k);
size_t line_size = codec ? codec->sa_code_size() : d * sizeof (float);
#pragma omp parallel
{
int nt = omp_get_num_threads();
int rank = omp_get_thread_num();
// this thread is taking care of centroids c0:c1
size_t c0 = (k * rank) / nt;
size_t c1 = (k * (rank + 1)) / nt;
std::vector<float> decode_buffer (d);
for (size_t i = 0; i < n; i++) {
int64_t ci = assign[i];
assert (ci >= 0 && ci < k + k_frozen);
ci -= k_frozen;
if (ci >= c0 && ci < c1) {
float * c = centroids + ci * d;
const float * xi;
if (!codec) {
xi = reinterpret_cast<const float*>(x + i * line_size);
} else {
float *xif = decode_buffer.data();
codec->sa_decode (1, x + i * line_size, xif);
xi = xif;
}
if (weights) {
float w = weights[i];
hassign[ci] += w;
for (size_t j = 0; j < d; j++) {
c[j] += xi[j] * w;
}
} else {
hassign[ci] += 1.0;
for (size_t j = 0; j < d; j++) {
c[j] += xi[j];
}
}
}
}
}
#pragma omp parallel for
for (size_t ci = 0; ci < k; ci++) {
if (hassign[ci] == 0) {
continue;
}
float norm = 1 / hassign[ci];
float * c = centroids + ci * d;
for (size_t j = 0; j < d; j++) {
c[j] *= norm;
}
}
}
// a bit above machine epsilon for float16
#define EPS (1 / 1024.)
/** Handle empty clusters by splitting larger ones.
*
* It works by slightly changing the centroids to make 2 clusters from
* a single one. Takes the same arguements as compute_centroids.
*
* @return nb of spliting operations (larger is worse)
*/
int split_clusters (size_t d, size_t k, size_t n, size_t k_frozen, float * hassign, float * centroids) {
k -= k_frozen;
centroids += k_frozen * d;
/* Take care of void clusters */
size_t nsplit = 0;
RandomGenerator rng (1234);
for (size_t ci = 0; ci < k; ci++) {
if (hassign[ci] == 0) { /* need to redefine a centroid */
size_t cj;
for (cj = 0; 1; cj = (cj + 1) % k) {
/* probability to pick this cluster for split */
float p = (hassign[cj] - 1.0) / (float) (n - k);
float r = rng.rand_float ();
if (r < p) {
break; /* found our cluster to be split */
}
}
memcpy (centroids+ci*d, centroids+cj*d, sizeof(*centroids) * d);
/* small symmetric pertubation */
for (size_t j = 0; j < d; j++) {
if (j % 2 == 0) {
centroids[ci * d + j] *= 1 + EPS;
centroids[cj * d + j] *= 1 - EPS;
} else {
centroids[ci * d + j] *= 1 - EPS;
centroids[cj * d + j] *= 1 + EPS;
}
}
/* assume even split of the cluster */
hassign[ci] = hassign[cj] / 2;
hassign[cj] -= hassign[ci];
nsplit++;
}
}
return nsplit;
}
};
void Clustering::train_encoded (idx_t nx, const uint8_t *x_in, const Index * codec, Index & index, const float *weights) {
FAISS_THROW_IF_NOT_FMT (nx >= k,
"Number of training points (%ld) should be at least "
"as large as number of clusters (%ld)", nx, k);
FAISS_THROW_IF_NOT_FMT ((!codec || codec->d == d),
"Codec dimension %d not the same as data dimension %d",
int(codec->d), int(d));
FAISS_THROW_IF_NOT_FMT (index.d == d,
"Index dimension %d not the same as data dimension %d",
int(index.d), int(d));
double t0 = getmillisecs();
if (!codec) {
// Check for NaNs in input data. Normally it is the user's
// responsibility, but it may spare us some hard-to-debug reports.
const float *x = reinterpret_cast<const float *>(x_in);
for (size_t i = 0; i < nx * d; i++) {
FAISS_THROW_IF_NOT_MSG (finite (x[i]), "input contains NaN's or Inf's");
}
}
const uint8_t *x = x_in;
std::unique_ptr<uint8_t []> del1;
std::unique_ptr<float []> del3;
size_t line_size = codec ? codec->sa_code_size() : sizeof(float) * d;
if (nx > k * max_points_per_centroid) {
uint8_t *x_new;
float *weights_new;
nx = subsample_training_set (*this, nx, x, line_size, weights, &x_new, &weights_new);
del1.reset (x_new); x = x_new;
del3.reset (weights_new); weights = weights_new;
} else if (nx < k * min_points_per_centroid) {
fprintf (stderr,
"WARNING clustering %ld points to %ld centroids: "
"please provide at least %ld training points\n",
nx, k, idx_t(k) * min_points_per_centroid);
}
if (nx == k) {
// this is a corner case, just copy training set to clusters
if (verbose) {
printf("Number of training points (%ld) same as number of clusters, just copying\n", nx);
}
centroids.resize (d * k);
if (!codec) {
memcpy (centroids.data(), x_in, sizeof (float) * d * k);
} else {
codec->sa_decode (nx, x_in, centroids.data());
}
// one fake iteration...
ClusteringIterationStats stats = { 0.0, 0.0, 0.0, 1.0, 0 };
iteration_stats.push_back (stats);
index.reset();
index.add(k, centroids.data());
return;
}
if (verbose) {
printf("Clustering %d points in %ldD to %ld clusters, redo %d times, %d iterations\n", int(nx), d, k, nredo, niter);
if (codec) {
printf("Input data encoded in %ld bytes per vector\n",codec->sa_code_size ());
}
}
std::unique_ptr<idx_t []> assign(new idx_t[nx]);
std::unique_ptr<float []> dis(new float[nx]);
// remember best iteration for redo
float best_err = HUGE_VALF;
std::vector<ClusteringIterationStats> best_obj;
std::vector<float> best_centroids;
// support input centroids
FAISS_THROW_IF_NOT_MSG (centroids.size() % d == 0,"size of provided input centroids not a multiple of dimension");
size_t n_input_centroids = centroids.size() / d;
if (verbose && n_input_centroids > 0) {
printf (" Using %zd centroids provided as input (%sfrozen)\n", n_input_centroids, frozen_centroids ? "" : "not ");
}
double t_search_tot = 0;
if (verbose) {
printf(" Preprocessing in %.2f s\n", (getmillisecs() - t0) / 1000.);
}
t0 = getmillisecs();
// temporary buffer to decode vectors during the optimization
std::vector<float> decode_buffer (codec ? d * decode_block_size : 0);
for (int redo = 0; redo < nredo; redo++) {
if (verbose && nredo > 1) {
printf("Outer iteration %d / %d\n", redo, nredo);
}
// initialize (remaining) centroids with random points from the dataset
centroids.resize (d * k);
std::vector<int> perm (nx);
rand_perm (perm.data(), nx, seed + 1 + redo * 15486557L);
if (!codec) {
for (int i = n_input_centroids; i < k ; i++) {
memcpy (¢roids[i * d], x + perm[i] * line_size, line_size);
}
} else {
for (int i = n_input_centroids; i < k ; i++) {
codec->sa_decode (1, x + perm[i] * line_size, ¢roids[i * d]);
}
}
post_process_centroids ();
// prepare the index
if (index.ntotal != 0) {
index.reset();
}
if (!index.is_trained) {
index.train (k, centroids.data());
}
index.add (k, centroids.data());
// k-means iterations
float err = 0;
for (int i = 0; i < niter; i++) {
double t0s = getmillisecs();
if (!codec) {
index.search (nx, reinterpret_cast<const float *>(x), 1, dis.get(), assign.get());
} else {
// search by blocks of decode_block_size vectors
size_t code_size = codec->sa_code_size ();
for (size_t i0 = 0; i0 < nx; i0 += decode_block_size) {
size_t i1 = i0 + decode_block_size;
if (i1 > nx) { i1 = nx; }
codec->sa_decode (i1 - i0, x + code_size * i0, decode_buffer.data ());
index.search (i1 - i0, decode_buffer.data (), 1, dis.get() + i0, assign.get() + i0);
}
}
InterruptCallback::check();
t_search_tot += getmillisecs() - t0s;
// accumulate error
err = 0;
for (int j = 0; j < nx; j++) {
err += dis[j];
}
// update the centroids
std::vector<float> hassign (k);
size_t k_frozen = frozen_centroids ? n_input_centroids : 0;
compute_centroids (d, k, nx, k_frozen, x, codec, assign.get(), weights, hassign.data(), centroids.data());
int nsplit = split_clusters (d, k, nx, k_frozen, hassign.data(), centroids.data());
// collect statistics
ClusteringIterationStats stats = { err, (getmillisecs() - t0) / 1000.0, t_search_tot / 1000, imbalance_factor (nx, k, assign.get()), nsplit };
iteration_stats.push_back(stats);
if (verbose) {
printf (" Iteration %d (%.2f s, search %.2f s): objective=%g imbalance=%.3f nsplit=%d \r",
i, stats.time, stats.time_search, stats.obj, stats.imbalance_factor, nsplit);
fflush (stdout);
}
post_process_centroids ();
// add centroids to index for the next iteration (or for output)
index.reset ();
if (update_index) {
index.train (k, centroids.data());
}
index.add (k, centroids.data());
InterruptCallback::check ();
}
if (verbose) printf("\n");
if (nredo > 1) {
if (err < best_err) {
if (verbose) {
printf ("Objective improved: keep new clusters\n");
}
best_centroids = centroids;
best_obj = iteration_stats;
best_err = err;
}
index.reset ();
}
}
if (nredo > 1) {
centroids = best_centroids;
iteration_stats = best_obj;
index.reset();
index.add(k, best_centroids.data());
}
}
float kmeans_clustering (size_t d, size_t n, size_t k, const float *x, float *centroids) {
Clustering clus (d, k);
clus.verbose = d * n * k > (1L << 30);
// display logs if > 1Gflop per iteration
IndexFlatL2 index (d);
clus.train (n, x, index);
memcpy(centroids, clus.centroids.data(), sizeof(*centroids) * d * k);
return clus.iteration_stats.back().obj;
}
} // namespace faiss
4.3.3.3 test_clustering.cpp文件
#include<Clustering.h>
int main(){
int d = 10; // dimension
int nb = 1000; // database size
int k=20;
float *xb = new float[d * nb];
for(int i = 0; i < d*nb; i++) {
xb[i] = drand48();
}
float *centroids = new float[d * k];
float error = faiss::kmeans_clustering(d, nb, k, xb, centroids);
printf("Error: %f.\nCentroids:\n\t",error);
for(int i=0;i<k;i++){
for(int j=0;j<d;j++){
printf("%f ",centroids[i*d+j]);
}
printf("\n\t");
}
delete [] centroids;
delete [] xb;
return 0;
}
4.3.4 ProductQuantizer.h,ProductQuantizer-inl.h和ProductQuantizer.cpp
- ProductQuantizer.h文件
#ifndef FAISS_PRODUCT_QUANTIZER_H
#define FAISS_PRODUCT_QUANTIZER_H
#include <stdint.h>
#include <vector>
#include <faiss/Clustering.h>
#include <faiss/utils/Heap.h>
namespace faiss {
/** Product Quantizer. Implemented only for METRIC_L2 */
struct ProductQuantizer {
using idx_t = Index::idx_t;
size_t d; ///< size of the input vectors
size_t M; ///< number of subquantizers
size_t nbits; ///< number of bits per quantization index
// values derived from the above
size_t dsub; ///< dimensionality of each subvector
size_t code_size; ///< bytes per indexed vector
size_t ksub; ///< number of centroids for each subquantizer
bool verbose; ///< verbose during training?
/// initialization
enum train_type_t {
Train_default,
Train_hot_start, ///< the centroids are already initialized
Train_shared, ///< share dictionary accross PQ segments
Train_hypercube, ///< intialize centroids with nbits-D hypercube
Train_hypercube_pca, ///< intialize centroids with nbits-D hypercube
};
train_type_t train_type;
ClusteringParameters cp; ///< parameters used during clustering
/// if non-NULL, use this index for assignment (should be of size d / M)
Index *assign_index;
/// Centroid table, size M * ksub * dsub
std::vector<float> centroids;
/// return the centroids associated with subvector m
float * get_centroids (size_t m, size_t i) {
return ¢roids [(m * ksub + i) * dsub];
}
const float * get_centroids (size_t m, size_t i) const {
return ¢roids [(m * ksub + i) * dsub];
}
// Train the product quantizer on a set of points. A clustering
// can be set on input to define non-default clustering parameters
void train (int n, const float *x);
ProductQuantizer(size_t d, /* dimensionality of the input vectors */
size_t M, /* number of subquantizers */
size_t nbits); /* number of bit per subvector index */
ProductQuantizer ();
/// compute derived values when d, M and nbits have been set
void set_derived_values ();
/// Define the centroids for subquantizer m
void set_params (const float * centroids, int m);
/// Quantize one vector with the product quantizer
void compute_code (const float * x, uint8_t * code) const ;
/// same as compute_code for several vectors
void compute_codes (const float * x, uint8_t * codes, size_t n) const ;
/// speed up code assignment using assign_index
/// (non-const because the index is changed)
void compute_codes_with_assign_index (const float * x, uint8_t * codes, size_t n);
/// decode a vector from a given code (or n vectors if third argument)
void decode (const uint8_t *code, float *x) const;
void decode (const uint8_t *code, float *x, size_t n) const;
/// If we happen to have the distance tables precomputed, this is
/// more efficient to compute the codes.
void compute_code_from_distance_table (const float *tab, uint8_t *code) const;
/** Compute distance table for one vector.
*
* The distance table for x = [x_0 x_1 .. x_(M-1)] is a M * ksub
* matrix that contains
*
* dis_table (m, j) = || x_m - c_(m, j)||^2
* for m = 0..M-1 and j = 0 .. ksub - 1
*
* where c_(m, j) is the centroid no j of sub-quantizer m.
*
* @param x input vector size d
* @param dis_table output table, size M * ksub
*/
void compute_distance_table (const float * x, float * dis_table) const;
void compute_inner_prod_table (const float * x, float * dis_table) const;
/** compute distance table for several vectors
* @param nx nb of input vectors
* @param x input vector size nx * d
* @param dis_table output table, size nx * M * ksub
*/
void compute_distance_tables (size_t nx, const float * x, float * dis_tables) const;
void compute_inner_prod_tables (size_t nx, const float * x, float * dis_tables) const;
/** perform a search (L2 distance)
* @param x query vectors, size nx * d
* @param nx nb of queries
* @param codes database codes, size ncodes * code_size
* @param ncodes nb of nb vectors
* @param res heap array to store results (nh == nx)
* @param init_finalize_heap initialize heap (input) and sort (output)?
*/
void search (const float * x, size_t nx, const uint8_t * codes,const size_t ncodes,
float_maxheap_array_t *res, bool init_finalize_heap = true) const;
/** same as search, but with inner product similarity */
void search_ip (const float * x, size_t nx, const uint8_t * codes, const size_t ncodes,
float_minheap_array_t *res, bool init_finalize_heap = true) const;
/// Symmetric Distance Table
std::vector<float> sdc_table;
// intitialize the SDC table from the centroids
void compute_sdc_table ();
void search_sdc (const uint8_t * qcodes, size_t nq, const uint8_t * bcodes, const size_t ncodes,
float_maxheap_array_t * res, bool init_finalize_heap = true) const;
};
/*************************************************
* Objects to encode / decode strings of bits
*************************************************/
struct PQEncoderGeneric {
uint8_t *code; ///< code for this vector
uint8_t offset;
const int nbits; ///< number of bits per subquantizer index
uint8_t reg;
PQEncoderGeneric(uint8_t *code, int nbits, uint8_t offset = 0);
void encode(uint64_t x);
~PQEncoderGeneric();
};
struct PQEncoder8 {
uint8_t *code;
PQEncoder8(uint8_t *code, int nbits);
void encode(uint64_t x);
};
struct PQEncoder16 {
uint16_t *code;
PQEncoder16(uint8_t *code, int nbits);
void encode(uint64_t x);
};
struct PQDecoderGeneric {
const uint8_t *code;
uint8_t offset;
const int nbits;
const uint64_t mask;
uint8_t reg;
PQDecoderGeneric(const uint8_t *code, int nbits);
uint64_t decode();
};
struct PQDecoder8 {
const uint8_t *code;
PQDecoder8(const uint8_t *code, int nbits);
uint64_t decode();
};
struct PQDecoder16 {
const uint16_t *code;
PQDecoder16(const uint8_t *code, int nbits);
uint64_t decode();
};
} // namespace faiss
#include <faiss/impl/ProductQuantizer-inl.h>
#endif
- ProductQuantizer-inl.h文件
namespace faiss {
inline PQEncoderGeneric::PQEncoderGeneric(uint8_t *code, int nbits, uint8_t offset)
: code(code), offset(offset), nbits(nbits), reg(0) {
assert(nbits <= 64);
if (offset > 0) {
reg = (*code & ((1 << offset) - 1));
}
}
inline void PQEncoderGeneric::encode(uint64_t x) {
reg |= (uint8_t)(x << offset);
x >>= (8 - offset);
if (offset + nbits >= 8) {
*code++ = reg;
for (int i = 0; i < (nbits - (8 - offset)) / 8; ++i) {
*code++ = (uint8_t)x;
x >>= 8;
}
offset += nbits;
offset &= 7;
reg = (uint8_t)x;
} else {
offset += nbits;
}
}
inline PQEncoderGeneric::~PQEncoderGeneric() {
if (offset > 0) {
*code = reg;
}
}
inline PQEncoder8::PQEncoder8(uint8_t *code, int nbits) : code(code) {
assert(8 == nbits);
}
inline void PQEncoder8::encode(uint64_t x) {
*code++ = (uint8_t)x;
}
inline PQEncoder16::PQEncoder16(uint8_t *code, int nbits) : code((uint16_t *)code) {
assert(16 == nbits);
}
inline void PQEncoder16::encode(uint64_t x) {
*code++ = (uint16_t)x;
}
inline PQDecoderGeneric::PQDecoderGeneric(const uint8_t *code, int nbits)
: code(code), offset(0), nbits(nbits), mask((1ull << nbits) - 1), reg(0) {
assert(nbits <= 64);
}
inline uint64_t PQDecoderGeneric::decode() {
if (offset == 0) {
reg = *code;
}
uint64_t c = (reg >> offset);
if (offset + nbits >= 8) {
uint64_t e = 8 - offset;
++code;
for (int i = 0; i < (nbits - (8 - offset)) / 8; ++i) {
c |= ((uint64_t)(*code++) << e);
e += 8;
}
offset += nbits;
offset &= 7;
if (offset > 0) {
reg = *code;
c |= ((uint64_t)reg << e);
}
} else {
offset += nbits;
}
return c & mask;
}
inline PQDecoder8::PQDecoder8(const uint8_t *code, int nbits) : code(code) {
assert(8 == nbits);
}
inline uint64_t PQDecoder8::decode() {
return (uint64_t)(*code++);
}
inline PQDecoder16::PQDecoder16(const uint8_t *code, int nbits) : code((uint16_t *)code) {
assert(16 == nbits);
}
inline uint64_t PQDecoder16::decode() {
return (uint64_t)(*code++);
}
} // namespace faiss
4.4 Index文件
4.4.1 Index.h和Index.cpp文件
定义了Index的基础变量:
d: 向量维度
ntotal:向量的数量
is_trained: 是否已训练
metric_type: 距离的类型
metric_arg: 距离指标的参数
Index的基础函数:
Index(idx_t d = 0, MetricType metric = METRIC_L2): d(d),ntotal(0), verbose(false), is_trained(true), metric_type (metric), metric_arg(0): 构造函数
~Index (): 析构函数
add (idx_t n, const float *x) = 0: 添加数据
virtual void add_with_ids (idx_t n, const float * x, const idx_t *xids): 带有ID添加数据
search (idx_t n, const float x, idx_t k, float distances, idx_t *labels) const = 0: 搜索数据
range_search (idx_t n, const float x, float radius, RangeSearchResult result) const: 区域搜索数据
4.4.1.1 Index.h文件
#ifndef FAISS_INDEX_H
#define FAISS_INDEX_H
#include <MetricType.h>
#include <cstdio>
#include <typeinfo>
#include <string>
#include <sstream>
#define FAISS_VERSION_MAJOR 1
#define FAISS_VERSION_MINOR 6
#define FAISS_VERSION_PATCH 3
/**
* @namespace faiss
*
* Throughout the library, vectors are provided as float * pointers.
* Most algorithms can be optimized when several vectors are processed
* (added/searched) together in a batch. In this case, they are passed
* in as a matrix. When n vectors of size d are provided as float * x,
* component j of vector i is
* x[ i * d + j ]
* where 0 <= i < n and 0 <= j < d. In other words, matrices are
* always compact. When specifying the size of the matrix, we call it
* an n*d matrix, which implies a row-major storage.
*/
namespace faiss {
/// Forward declarations see AuxIndexStructures.h
struct IDSelector;
struct RangeSearchResult;
struct DistanceComputer;
/** Abstract structure for an index, supports adding vectors and searching them.
*
* All vectors provided at add or search time are 32-bit float arrays,
* although the internal representation may vary.
*/
struct Index {
using idx_t = int64_t; ///< all indices are this type
using component_t = float;
using distance_t = float;
int d; ///< vector dimension
idx_t ntotal; ///< total nb of indexed vectors
bool verbose; ///< verbosity level
/// set if the Index does not require training, or if training is done already
bool is_trained;
/// type of metric this index uses for search
MetricType metric_type;
float metric_arg; ///< argument of the metric type
explicit Index (idx_t d = 0, MetricType metric = METRIC_L2): d(d),
ntotal(0), verbose(false), is_trained(true), metric_type (metric), metric_arg(0) {}
virtual ~Index ();
/** Perform training on a representative set of vectors
*
* @param n nb of training vectors
* @param x training vecors, size n * d
*/
virtual void train(idx_t n, const float* x);
/** Add n vectors of dimension d to the index.
*
* Vectors are implicitly assigned labels ntotal .. ntotal + n - 1
* This function slices the input vectors in chuncks smaller than
* blocksize_add and calls add_core.
* @param x input matrix, size n * d
*/
virtual void add (idx_t n, const float *x) = 0;
/** Same as add, but stores xids instead of sequential ids.
*
* The default implementation fails with an assertion, as it is
* not supported by all indexes.
*
* @param xids if non-null, ids to store for the vectors (size n)
*/
virtual void add_with_ids (idx_t n, const float * x, const idx_t *xids);
/** query n vectors of dimension d to the index.
*
* return at most k vectors. If there are not enough results for a
* query, the result array is padded with -1s.
*
* @param x input vectors to search, size n * d
* @param labels output labels of the NNs, size n*k
* @param distances output pairwise distances, size n*k
*/
virtual void search (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels) const = 0;
/** query n vectors of dimension d to the index.
*
* return all vectors with distance < radius. Note that many
* indexes do not implement the range_search (only the k-NN search
* is mandatory).
*
* @param x input vectors to search, size n * d
* @param radius search radius
* @param result result table
*/
virtual void range_search (idx_t n, const float *x, float radius, RangeSearchResult *result) const;
/** return the indexes of the k vectors closest to the query x.
*
* This function is identical as search but only return labels of neighbors.
* @param x input vectors to search, size n * d
* @param labels output labels of the NNs, size n*k
*/
void assign (idx_t n, const float * x, idx_t * labels, idx_t k = 1);
/// removes all elements from the database.
virtual void reset() = 0;
/// removes IDs from the index. Not supported by all indexes. Returns the number of elements removed.
virtual size_t remove_ids (const IDSelector & sel);
/** Reconstruct a stored vector (or an approximation if lossy coding)
*
* this function may not be defined for some indexes
* @param key id of the vector to reconstruct
* @param recons reconstucted vector (size d)
*/
virtual void reconstruct (idx_t key, float * recons) const;
/** Reconstruct vectors i0 to i0 + ni - 1
*
* this function may not be defined for some indexes
* @param recons reconstucted vector (size ni * d)
*/
virtual void reconstruct_n (idx_t i0, idx_t ni, float *recons) const;
/** Similar to search, but also reconstructs the stored vectors (or an
* approximation in the case of lossy coding) for the search results.
*
* If there are not enough results for a query, the resulting arrays
* is padded with -1s.
*
* @param recons reconstructed vectors size (n, k, d)
**/
virtual void search_and_reconstruct (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels, float *recons) const;
/** Computes a residual vector after indexing encoding.
*
* The residual vector is the difference between a vector and the
* reconstruction that can be decoded from its representation in
* the index. The residual can be used for multiple-stage indexing
* methods, like IndexIVF's methods.
*
* @param x input vector, size d
* @param residual output residual vector, size d
* @param key encoded index, as returned by search and assign
*/
virtual void compute_residual (const float * x, float * residual, idx_t key) const;
/** Computes a residual vector after indexing encoding (batch form).
* Equivalent to calling compute_residual for each vector.
*
* The residual vector is the difference between a vector and the
* reconstruction that can be decoded from its representation in
* the index. The residual can be used for multiple-stage indexing
* methods, like IndexIVF's methods.
*
* @param n number of vectors
* @param xs input vectors, size (n x d)
* @param residuals output residual vectors, size (n x d)
* @param keys encoded index, as returned by search and assign
*/
virtual void compute_residual_n (idx_t n, const float* xs, float* residuals, const idx_t* keys) const;
/** Get a DistanceComputer (defined in AuxIndexStructures) object
* for this kind of index.
*
* DistanceComputer is implemented for indexes that support random
* access of their vectors.
*/
virtual DistanceComputer * get_distance_computer() const;
/* The standalone codec interface */
/** size of the produced codes in bytes */
virtual size_t sa_code_size () const;
/** encode a set of vectors
*
* @param n number of vectors
* @param x input vectors, size n * d
* @param bytes output encoded vectors, size n * sa_code_size()
*/
virtual void sa_encode (idx_t n, const float *x,uint8_t *bytes) const;
/** encode a set of vectors
*
* @param n number of vectors
* @param bytes input encoded vectors, size n * sa_code_size()
* @param x output vectors, size n * d
*/
virtual void sa_decode (idx_t n, const uint8_t *bytes,float *x) const;
};
}
#endif
4.4.1.2 Index.cpp文件
#include <faiss/Index.h>
#include <faiss/impl/AuxIndexStructures.h>
#include <faiss/impl/FaissAssert.h>
#include <faiss/utils/distances.h>
#include <cstring>
namespace faiss {
Index::~Index () { }
void Index::train(idx_t /*n*/, const float* /*x*/) {
// does nothing by default
}
void Index::range_search (idx_t , const float *, float, RangeSearchResult *) const {
FAISS_THROW_MSG ("range search not implemented");
}
void Index::assign (idx_t n, const float * x, idx_t * labels, idx_t k) {
float * distances = new float[n * k];
ScopeDeleter<float> del(distances);
search (n, x, k, distances, labels);
}
void Index::add_with_ids( idx_t /*n*/, const float* /*x*/, const idx_t* /*xids*/) {
FAISS_THROW_MSG ("add_with_ids not implemented for this type of index");
}
size_t Index::remove_ids(const IDSelector& /*sel*/) {
FAISS_THROW_MSG ("remove_ids not implemented for this type of index");
return -1;
}
void Index::reconstruct (idx_t, float * ) const {
FAISS_THROW_MSG ("reconstruct not implemented for this type of index");
}
void Index::reconstruct_n (idx_t i0, idx_t ni, float *recons) const {
for (idx_t i = 0; i < ni; i++) {
reconstruct (i0 + i, recons + i * d);
}
}
void Index::search_and_reconstruct (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels, float *recons) const {
search (n, x, k, distances, labels);
for (idx_t i = 0; i < n; ++i) {
for (idx_t j = 0; j < k; ++j) {
idx_t ij = i * k + j;
idx_t key = labels[ij];
float* reconstructed = recons + ij * d;
if (key < 0) {
// Fill with NaNs
memset(reconstructed, -1, sizeof(*reconstructed) * d);
} else {
reconstruct (key, reconstructed);
}
}
}
}
void Index::compute_residual (const float * x, float * residual, idx_t key) const {
reconstruct (key, residual);
for (size_t i = 0; i < d; i++) {
residual[i] = x[i] - residual[i];
}
}
void Index::compute_residual_n (idx_t n, const float* xs, float* residuals, const idx_t* keys) const {
#pragma omp parallel for
for (idx_t i = 0; i < n; ++i) {
compute_residual(&xs[i * d], &residuals[i * d], keys[i]);
}
}
size_t Index::sa_code_size () const {
FAISS_THROW_MSG ("standalone codec not implemented for this type of index");
}
void Index::sa_encode (idx_t, const float *,uint8_t *) const {
FAISS_THROW_MSG ("standalone codec not implemented for this type of index");
}
void Index::sa_decode (idx_t, const uint8_t *, float *) const {
FAISS_THROW_MSG ("standalone codec not implemented for this type of index");
}
namespace {
// storage that explicitly reconstructs vectors before computing distances
struct GenericDistanceComputer : DistanceComputer {
size_t d;
const Index& storage;
std::vector<float> buf;
const float *q;
explicit GenericDistanceComputer(const Index& storage) : storage(storage) {
d = storage.d;
buf.resize(d * 2);
}
float operator () (idx_t i) override {
storage.reconstruct(i, buf.data());
return fvec_L2sqr(q, buf.data(), d);
}
float symmetric_dis(idx_t i, idx_t j) override {
storage.reconstruct(i, buf.data());
storage.reconstruct(j, buf.data() + d);
return fvec_L2sqr(buf.data() + d, buf.data(), d);
}
void set_query(const float *x) override {
q = x;
}
};
} // namespace
DistanceComputer * Index::get_distance_computer() const {
if (metric_type == METRIC_L2) {
return new GenericDistanceComputer(*this);
} else {
FAISS_THROW_MSG ("get_distance_computer() not implemented");
}
}
}
4.4.2 IndexFlat.h和IndexFlat.cpp文件
文件定义了暴力方式的IndexFlat(支持L2,L1,Linf,Canberra,BrayCurtis,JensenShannon距离),内部主要是用knn_search,此外引申了IndexFlatIP,IndexFlatL2,偏移的IndexFlatL2BaseShift,以及两种Index混合的IndexRefineFlat和对一维优化的IndexFlat1D。
4.4.2.1 IndexFlat.h文件
#ifndef INDEX_FLAT_H
#define INDEX_FLAT_H
#include <vector>
#include <Index.h>
namespace faiss {
/// Index that stores the full vectors and performs exhaustive search
struct IndexFlat: Index {
/// database vectors, size ntotal * d
std::vector<float> xb;
explicit IndexFlat (idx_t d, MetricType metric = METRIC_L2);
void add(idx_t n, const float* x) override;
void reset() override;
void search( idx_t n, const float* x, idx_t k, float* distances, idx_t* labels) const override;
void range_search( idx_t n, const float* x, float radius, RangeSearchResult* result) const override;
void reconstruct(idx_t key, float* recons) const override;
/** compute distance with a subset of vectors
*
* @param x query vectors, size n * d
* @param labels indices of the vectors that should be compared
* for each query vector, size n * k
* @param distances
* corresponding output distances, size n * k
*/
void compute_distance_subset (idx_t n, const float *x, idx_t k, float *distances,const idx_t *labels) const;
/** remove some ids. NB that Because of the structure of the
* indexing structure, the semantics of this operation are
* different from the usual ones: the new ids are shifted */
size_t remove_ids(const IDSelector& sel) override;
IndexFlat () {}
DistanceComputer * get_distance_computer() const override;
/* The stanadlone codec interface (just memcopies in this case) */
size_t sa_code_size () const override;
void sa_encode (idx_t n, const float *x, uint8_t *bytes) const override;
void sa_decode (idx_t n, const uint8_t *bytes, float *x) const override;
};
struct IndexFlatIP:IndexFlat {
explicit IndexFlatIP (idx_t d): IndexFlat (d, METRIC_INNER_PRODUCT) {}
IndexFlatIP () {}
};
struct IndexFlatL2:IndexFlat {
explicit IndexFlatL2 (idx_t d): IndexFlat (d, METRIC_L2) {}
IndexFlatL2 () {}
};
// same as an IndexFlatL2 but a value is subtracted from each distance
struct IndexFlatL2BaseShift: IndexFlatL2 {
std::vector<float> shift;
IndexFlatL2BaseShift (idx_t d, size_t nshift, const float *shift);
void search(idx_t n, const float* x, idx_t k, float* distances, idx_t* labels) const override;
};
/** Index that queries in a base_index (a fast one) and refines the
* results with an exact search, hopefully improving the results.
*/
struct IndexRefineFlat: Index {
/// storage for full vectors
IndexFlat refine_index;
/// faster index to pre-select the vectors that should be filtered
Index *base_index;
bool own_fields; ///< should the base index be deallocated?
/// factor between k requested in search and the k requested from
/// the base_index (should be >= 1)
float k_factor;
explicit IndexRefineFlat (Index *base_index);
IndexRefineFlat ();
void train(idx_t n, const float* x) override;
void add(idx_t n, const float* x) override;
void reset() override;
void search(idx_t n, const float* x, idx_t k, float* distances, idx_t* labels) const override;
~IndexRefineFlat() override;
};
/// optimized version for 1D "vectors".
struct IndexFlat1D:IndexFlatL2 {
bool continuous_update; ///< is the permutation updated continuously?
std::vector<idx_t> perm; ///< sorted database indices
explicit IndexFlat1D (bool continuous_update=true);
/// if not continuous_update, call this between the last add and
/// the first search
void update_permutation ();
void add(idx_t n, const float* x) override;
void reset() override;
/// Warn: the distances returned are L1 not L2
void search( idx_t n, const float* x, idx_t k, float* distances, idx_t* labels) const override;
};
}
#endif
4.4.2.2 IndexFlat.cpp文件
#include <IndexFlat.h>
#include <cstring>
#include <utils/distances.h>
#include <utils/extra_distances.h>
#include <utils/utils.h>
#include <utils/Heap.h>
#include <impl/FaissAssert.h>
#include <impl/AuxIndexStructures.h>
namespace faiss {
IndexFlat::IndexFlat (idx_t d, MetricType metric): Index(d, metric) { }
void IndexFlat::add (idx_t n, const float *x) {
xb.insert(xb.end(), x, x + n * d);
ntotal += n;
}
void IndexFlat::reset() {
xb.clear();
ntotal = 0;
}
void IndexFlat::search (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels) const {
// we see the distances and labels as heaps
if (metric_type == METRIC_INNER_PRODUCT) {
float_minheap_array_t res = {size_t(n), size_t(k), labels, distances};
knn_inner_product (x, xb.data(), d, n, ntotal, &res);
} else if (metric_type == METRIC_L2) {
float_maxheap_array_t res = {size_t(n), size_t(k), labels, distances};
knn_L2sqr (x, xb.data(), d, n, ntotal, &res);
} else {
float_maxheap_array_t res = { size_t(n), size_t(k), labels, distances};
knn_extra_metrics (x, xb.data(), d, n, ntotal, metric_type, metric_arg, &res);
}
}
void IndexFlat::range_search (idx_t n, const float *x, float radius, RangeSearchResult *result) const {
switch (metric_type) {
case METRIC_INNER_PRODUCT:
range_search_inner_product (x, xb.data(), d, n, ntotal, radius, result);
break;
case METRIC_L2:
range_search_L2sqr (x, xb.data(), d, n, ntotal, radius, result);
break;
default:
FAISS_THROW_MSG("metric type not supported");
}
}
void IndexFlat::compute_distance_subset (idx_t n, const float *x, idx_t k, float *distances, const idx_t *labels) const {
switch (metric_type) {
case METRIC_INNER_PRODUCT:
fvec_inner_products_by_idx (distances, x, xb.data(), labels, d, n, k);
break;
case METRIC_L2:
fvec_L2sqr_by_idx (distances, x, xb.data(), labels, d, n, k);
break;
default:
FAISS_THROW_MSG("metric type not supported");
}
}
size_t IndexFlat::remove_ids (const IDSelector & sel) {
idx_t j = 0;
for (idx_t i = 0; i < ntotal; i++) {
if (sel.is_member (i)) {
// should be removed
} else {
if (i > j) {
memmove (&xb[d * j], &xb[d * i], sizeof(xb[0]) * d);
}
j++;
}
}
size_t nremove = ntotal - j;
if (nremove > 0) {
ntotal = j;
xb.resize (ntotal * d);
}
return nremove;
}
namespace {
struct FlatL2Dis : DistanceComputer {
size_t d;
Index::idx_t nb;
const float *q;
const float *b;
size_t ndis;
float operator () (idx_t i) override {
ndis++;
return fvec_L2sqr(q, b + i * d, d);
}
float symmetric_dis(idx_t i, idx_t j) override {
return fvec_L2sqr(b + j * d, b + i * d, d);
}
explicit FlatL2Dis(const IndexFlat& storage, const float *q = nullptr)
: d(storage.d), nb(storage.ntotal), q(q), b(storage.xb.data()), ndis(0) {}
void set_query(const float *x) override {
q = x;
}
};
struct FlatIPDis : DistanceComputer {
size_t d;
Index::idx_t nb;
const float *q;
const float *b;
size_t ndis;
float operator () (idx_t i) override {
ndis++;
return fvec_inner_product (q, b + i * d, d);
}
float symmetric_dis(idx_t i, idx_t j) override {
return fvec_inner_product (b + j * d, b + i * d, d);
}
explicit FlatIPDis(const IndexFlat& storage, const float *q = nullptr)
: d(storage.d), nb(storage.ntotal), q(q), b(storage.xb.data()), ndis(0) {}
void set_query(const float *x) override {
q = x;
}
};
} // namespace
DistanceComputer * IndexFlat::get_distance_computer() const {
if (metric_type == METRIC_L2) {
return new FlatL2Dis(*this);
} else if (metric_type == METRIC_INNER_PRODUCT) {
return new FlatIPDis(*this);
} else {
return get_extra_distance_computer (d, metric_type, metric_arg, ntotal, xb.data());
}
}
void IndexFlat::reconstruct (idx_t key, float * recons) const {
memcpy (recons, &(xb[key * d]), sizeof(*recons) * d);
}
/* The standalone codec interface */
size_t IndexFlat::sa_code_size () const {
return sizeof(float) * d;
}
void IndexFlat::sa_encode (idx_t n, const float *x, uint8_t *bytes) const {
memcpy (bytes, x, sizeof(float) * d * n);
}
void IndexFlat::sa_decode (idx_t n, const uint8_t *bytes, float *x) const {
memcpy (x, bytes, sizeof(float) * d * n);
}
/***************************************************
* IndexFlatL2BaseShift
***************************************************/
IndexFlatL2BaseShift::IndexFlatL2BaseShift (idx_t d, size_t nshift, const float *shift): IndexFlatL2 (d), shift (nshift) {
memcpy (this->shift.data(), shift, sizeof(float) * nshift);
}
void IndexFlatL2BaseShift::search ( idx_t n, const float *x, idx_t k, float *distances, idx_t *labels) const {
FAISS_THROW_IF_NOT (shift.size() == ntotal);
float_maxheap_array_t res = {size_t(n), size_t(k), labels, distances};
knn_L2sqr_base_shift (x, xb.data(), d, n, ntotal, &res, shift.data());
}
/***************************************************
* IndexRefineFlat
***************************************************/
IndexRefineFlat::IndexRefineFlat (Index *base_index): Index (base_index->d, base_index->metric_type),
refine_index (base_index->d, base_index->metric_type), base_index (base_index), own_fields (false), k_factor (1) {
is_trained = base_index->is_trained;
FAISS_THROW_IF_NOT_MSG (base_index->ntotal == 0, "base_index should be empty in the beginning");
}
IndexRefineFlat::IndexRefineFlat () {
base_index = nullptr;
own_fields = false;
k_factor = 1;
}
void IndexRefineFlat::train (idx_t n, const float *x) {
base_index->train (n, x);
is_trained = true;
}
void IndexRefineFlat::add (idx_t n, const float *x) {
FAISS_THROW_IF_NOT (is_trained);
base_index->add (n, x);
refine_index.add (n, x);
ntotal = refine_index.ntotal;
}
void IndexRefineFlat::reset () {
base_index->reset ();
refine_index.reset ();
ntotal = 0;
}
namespace {
typedef faiss::Index::idx_t idx_t;
template<class C>
static void reorder_2_heaps ( idx_t n, idx_t k, idx_t *labels, float *distances, idx_t k_base, const idx_t *base_labels, const float *base_distances) {
#pragma omp parallel for
for (idx_t i = 0; i < n; i++) {
idx_t *idxo = labels + i * k;
float *diso = distances + i * k;
const idx_t *idxi = base_labels + i * k_base;
const float *disi = base_distances + i * k_base;
heap_heapify<C> (k, diso, idxo, disi, idxi, k);
if (k_base != k) { // add remaining elements
heap_addn<C> (k, diso, idxo, disi + k, idxi + k, k_base - k);
}
heap_reorder<C> (k, diso, idxo);
}
}
}
void IndexRefineFlat::search (idx_t n, const float *x, idx_t k, float *distances, idx_t *labels) const {
FAISS_THROW_IF_NOT (is_trained);
idx_t k_base = idx_t (k * k_factor);
idx_t * base_labels = labels;
float * base_distances = distances;
ScopeDeleter<idx_t> del1;
ScopeDeleter<float> del2;
if (k != k_base) {
base_labels = new idx_t [n * k_base];
del1.set (base_labels);
base_distances = new float [n * k_base];
del2.set (base_distances);
}
base_index->search (n, x, k_base, base_distances, base_labels);
for (int i = 0; i < n * k_base; i++)
assert (base_labels[i] >= -1 && base_labels[i] < ntotal);
// compute refined distances
refine_index.compute_distance_subset (n, x, k_base, base_distances, base_labels);
// sort and store result
if (metric_type == METRIC_L2) {
typedef CMax <float, idx_t> C;
reorder_2_heaps<C> (n, k, labels, distances, k_base, base_labels, base_distances);
} else if (metric_type == METRIC_INNER_PRODUCT) {
typedef CMin <float, idx_t> C;
reorder_2_heaps<C> (n, k, labels, distances, k_base, base_labels, base_distances);
} else {
FAISS_THROW_MSG("Metric type not supported");
}
}
IndexRefineFlat::~IndexRefineFlat () {
if (own_fields) delete base_index;
}
/***************************************************
* IndexFlat1D
***************************************************/
IndexFlat1D::IndexFlat1D (bool continuous_update): IndexFlatL2 (1), continuous_update (continuous_update) { }
/// if not continuous_update, call this between the last add and the first search
void IndexFlat1D::update_permutation () {
perm.resize (ntotal);
if (ntotal < 1000000) {
fvec_argsort (ntotal, xb.data(), (size_t*)perm.data());
} else {
fvec_argsort_parallel (ntotal, xb.data(), (size_t*)perm.data());
}
}
void IndexFlat1D::add (idx_t n, const float *x) {
IndexFlatL2::add (n, x);
if (continuous_update)
update_permutation();
}
void IndexFlat1D::reset() {
IndexFlatL2::reset();
perm.clear();
}
void IndexFlat1D::search (idx_t n, const float *x, idx_t k,float *distances, idx_t *labels) const {
FAISS_THROW_IF_NOT_MSG (perm.size() == ntotal, "Call update_permutation before search");
#pragma omp parallel for
for (idx_t i = 0; i < n; i++) {
float q = x[i]; // query
float *D = distances + i * k;
idx_t *I = labels + i * k;
// binary search
idx_t i0 = 0, i1 = ntotal;
idx_t wp = 0;
if (xb[perm[i0]] > q) {
i1 = 0;
goto finish_right;
}
if (xb[perm[i1 - 1]] <= q) {
i0 = i1 - 1;
goto finish_left;
}
while (i0 + 1 < i1) {
idx_t imed = (i0 + i1) / 2;
if (xb[perm[imed]] <= q) i0 = imed;
else i1 = imed;
}
// query is between xb[perm[i0]] and xb[perm[i1]] expand to nearest neighs
while (wp < k) {
float xleft = xb[perm[i0]];
float xright = xb[perm[i1]];
if (q - xleft < xright - q) {
D[wp] = q - xleft;
I[wp] = perm[i0];
i0--; wp++;
if (i0 < 0) { goto finish_right; }
} else {
D[wp] = xright - q;
I[wp] = perm[i1];
i1++; wp++;
if (i1 >= ntotal) { goto finish_left; }
}
}
goto done;
finish_right:
// grow to the right from i1
while (wp < k) {
if (i1 < ntotal) {
D[wp] = xb[perm[i1]] - q;
I[wp] = perm[i1];
i1++;
} else {
D[wp] = std::numeric_limits<float>::infinity();
I[wp] = -1;
}
wp++;
}
goto done;
finish_left:
// grow to the left from i0
while (wp < k) {
if (i0 >= 0) {
D[wp] = q - xb[perm[i0]];
I[wp] = perm[i0];
i0--;
} else {
D[wp] = std::numeric_limits<float>::infinity();
I[wp] = -1;
}
wp++;
}
done: ;
}
}
} // namespace faiss
4.4.2.3 test_indexflat.cpp文件
#include <cstdio>
#include <cstdlib>
#include <IndexFlat.h>
int main() {
int d = 64; // dimension
int nb = 100000; // database size
int nq = 10000; // nb of queries
float *xb = new float[d * nb];
float *xq = new float[d * nq];
for(int i = 0; i < nb; i++) {
for(int j = 0; j < d; j++)
xb[d * i + j] = drand48();
xb[d * i] += i / 1000.;
}
for(int i = 0; i < nq; i++) {
for(int j = 0; j < d; j++)
xq[d * i + j] = drand48();
xq[d * i] += i / 1000.;
}
faiss::IndexFlatL2 index(d); // call constructor
printf("is_trained = %s\n", index.is_trained ? "true" : "false");
index.add(nb, xb); // add vectors to the index
printf("ntotal = %ld\n", index.ntotal);
int k = 4;
{ // sanity check: search 5 first vectors of xb
long *I = new long[k * 5];
float *D = new float[k * 5];
index.search(5, xb, k, D, I);
// print results
printf("I=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%5ld ", I[i * k + j]);
printf("\n");
}
printf("D=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%7g ", D[i * k + j]);
printf("\n");
}
delete [] I;
delete [] D;
}
{ // search xq
long *I = new long[k * nq];
float *D = new float[k * nq];
index.search(nq, xq, k, D, I);
// print results
printf("I (5 first results)=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%5ld ", I[i * k + j]);
printf("\n");
}
printf("I (5 last results)=\n");
for(int i = nq - 5; i < nq; i++) {
for(int j = 0; j < k; j++)
printf("%5ld ", I[i * k + j]);
printf("\n");
}
delete [] I;
delete [] D;
}
delete [] xb;
delete [] xq;
return 0;
}
4.4.3 IndexLSH.h和IndexLSH.cpp文件
此文件描述局部敏感hash的Index, 定义了IndexLSH,内部将变量转变为二进制, 求hamming距离来实现, 训练主要是生成偏移的thresholds。
4.4.3.1 IndexLSH.h文件
#ifndef INDEX_LSH_H
#define INDEX_LSH_H
#include <vector>
#include <Index.h>
#include <VectorTransform.h>
namespace faiss {
/** The sign of each vector component is put in a binary signature */
struct IndexLSH:Index {
typedef unsigned char uint8_t;
int nbits; ///< nb of bits per vector
int bytes_per_vec; ///< nb of 8-bits per encoded vector
bool rotate_data; ///< whether to apply a random rotation to input
bool train_thresholds; ///< whether we train thresholds or use 0
RandomRotationMatrix rrot; ///< optional random rotation
std::vector <float> thresholds; ///< thresholds to compare with
/// encoded dataset
std::vector<uint8_t> codes;
IndexLSH (idx_t d, int nbits, bool rotate_data = true, bool train_thresholds = false);
/** Preprocesses and resizes the input to the size required to
* binarize the data
* @param x input vectors, size n * d
* @return output vectors, size n * bits. May be the same pointer
* as x, otherwise it should be deleted by the caller
*/
const float *apply_preprocess (idx_t n, const float *x) const;
void train(idx_t n, const float* x) override;
void add(idx_t n, const float* x) override;
void search(idx_t n,const float* x,idx_t k,float* distances,idx_t* labels) const override;
void reset() override;
/// transfer the thresholds to a pre-processing stage (and unset train_thresholds)
void transfer_thresholds (LinearTransform * vt);
~IndexLSH() override {}
IndexLSH ();
/* standalone codec interface.
* The vectors are decoded to +/- 1 (not 0, 1) */
size_t sa_code_size () const override;
void sa_encode (idx_t n, const float *x, uint8_t *bytes) const override;
void sa_decode (idx_t n, const uint8_t *bytes, float *x) const override;
};
}
#endif
4.4.3.1 IndexLSH.cpp文件
#include <IndexLSH.h>
#include <cstdio>
#include <cstring>
#include <algorithm>
#include <utils/utils.h>
#include <utils/hamming.h>
#include <impl/FaissAssert.h>
namespace faiss {
/***************************************************************
* IndexLSH
***************************************************************/
IndexLSH::IndexLSH (idx_t d, int nbits, bool rotate_data, bool train_thresholds): Index(d), nbits(nbits), rotate_data(rotate_data),train_thresholds (train_thresholds), rrot(d, nbits) {
is_trained = !train_thresholds;
bytes_per_vec = (nbits + 7) / 8;
if (rotate_data) {
rrot.init(5);
} else {
FAISS_THROW_IF_NOT (d >= nbits);
}
}
IndexLSH::IndexLSH (): nbits (0), bytes_per_vec(0), rotate_data (false), train_thresholds (false) { }
const float * IndexLSH::apply_preprocess (idx_t n, const float *x) const {
float *xt = nullptr;
if (rotate_data) {
// also applies bias if exists
xt = rrot.apply (n, x);
} else if (d != nbits) {
assert (nbits < d);
xt = new float [nbits * n];
float *xp = xt;
for (idx_t i = 0; i < n; i++) {
const float *xl = x + i * d;
for (int j = 0; j < nbits; j++)
*xp++ = xl [j];
}
}
if (train_thresholds) {
if (xt == NULL) {
xt = new float [nbits * n];
memcpy (xt, x, sizeof(*x) * n * nbits);
}
float *xp = xt;
for (idx_t i = 0; i < n; i++)
for (int j = 0; j < nbits; j++)
*xp++ -= thresholds [j];
}
return xt ? xt : x;
}
void IndexLSH::train (idx_t n, const float *x) {
if (train_thresholds) {
thresholds.resize (nbits);
train_thresholds = false;
const float *xt = apply_preprocess (n, x);
ScopeDeleter<float> del (xt == x ? nullptr : xt);
train_thresholds = true;
float * transposed_x = new float [n * nbits];
ScopeDeleter<float> del2 (transposed_x);
for (idx_t i = 0; i < n; i++)
for (idx_t j = 0; j < nbits; j++)
transposed_x [j * n + i] = xt [i * nbits + j];
for (idx_t i = 0; i < nbits; i++) {
float *xi = transposed_x + i * n;
// std::nth_element
std::sort (xi, xi + n);
if (n % 2 == 1)
thresholds [i] = xi [n / 2];
else
thresholds [i] = (xi [n / 2 - 1] + xi [n / 2]) / 2;
}
}
is_trained = true;
}
void IndexLSH::add (idx_t n, const float *x) {
FAISS_THROW_IF_NOT (is_trained);
codes.resize ((ntotal + n) * bytes_per_vec);
sa_encode (n, x, &codes[ntotal * bytes_per_vec]);
ntotal += n;
}
void IndexLSH::search ( idx_t n, const float *x, idx_t k, float *distances, idx_t *labels) const {
FAISS_THROW_IF_NOT (is_trained);
const float *xt = apply_preprocess (n, x);
ScopeDeleter<float> del (xt == x ? nullptr : xt);
uint8_t * qcodes = new uint8_t [n * bytes_per_vec];
ScopeDeleter<uint8_t> del2 (qcodes);
fvecs2bitvecs (xt, qcodes, nbits, n);
int * idistances = new int [n * k];
ScopeDeleter<int> del3 (idistances);
int_maxheap_array_t res = { size_t(n), size_t(k), labels, idistances};
hammings_knn_hc (&res, qcodes, codes.data(), ntotal, bytes_per_vec, true);
// convert distances to floats
for (int i = 0; i < k * n; i++)
distances[i] = idistances[i];
}
void IndexLSH::transfer_thresholds (LinearTransform *vt) {
if (!train_thresholds) return;
FAISS_THROW_IF_NOT (nbits == vt->d_out);
if (!vt->have_bias) {
vt->b.resize (nbits, 0);
vt->have_bias = true;
}
for (int i = 0; i < nbits; i++)
vt->b[i] -= thresholds[i];
train_thresholds = false;
thresholds.clear();
}
void IndexLSH::reset() {
codes.clear();
ntotal = 0;
}
size_t IndexLSH::sa_code_size () const {
return bytes_per_vec;
}
void IndexLSH::sa_encode (idx_t n, const float *x, uint8_t *bytes) const {
FAISS_THROW_IF_NOT (is_trained);
const float *xt = apply_preprocess (n, x);
ScopeDeleter<float> del (xt == x ? nullptr : xt);
fvecs2bitvecs (xt, bytes, nbits, n);
}
void IndexLSH::sa_decode (idx_t n, const uint8_t *bytes, float *x) const {
float *xt = x;
ScopeDeleter<float> del;
if (rotate_data || nbits != d) {
xt = new float [n * nbits];
del.set(xt);
}
bitvecs2fvecs (bytes, xt, nbits, n);
if (train_thresholds) {
float *xp = xt;
for (idx_t i = 0; i < n; i++) {
for (int j = 0; j < nbits; j++) {
*xp++ += thresholds [j];
}
}
}
if (rotate_data) {
rrot.reverse_transform (n, xt, x);
} else if (nbits != d) {
for (idx_t i = 0; i < n; i++) {
memcpy (x + i * d, xt + i * nbits, nbits * sizeof(xt[0]));
}
}
}
} // namespace faiss
4.4.2.3 test_indexlsh.cpp文件
#include <cstdio>
#include <cstdlib>
#include <IndexLSH.h>
int main() {
int d = 64; // dimension
int nb = 100000; // database size
int nq = 10000; // nb of queries
float *xb = new float[d * nb];
float *xq = new float[d * nq];
for(int i = 0; i < nb; i++) {
for(int j = 0; j < d; j++)
xb[d * i + j] = drand48();
xb[d * i] += i / 1000.;
}
for(int i = 0; i < nq; i++) {
for(int j = 0; j < d; j++)
xq[d * i + j] = drand48();
xq[d * i] += i / 1000.;
}
faiss::IndexLSH index(d,d); // call constructor
printf("is_trained = %s\n", index.is_trained ? "true" : "false");
index.add(nb, xb); // add vectors to the index
printf("ntotal = %ld\n", index.ntotal);
int k = 4;
{ // sanity check: search 5 first vectors of xb
long *I = new long[k * 5];
float *D = new float[k * 5];
index.search(5, xb, k, D, I);
// print results
printf("I=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%5ld ", I[i * k + j]);
printf("\n");
}
printf("D=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%7g ", D[i * k + j]);
printf("\n");
}
delete [] I;
delete [] D;
}
{ // search xq
long *I = new long[k * nq];
float *D = new float[k * nq];
index.search(nq, xq, k, D, I);
// print results
printf("I (5 first results)=\n");
for(int i = 0; i < 5; i++) {
for(int j = 0; j < k; j++)
printf("%5ld ", I[i * k + j]);
printf("\n");
}
printf("D (5 last results)=\n");
for(int i = nq - 5; i < nq; i++) {
for(int j = 0; j < k; j++)
printf("%f ", D[i * k + j]);
printf("\n");
}
delete [] I;
delete [] D;
}
delete [] xb;
delete [] xq;
return 0;
}
参考链接: