机器学习基础
机器学习的特点就是:以计算机为工具和平台,以数据为研究对象,以学习方法为中心;是概率论、线性代数、数值计算、信息论、最优化理论和计算机科学等多个领域的交叉学科。
一、线性代数
1.1 基本概念
标量:一个标量就是一个单独的数,一般用小写的的变量名称表示。
向量:一个向量就是一列数,这些数是有序排列的。通常会赋予向量粗体的小写名称。当我们需要明确表示向量中的元素时,我们会将元素排列成一个方括号包围的纵柱:
我们可以把向量看作空间中的点,每个元素是不同的坐标轴上的坐标。
矩阵:矩阵是二维数组,其中的每一个元素被两个索引而非一个所确定。我们通常会赋予矩阵粗体的大写变量名称,比如A。如果一个实数矩阵高度为m,宽度为n,那么我们说A\in R^{m\times n} 。
张量:几何代数中定义的张量是基于向量和矩阵的推广,通俗一点理解的话,我们可以将标量视为零阶张量,矢量视为一阶张量,那么矩阵就是二阶张量。
例如,可以将任意一张彩色图片表示成一个三阶张量,三个维度分别是图片的高度、宽度和色彩数据。将这张图用张量表示出来,就是最下方的那张表格:
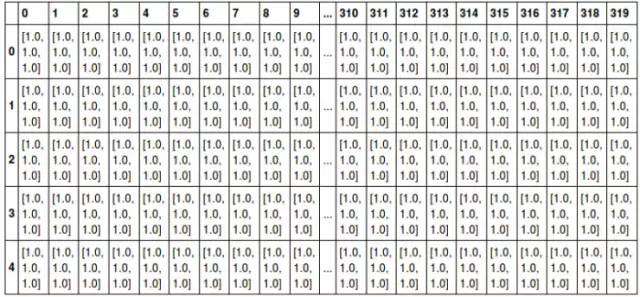
其中表的横轴表示图片的宽度值,这里只截取0~319;表的纵轴表示图片的高度值,这里只截取0~4;表格中每个方格代表一个像素点,比如第一行第一列的表格数据为[1.0,1.0,1.0],代表的就是RGB三原色在图片的这个位置的取值情况(即R=1.0,G=1.0,B=1.0)。
当然我们还可以将这一定义继续扩展,即:我们可以用四阶张量表示一个包含多张图片的数据集,这四个维度分别是:图片在数据集中的编号,图片高度、宽度,以及色彩数据。张量在深度学习中是一个很重要的概念,因为它是一个深度学习框架中的一个核心组件,后续的所有运算和优化算法几乎都是基于张量进行的。
范数:有时我们需要衡量一个向量的大小。在机器学习中,我们经常使用被称为范数(norm) 的函数衡量矩阵大小。L_p范数如下:
所以:
L1范数\left| \left| x \right| \right| :为x向量各个元素绝对值之和;
L2范数\left| \left| x \right| \right|_{2} :为x向量各个元素平方和的开方。
这里先说明一下,在机器学习中,L1范数和L2范数很常见,主要用在损失函数中起到一个限制模型参数复杂度的作用。
1.2 偏差(Bias)与方差(Variance)
- 为什么会有偏差和方差?
对学习算法除了通过实验估计其泛化性能之外,人们往往还希望了解它为什么具有这样的性能。“偏差-方差分解”(bias-variance decomposition)就是从偏差和方差的角度来解释学习算法泛化性能的一种重要工具。
在机器学习中,我们用训练数据集去训练一个模型,通常的做法是定义一个误差函数,通过将这个误差的最小化过程,来提高模型的性能。然而我们学习一个模型的目的是为了解决训练数据集这个领域中的一般化问题,单纯地将训练数据集的损失最小化,并不能保证在解决更一般的问题时模型仍然是最优,甚至不能保证模型是可用的。这个训练数据集的损失与一般化的数据集的损失之间的差异就叫做泛化误差(generalization error)。而泛化误差可以分解为偏差(Biase)、方差(Variance)和噪声(Noise)。
- 偏差、方差、噪声是什么?
简述偏差、方差、噪声
如果我们能够获得所有可能的数据集合,并在这个数据集合上将损失最小化,那么学习得到的模型就可以称之为“真实模型”。当然,在现实生活中我们不可能获取并训练所有可能的数据,所以“真实模型”肯定存在,但是无法获得。我们的最终目的是学习一个模型使其更加接近这个真实模型。Bias和Variance分别从两个方面来描述我们学习到的模型与真实模型之间的差距。
Bias是用所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。
Variance是不同的训练数据集训练出的模型输出值之间的差异。
噪声的存在是学习算法所无法解决的问题,数据的质量决定了学习的上限。假设在数据已经给定的情况下,此时上限已定,我们要做的就是尽可能的接近这个上限。
注意:我们能够用来学习的训练数据集只是全部数据中的一个子集。想象一下,我们现在收集几组不同的数据,因为每一组数据的不同,我们学习到模型的最小损失值也会有所不同,它们与“真实模型”的最小损失也是不一样的。
数学公式定义偏差、方差、噪声
要进一步理解偏差、方差、噪声,我们需要看看它们的数学公式。
| 符号 | 含义 |
|---|---|
| x | 测试样本 |
| D | 数据集 |
| y_D | x在数据中的标记 |
| y | x的真实标记 |
| f | 训练集D学到的模型 |
| f(x;D) | 由训练集D学到的模型f对x的预测输出 |
| \bar{f}(x) | 模型f对x的期望输出 |
以回归任务为例,学习算法的期望预测为:
这里的期望预测也就是针对不同数据集D,模型f对样本x的预测值取其期望,也叫做平均预测(average predicted)。
- 方差定义:
使用样本数相同的不同训练集产生的方差为:
方差的含义:方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响。
- 偏差定义:
期望输出与真实标记的差别称为偏差(bias),即:
偏差的含义:偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。
- 噪声:
噪声为:
噪声的含义:噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度。
- 泛化误差、偏差和方差的关系?
也就是说,泛化误差可以通过一系列公式分解运算证明:泛化误差为偏差、方差与噪声之和。证明过程如下:
为了便于讨论,我们假定噪声期望为零,即E_{D}[y_{D}-y]=0。通过简单的多项式展开合并,可对算法的期望泛化误差进行分解:
于是,最终得到:

“偏差-方差分解”说明,泛化性能是由学习算法的能力、数据的充分性以及学习任务本身的难度所共同决定的。给定学习任务,为了取得好的泛化性能,则需使偏差较小,即能够充分拟合数据,并且使方差较小,即使得数据扰动产生的影响小。
- 用图形解释偏差和方差
我们从下面的靶心图来对偏差和方差有个直观的感受。(图片来自:Understanding the Bias-Variance Tradeoff)
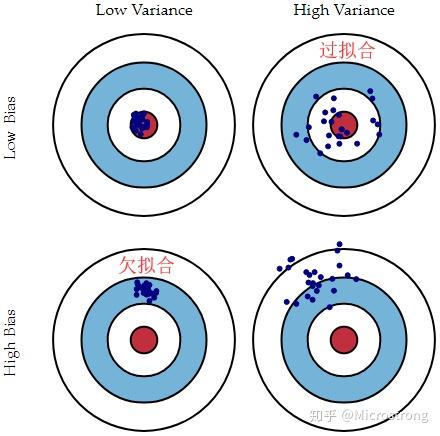
假设红色的靶心区域是学习算法完美的正确预测值,蓝色点为训练数据集所训练出的模型对样本的预测值,当我们从靶心逐渐往外移动时,预测效果逐渐变差。
从上面的图片中很容易可以看到,左边一列的蓝色点比较集中,右边一列的蓝色点比较分散,它们描述的是方差的两种情况。比较集中的属于方差比较小,比较分散的属于方差比较大的情况。
我们再从蓝色点与红色靶心区域的位置关系来看,靠近红色靶心的属于偏差较小的情况,远离靶心的属于偏差较大的情况。
Variance的对象是多个模型,是相同分布的不同数据集训练出模型的输出值之间的差异。它刻画的是数据扰动对模型的影响。
- 偏差、方差窘境
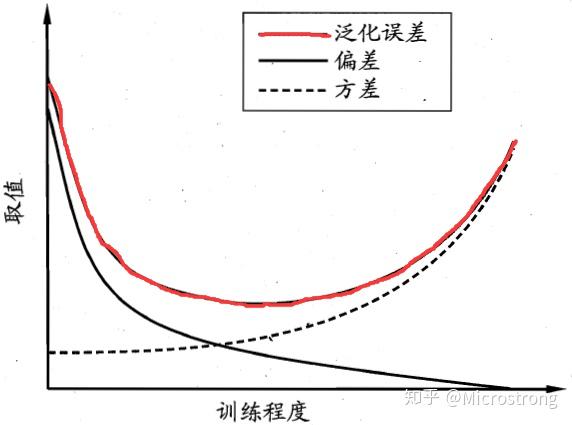
一般来说,偏差与方差是有冲突的,这称为偏差-方差窘境(bias-variance dilemma)。下图给出了一个示意图。给定学习任务,假定我们能控制学习算法的训练程度,则在训练不足时,学习器的拟合能力不够强,训练数据的扰动不足以使学习器产生显著变化,此时偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率;在训练程度充足后,学习器的拟合能力已经非常强,训练数据发生的轻微扰动都会导致学习器发生显著变化,若训练数据自身的、非全局的特性被学习器学到了,则将发生过拟合。
- 偏差、方差与过拟合、欠拟合的关系?
一般来说,简单的模型会有一个较大的偏差和较小的方差,复杂的模型偏差较小方差较大。
欠拟合:模型不能适配训练样本,有一个很大的偏差。
举个例子:我们可能有本质上是多项式的连续非线性数据,但模型只能表示线性关系。在此情况下,我们向模型提供多少数据不重要,因为模型根本无法表示数据的基本关系,模型不能适配训练样本,有一个很大的偏差,因此我们需要更复杂的模型。那么,是不是模型越复杂拟合程度越高越好呢?也不是,因为还有方差。
过拟合:模型很好的适配训练样本,但在测试集上表现很糟,有一个很大的方差。
方差就是指模型过于拟合训练数据,以至于没办法把模型的结果泛化。而泛化正是机器学习要解决的问题,如果一个模型只能对一组特定的数据有效,换了数据就无效,我们就说这个模型过拟合。这就是模型很好的适配训练样本,但在测试集上表现很糟,有一个很大的方差。
- 偏差、方差与模型复杂度的关系
由前面偏差和方差的介绍,我们来总结一下偏差和方差的来源:我们训练的机器学习模型,必不可少地对数据依赖。但是,如果你不清楚数据服从一个什么样的分布,或是没办法拿到所有可能的数据(肯定拿不到所有数据),那么我们训练出来的模型和真实模型之间存在不一致性。这种不一致性表现在两个方面:偏差和方差。
那么,既然偏差和方差是这么来的,而且还是无法避免的,那么我们有什么办法尽量减少它对模型的影响呢?
一个好的办法就是正确选择模型的复杂度。复杂度高的模型通常对训练数据有很好的拟合能力,但是对测试数据就不一定了。而复杂度太低的模型又不能很好的拟合训练数据,更不能很好的拟合测试数据。因此,模型复杂度和模型偏差和方差具有如下图所示关系。
- 偏差、方差与bagging、boosting的关系?
Bagging算法是对训练样本进行采样,产生出若干不同的子集,再从每个数据子集中训练出一个分类器,取这些分类器的平均,所以是降低模型的方差(variance)。Bagging算法和Random Forest这种并行算法都有这个效果。
Boosting则是迭代算法,每一次迭代都根据上一次迭代的预测结果对样本进行权重调整,所以随着迭代不断进行,误差会越来越小,所以模型的偏差(bias)会不断降低。
- 偏差、方差和K折交叉验证的关系?
K-fold Cross Validation的思想:将原始数据分成K组(一般是均分),将每个子集数据分别做一次验证集,其余的K-1组子集数据作为训练集,这样会得到K个模型,用这K个模型最终的验证集的分类准确率的平均数作为此K-CV下分类器的性能指标。
对于一系列模型F(\hat{f}, \theta), 我们使用Cross Validation的目的是获得预测误差的无偏估计量CV,从而可以用来选择一个最优的Theta*,使得CV最小。假设K-folds cross validation,CV统计量定义为每个子集中误差的平均值,而K的大小和CV平均值的bias和variance是有关的:
其中,m = N/K 代表每个子集的大小, N是总的训练样本量,K是子集的数目。
当K较大时,m较小,模型建立在较大的N-m上,经过更多次数的平均可以学习得到更符合真实数据分布的模型,Bias就小了,但是这样一来模型就更加拟合训练数据集,再去测试集上预测的时候预测误差的期望值就变大了,从而Variance就大了;k较小的时候,模型不会过度拟合训练数据,从而Bias较大,但是正因为没有过度拟合训练数据,Variance也较小。
- 如何解决偏差、方差问题?
整体思路:首先,要知道偏差和方差是无法完全避免的,只能尽量减少其影响。
在避免偏差时,需尽量选择正确的模型,一个非线性问题而我们一直用线性模型去解决,那无论如何,高偏差是无法避免的。
有了正确的模型,我们还要慎重选择数据集的大小,通常数据集越大越好,但大到数据集已经对整体所有数据有了一定的代表性后,再多的数据已经不能提升模型了,反而会带来计算量的增加。而训练数据太小一定是不好的,这会带来过拟合,模型复杂度太高,方差很大,不同数据集训练出来的模型变化非常大。
最后,要选择合适的模型复杂度,复杂度高的模型通常对训练数据有很好的拟合能力。
针对偏差和方差的思路:
偏差:实际上也可以称为避免欠拟合。
寻找更好的特征 -- 具有代表性。
用更多的特征 -- 增大输入向量的维度。(增加模型复杂度)
方差:避免过拟合
增大数据集合 -- 使用更多的数据,减少数据扰动所造成的影响
减少数据特征 -- 减少数据维度,减少模型复杂度
正则化方法
交叉验证法
1.3 特征分解
许多数学对象可以通过将它们分解成多个组成部分。特征分解是使用最广的矩阵分解之一,即将矩阵分解成一组特征向量和特征值。
方阵A的特征向量是指与A相乘后相当于对该向量进行缩放的非零向量\nu:
标量\lambda被称为这个特征向量对应的特征值。
使用特征分解去分析矩阵A时,得到特征向量构成的矩阵V和特征值构成的向量\lambda,我们可以重新将A写作:
- 奇异值分解(Singular Value Decomposition,SVD)
矩阵的特征分解是有前提条件的,那就是只有对可对角化的矩阵才可以进行特征分解。但实际中很多矩阵往往不满足这一条件,甚至很多矩阵都不是方阵,就是说连矩阵行和列的数目都不相等。这时候怎么办呢?人们将矩阵的特征分解进行推广,得到了一种叫作“矩阵的奇异值分解”的方法,简称SVD。通过奇异分解,我们会得到一些类似于特征分解的信息。
它的具体做法是将一个普通矩阵分解为奇异向量和奇异值。比如将矩阵A分解成三个矩阵的乘积:A=UDV^{T}
假设A是一个m\times n矩阵,那么U是一个m\times m矩阵,D是一个m\times n矩阵,V是一个n\times n矩阵。
这些矩阵每一个都拥有特殊的结构,其中U和V都是正交矩阵,D是对角矩阵(注意,D不一定是方阵)。对角矩阵D对角线上的元素被称为矩阵A的奇异值。矩阵U的列向量被称为左奇异向量,矩阵V的列向量被称右奇异向量。
SVD最有用的一个性质可能是拓展矩阵求逆到非方矩阵上。另外,SVD可用于推荐系统中。
奇异值的物理意义
参考: http://www.ams.org/publicoutreach/feature-column/fcarc-svd

图片实际上对应着一个矩阵,矩阵的大小就是像素大小,比如这张图对应的矩阵阶数就是450*333,矩阵上每个元素的数值对应着像素值。我们记这个像素矩阵为A。
现在我们对矩阵A进行奇异值分解。直观上,奇异值分解将矩阵分解成若干个秩一矩阵之和,用公式表示就是:
其中等式右边每一项前的系数\sigma就是奇异值,u和v分别表示列向量,秩一矩阵的意思是矩阵秩为1。注意到每一项uv^{\rm T}都是秩为1的矩阵。我们假定奇异值满足\sigma_1\geq\sigma_2\geq...\geq\sigma_r>0(奇异值大于0是个重要的性质,但这里先别在意),如果不满足的话重新排列顺序即可,这无非是编号顺序的问题。
既然奇异值有从大到小排列的顺序,自然要问,如果只保留大的奇异值,舍去较小的奇异值,这样式中的等式自然不再成立,那会得到怎样的矩阵——也就是图像?
令A_1=\sigma_1 u_1v_1^{\rm T},这只保留等式右边第一项,然后作图:

结果就是完全看不清是啥……我们试着多增加几项进来:A_5=\sigma_1 u_1v_1^{\rm T}+\sigma_2 u_2v_2^{\rm T}+\sigma_3 u_3v_3^{\rm T}+\sigma_4 u_4v_4^{\rm T}+\sigma_5 u_5v_5^{\rm T},再作图

隐约可以辨别这是短发伽椰子的脸……但还是很模糊,毕竟我们只取了5个奇异值而已。下面我们取20个奇异值试试,也就是等式右边取前20项构成A_{20}

虽然还有些马赛克般的模糊,但我们总算能辨别出这是Juri酱的脸。当我们取到等式右边前50项时:

我们得到和原图差别不大的图像。也就是说当k从1不断增大时,A_k不断的逼近A。让我们回到公式
矩阵A表示一个450*333的矩阵,需要保存450x333=149850个元素的值。等式右边u和v分别是450*1和333*1的向量,每一项有1+450+333=784个元素。如果我们要存储很多高清的图片,而又受限于存储空间的限制,在尽可能保证图像可被识别的精度的前提下,我们可以保留奇异值较大的若干项,舍去奇异值较小的项即可。例如在上面的例子中,如果我们只保留奇异值分解的前50项,则需要存储的元素为784x50=39200,和存储原始矩阵A相比,存储量仅为后者的26%。
奇异值往往对应着矩阵中隐含的重要信息,且重要性和奇异值大小正相关。每个矩阵A都可以表示为一系列秩为1的"小矩阵"之和,而奇异值则衡量了这些"小矩阵"对于A的权重。
在图像处理领域,奇异值不仅可以应用在数据压缩上,还可以对图像去噪。如果一副图像包含噪声,我们有理由相信那些较小的奇异值就是由于噪声引起的。当我们强行令这些较小的奇异值为0时,就可以去除图片中的噪声。如下是一张25*15的图像

但往往我们只能得到如下带有噪声的图像(和无噪声图像相比,下图的部分白格子中带有灰色):

通过奇异值分解,我们发现矩阵的奇异值从大到小分别为:14.15,4.67,3.00,0.21,……,0.05。除了前3个奇异值较大以外,其余奇异值相比之下都很小。强行令这些小奇异值为0,然后只用前3个奇异值构造新的矩阵,得到

可以明显看出噪声减少了(白格子上灰白相间的图案减少了)。
奇异值分解还广泛的用于主成分分析(Principle Component Analysis,简称PCA)和推荐系统(如Netflex的电影推荐系统)等。在这些应用领域,奇异值也有相应的意义。
奇异值的几何含义
下面的讨论需要一点点线性代数的知识。线性代数中最让人印象深刻的一点是,要将矩阵和空间中的线性变换视为同样的事物。比如对角矩阵M作用在任何一个向量上
其几何意义为在水平x方向上拉伸3倍,y方向保持不变的线性变换。换言之对角矩阵起到作用是将水平垂直网格作水平拉伸(或者反射后水平拉伸)的线性变换。
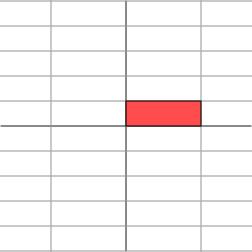
如果M不是对角矩阵,而是一个对称矩阵
那么,我们也总可以找到一组网格线,使得矩阵作用在该网格上仅仅表现为(反射)拉伸变换,而没有旋转变换
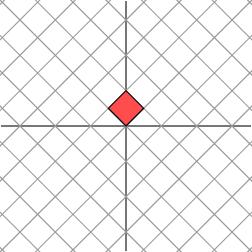
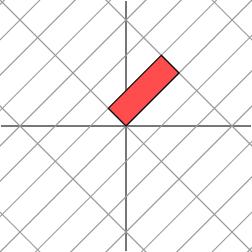
考虑更一般的非对称矩阵
很遗憾,此时我们再也找不到一组网格,使得矩阵作用在该网格上之后只有拉伸变换(找不到背后的数学原因是对一般非对称矩阵无法保证在实数域上可对角化,不明白也不要在意)。我们退求其次,找一组网格,使得矩阵作用在该网格上之后允许有拉伸变换和旋转变换,但要保证变换后的网格依旧互相垂直。这是可以做到的
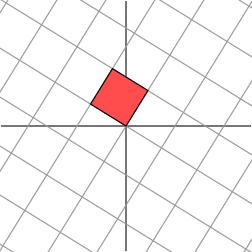
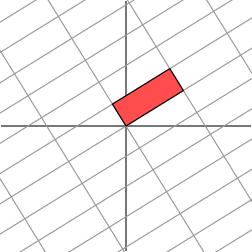
奇异值分解的几何含义为:对于任何的一个矩阵,我们要找到一组两两正交单位向量序列,使得矩阵作用在此向量序列上后得到新的向量序列保持两两正交。奇异值与矩阵分解的不同是奇异值可以是投影。
- Moore-Penrose伪逆
对于非方矩阵而言,其逆矩阵没有定义。假设在下面问题中,我们想通过矩阵A的左逆B来求解线性方程:Ax=y
等式两边同时左乘左逆B后,得到:x=By
是否存在唯一的映射将A映射到B取决于问题的形式。
如果矩阵A的行数大于列数,那么上述方程可能没有解;如果矩阵A的行数小于列数,那么上述方程可能有多个解。
Moore-Penrose伪逆使我们能够解决这种情况,矩阵A的伪逆定义为:
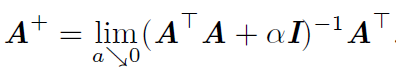
但是计算伪逆的实际算法没有基于这个式子,而是使用下面的公式:
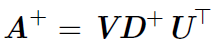
其中,矩阵U,D和V是矩阵A奇异值分解后得到的矩阵。对角矩阵D的伪逆D+是其非零元素取倒之后再转置得到的。
三、信息论
信息论本来是通信中的概念,但是其核心思想“熵”在机器学习中也得到了广泛的应用。比如决策树模型ID3,C4.5中是利用信息增益来划分特征而生成一颗决策树的,而信息增益就是基于这里所说的熵。所以它的重要性也是可想而知。
3.1 基础概念
熵:如果一个随机变量X的可能取值为X=\left\{ x_{1},x_{2} ,.....,x_{n} \right\} ,其概率分布为P\left( X=x_{i} \right) =p_{i} ,i=1,2,.....,n,则随机变量X的熵定义为H(X):
联合熵:两个随机变量X和Y的联合分布可以形成联合熵,定义为联合自信息的数学期望,它是二维随机变量XY的不确定性的度量,用H(X,Y)表示:
条件熵:在随机变量X发生的前提下,随机变量Y发生新带来的熵,定义为Y的条件熵,用H(Y|X)表示:
条件熵用来衡量在已知随机变量X的条件下,随机变量Y的不确定性。
实际上,熵、联合熵和条件熵之间存在以下关系:
推导过程如下:
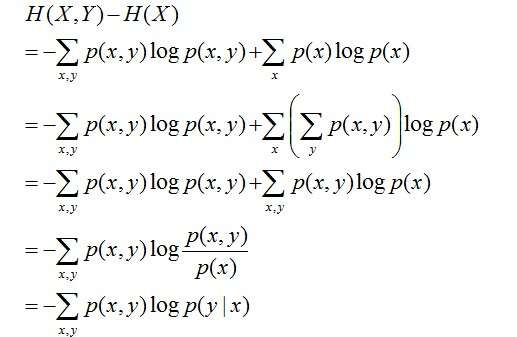
其中:
第二行推到第三行的依据是边缘分布P(x)等于联合分布P(x,y)的和;
第三行推到第四行的依据是把公因子logP(x)乘进去,然后把x,y写在一起;
第四行推到第五行的依据是:因为两个sigma都有P(x,y),故提取公因子P(x,y)放到外边,然后把里边的-(log P(x,y) - log P(x))写成-log (P(x,y) / P(x) );
第五行推到第六行的依据是:P(x,y) = P(x) * P(y|x),故P(x,y) / P(x) = P(y|x)。
相对熵:相对熵又称互熵、交叉熵、KL散度、信息增益,是描述两个概率分布P和Q差异的一种方法,记为D(P||Q)。在信息论中,D(P||Q)表示当用概率分布Q来拟合真实分布P时,产生的信息损耗,其中P表示真实分布,Q表示P的拟合分布。
对于一个离散随机变量的两个概率分布P和Q来说,它们的相对熵定义为:
注意:D(P||Q) ≠ D(Q||P)
相对熵又称KL散度( Kullback–Leibler divergence),KL散度也是一个机器学习中常考的概念。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵称为互信息,用I(X,Y)表示。互信息是信息论里一种有用的信息度量方式,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
互信息、熵和条件熵之间存在以下关系: H\left( Y|X \right) =H\left( Y \right) -I\left( X,Y \right)
推导过程如下:
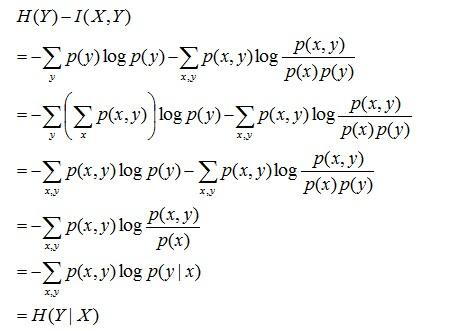
通过上面的计算过程发现有:H(Y|X) = H(Y) - I(X,Y),又由前面条件熵的定义有:H(Y|X) = H(X,Y) - H(X),于是有I(X,Y)= H(X) + H(Y) - H(X,Y),此结论被多数文献作为互信息的定义。
最大熵模型:最大熵原理是概率模型学习的一个准则,它认为:学习概率模型时,在所有可能的概率分布中,熵最大的模型是最好的模型。通常用约束条件来确定模型的集合,所以,最大熵模型原理也可以表述为:在满足约束条件的模型集合中选取熵最大的模型。
前面我们知道,若随机变量X的概率分布是P\left( x_{i} \right) ,则其熵定义如下:
熵满足下列不等式:
式中,|X|是X的取值个数,当且仅当X的分布是均匀分布时右边的等号成立。也就是说,当X服从均匀分布时,熵最大。
直观地看,最大熵原理认为:要选择概率模型,首先必须满足已有的事实,即约束条件;在没有更多信息的情况下,那些不确定的部分都是“等可能的”。最大熵原理通过熵的最大化来表示等可能性;“等可能”不易操作,而熵则是一个可优化的指标。
四、数值计算和最优化
4.1 基础概念
上溢和下溢:在数字计算机上实现连续数学的基本困难是:我们需要通过有限数量的位模式来表示无限多的实数,这意味着我们在计算机中表示实数时几乎都会引入一些近似误差。在许多情况下,这仅仅是舍入误差。如果在理论上可行的算法没有被设计为最小化舍入误差的累积,可能会在实践中失效,因此舍入误差是有问题的,特别是在某些操作复合时。
一种特别毁灭性的舍入误差是下溢。当接近零的数被四舍五入为零时发生下溢。许多函数会在其参数为零而不是一个很小的正数时才会表现出质的不同。例如,我们通常要避免被零除。
另一个极具破坏力的数值错误形式是上溢(overflow)。当大量级的数被近似为\infty 或-\infty时发生上溢。进一步的运算通常将这些无限值变为非数字。
必须对上溢和下溢进行数值稳定的一个例子是softmax 函数。softmax函数经常用于预测与multinoulli分布相关联的概率,定义为:

softmax函数在多分类问题中非常常见。这个函数的作用就是使得在负无穷到0的区间趋向于0,在0到正无穷的区间趋向于1。上面表达式其实是多分类问题中计算某个样本x_{i}的类别标签y_{i}属于K个类别的概率,最后判别y_{i}所属类别时就是将其归为对应概率最大的那一个。
当式中的w_{k} x_{i} +b都是很小的负数时,e^{w_{k} x_{i} +b } 就会发生下溢,这意味着上面函数的分母会变成0,导致结果是未定的;同理,当式中的x_{w_{k} x_{i} +b}是很大的正数时,e^{w_{k} x_{i} +b }就会发生上溢导致结果是未定的。
计算复杂性与NP问题:
- 算法复杂性
现实中大多数问题都是离散的数据集,为了反映统计规律,有时数据量很大,而且多数目标函数都不能简单地求得解析解。这就带来一个问题:算法的复杂性。
算法理论被认为是解决各类现实问题的方法论。衡量算法有两个重要的指标:时间复杂度和空间复杂度,这是对算法执行所需要的两类资源——时间和空间的估算。
一般,衡量问题是否可解的重要指标是:该问题能否在多项式时间内求解,还是只能在指数时间内求解?在各类算法理论中,通常使用多项式时间算法即可解决的问题看作是易解问题,需要指数时间算法解决的问题看作是难解问题。
指数时间算法的计算时间随着问题规模的增长而呈指数化上升,这类问题虽然有解,但并不适用于大规模问题。所以当前算法研究的一个重要任务就是将指数时间算法变换为多项式时间算法。
确定性和非确定性
除了问题规模与运算时间的比较,衡量一个算法还需要考虑确定性和非确定性的概念。
这里先介绍一下“自动机”的概念。自动机实际上是指一种基于状态变化进行迭代的算法。在算法领域常把这类算法看作一个机器,比较知名的有图灵机、玻尔兹曼机、支持向量机等。
所谓确定性,是指针对各种自动机模型,根据当时的状态和输入,若自动机的状态转移是唯一确定的,则称确定性;若在某一时刻自动机有多个状态可供选择,并尝试执行每个可选择的状态,则称为非确定性。
换个说法就是:确定性是程序每次运行时产生下一步的结果是唯一的,因此返回的结果也是唯一的;非确定性是程序在每个运行时执行的路径是并行且随机的,所有路径都可能返回结果,也可能只有部分返回结果,也可能不返回结果,但是只要有一个路径返回结果,那么算法就结束。
在求解优化问题时,非确定性算法可能会陷入局部最优。
NP问题
有了时间上的衡量标准和状态转移的确定性与非确定性的概念,我们来定义一下问题的计算复杂度。
P类问题就是能够以多项式时间的确定性算法来对问题进行判定或求解,实现它的算法在每个运行状态都是唯一的,最终一定能够确定一个唯一的结果——最优的结果。
NP问题是指可以用多项式时间的非确定性算法来判定或求解,即这类问题求解的算法大多是非确定性的,但时间复杂度有可能是多项式级别的。
但是,NP问题还要一个子类称为NP完全问题,它是NP问题中最难的问题,其中任何一个问题至今都没有找到多项式时间的算法。
机器学习中多数算法都是针对NP问题(包括NP完全问题)的。
- 数值计算
上面已经分析了,大部分实际情况中,计算机其实都只能做一些近似的数值计算,而不可能找到一个完全精确的值,这其实有一门专门的学科来研究这个问题,这门学科就是——数值分析(有时也叫作“计算方法”);运用数值分析解决问题的过程为:实际问题→数学模型→数值计算方法→程序设计→上机计算求出结果。
计算机在做这些数值计算的过程中,经常会涉及到的一个东西就是“迭代运算”,即通过不停的迭代计算,逐渐逼近真实值(当然是要在误差收敛的情况下)。
四、最优化
本节介绍机器学习中的一种重要理论——最优化方法。
- 最优化理论
无论做什么事,人们总希望以最小的代价取得最大的收益。在解决一些工程问题时,人们常会遇到多种因素交织在一起与决策目标相互影响的情况;这就促使人们创造一种新的数学理论来应对这一挑战,也因此,最早的优化方法——线性规划诞生了。
在李航博士的《统计学习方法》中,其将机器学习总结为如下表达式:机器学习 = 模型 + 策略 + 算法
可以看得出,算法在机器学习中的重要性。实际上,这里的算法指的就是优化算法。在面试机器学习的岗位时,优化算法也是一个特别高频的问题,大家如果真的想学好机器学习,那还是需要重视起来的。
- 最优化问题的数学描述
最优化的基本数学模型如下:

它有三个基本要素,即:
设计变量:x是一个实数域范围内的n维向量,被称为决策变量或问题的解;
目标函数:f(x)为目标函数; .
约束条件:h_{i} \left( x \right) =0称为等式约束,g_{i} \left( x \right) \leq 0为不等式约束,i=0,1,2,...
- 凸集与凸集分离定理
凸集
实数域R上(或复数C上)的向量空间中,如果集合S中任两点的连线上的点都在S内,则称集合S为凸集,如下图所示:

数学定义为:
设集合D\subset R^{n} ,若对于任意两点x,y\in D,及实数\lambda \left( 0\leq \lambda \leq 1 \right) 都有:\lambda x+\left( 1-\lambda \right) y\in D,则称集合D为凸集。
超平面和半空间
实际上,二维空间的超平面就是一条线(可以使曲线),三维空间的超平面就是一个面(可以是曲面)。其数学表达式如下:
超平面:H=\left\{ x\in R^{n} |a_{1}x-1 +a_{2}x_2+...+a_{n}x_n =b \right\}
半空间:H^{+} =\left\{ x\in R^{n} |a_{1}x-1 +a_{2}x_2+...+a_{n}x_n \geq b \right\}
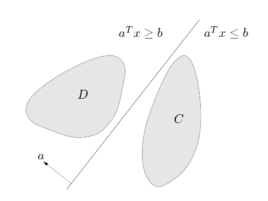
凸集分离定理
所谓两个凸集分离,直观地看是指两个凸集合没有交叉和重合的部分,因此可以用一张超平面将两者隔在两边,如下图所示:
凸函数
凸函数就是一个定义域在某个向量空间的凸子集C上的实值函数。

数学定义为:对于函数f(x),如果其定义域C是凸的,且对于∀x,y∈C,0\leq \alpha \leq 1,有:f\left( \theta x+\left( 1-\theta \right) y \right) \leq \theta f\left( x \right) +\left( 1-\theta \right) f\left( y \right),则f(x)是凸函数。
注:如果一个函数是凸函数,则其局部最优点就是它的全局最优点。这个性质在机器学习算法优化中有很重要的应用,因为机器学习模型最后就是在求某个函数的全局最优点,一旦证明该函数(机器学习里面叫“损失函数”)是凸函数,那相当于我们只用求它的局部最优点了。
- 梯度下降算法
引入
前面讲数值计算的时候提到过,计算机在运用迭代法做数值计算(比如求解某个方程组的解)时,只要误差能够收敛,计算机最后经过一定次数的迭代后是可以给出一个跟真实解很接近的结果的。
这里进一步提出一个问题,如果我们得到的目标函数是非线性的情况下,按照哪个方向迭代求解误差的收敛速度会最快呢?
答案就是沿梯度方向。这就引入了我们的梯度下降法。
梯度下降法
在多元微分学中,梯度就是函数的导数方向。
梯度法是求解无约束多元函数极值最早的数值方法,很多机器学习的常用算法都是以它作为算法框架,进行改进而导出更为复杂的优化方法。
在求解目标函数f\left( x \right)的最小值时,为求得目标函数的一个凸函数,在最优化方法中被表示为: math minf\left( x \right)
根据导数的定义,函数f\left( x \right)的导函数就是目标函数在x上的变化率。在多元的情况下,目标函数f\left( x,y,z \right)在某点的梯度grad f\left( x,y,z \right) =\left( \frac{\partial f}{\partial x} ,\frac{\partial f}{\partial y},\frac{\partial f}{\partial z} \right) 是一个由各个分量的偏导数构成的向量,负梯度方向是f\left( x,y,z \right)减小最快的方向。
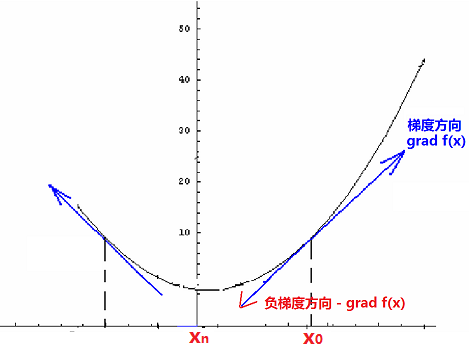
如上图所示,当需要求f\left( x \right)的最小值时(机器学习中的f\left( x \right) 一般就是损失函数,而我们的目标就是希望损失函数最小化),我们就可以先任意选取一个函数的初始点x_{0}(三维情况就是\left( x_{0} ,y_{0} ,z_{0} \right) ),让其沿着途中红色箭头(负梯度方向)走,依次到x_{1} ,x_{2} ,...,x_{n}(迭代n次)这样可最快达到极小值点。
梯度下降法过程如下:
输入:目标函数f\left( x \right) ,梯度函数g\left( x \right) =grad f\left( x \right) ,计算精度\varepsilon
输出:f\left( x \right) 的极小值点x^{*}
- 任取取初始值x_{0} ,置k=0;
- 计算f\left( x_{k} \right);
- 计算梯度g_{k} =grad f\left( x_{k} \right) ,当\left| \left| g_{k} \right| \right| <\varepsilon 时停止迭代,令x^{*} =x_{k};
- 否则令P_{k} =-g_{k},求\lambda _{k} 使f\left( x_{k+1} \right) =minf\left( x_{k} +\lambda _{k} P_{k} \right);
- 置x_{k+1} =x_{k} +\lambda _{k} P_{k} ,计算f\left( x_{k+1}\right) ,当\left| \left| f\left( x_{k+1}\right) -f\left( x_{k}\right) \right| \right| <\varepsilon 或\left| \left| x_{k+1} -x_{k} \right| \right| <\varepsilon 时,停止迭代,令x^{*} =x_{k+1};
- 否则,置k=k+1,转3。
- 随机梯度下降算法
上面可以看到,在梯度下降法的迭代中,除了梯度值本身的影响外,还有每一次取的步长\lambda _{k}也很关键:步长值取得越大,收敛速度就会越快,但是带来的可能后果就是容易越过函数的最优点,导致发散;步长取太小,算法的收敛速度又会明显降低。因此我们希望找到一种比较好的方法能够平衡步长。
随机梯度下降法并没有新的算法理论,仅仅是引进了随机样本抽取方式,并提供了一种动态步长取值策略。目的就是又要优化精度,又要满足收敛速度。
也就是说,上面的批量梯度下降法每次迭代时都会计算训练集中所有的数据,而随机梯度下降法每次迭代只是随机取了训练集中的一部分样本数据进行梯度计算,这样做最大的好处是可以避免有时候陷入局部极小值的情况(因为批量梯度下降法每次都使用全部数据,一旦到了某个局部极小值点可能就停止更新了;而随机梯度法由于每次都是随机取部分数据,所以就算局部极小值点,在下一步也还是可以跳出)
两者的关系可以这样理解:随机梯度下降方法以损失很小的一部分精确度和增加一定数量的迭代次数为代价,换取了总体的优化效率的提升。增加的迭代次数远远小于样本的数量。
- 牛顿法
牛顿法介绍
牛顿法也是求解无约束最优化问题常用的方法,最大的优点是收敛速度快。
从本质上去看,牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。通俗地说,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法 每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以, 可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。

或者从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
牛顿法的推导
将目标函数f\left( x \right) 在x_{k} 处进行二阶泰勒展开,可得:
因为目标函数f\left( x \right)有极值的必要条件是在极值点处一阶导数为0,即:f^{'} \left( x \right) =0。
所以对上面的展开式两边同时求导(注意x才是变量,x_{k}是常量\Rightarrow f^{'} \left( x_{k} \right) ,f^{''} \left( x_{k} \right) 都是常量),并令f^{'} \left( x \right) =0可得:
即:x=x_{k} -\frac{f^{'} \left( x_{k} \right) }{f^{''} \left( x_{k} \right) }
于是可以构造如下的迭代公式:x_{k+1} =x_{k} -\frac{f^{'} \left( x_{k} \right) }{f^{''} \left( x_{k} \right) }。
这样,我们就可以利用该迭代式依次产生的序列\left\{x_{1},x_{2},...., x_{k} \right\}才逐渐逼近f\left( x \right)的极小值点了。
牛顿法的迭代示意图如下:

上面讨论的是2维情况,高维情况的牛顿迭代公式是:
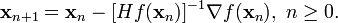
式中,▽f是f\left( x \right) 的梯度,即:
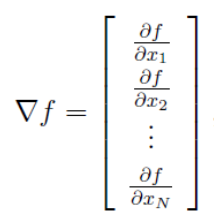
H是Hessen矩阵,即:

牛顿法的过程
- 给定初值x_{0}和精度阈值\varepsilon,并令k=0;
- 计算x_{k}和H_{k};
- 若\left| \left| g_{k} \right| \right| <\varepsilon则停止迭代;否则确定搜索方向:d_{k} =-H_{k}^{-1} \cdot g_{k};
- 计算新的迭代点:x_{k+1} =x_{k} +d_{k};
- 令k=k+1,转至2。
- 阻尼牛顿法
注意到,牛顿法的迭代公式中没有步长因子,是定步长迭代。对于非二次型目标函数,有时候会出现f\left( x_{k+1} \right) >f\left( x_{k} \right)的情况,这表明,原始牛顿法不能保证函数值稳定的下降。在严重的情况下甚至会造成序列发散而导致计算失败。
为消除这一弊病,人们又提出阻尼牛顿法。阻尼牛顿法每次迭代的方向仍然是x_{k},但每次迭代会沿此方向做一维搜索,寻求最优的步长因子\lambda _{k} ,即:
算法过程:
- 给定初值x_{0}和精度阈值\varepsilon,并令k=0;
- 计算g_{k} (f\left( x \right) 在x_{k}处的梯度值)和H_{k};
- 若\left| \left| g_{k} \right| \right| <\varepsilon 则停止迭代;否则确定搜索方向:d_{k} =-H_{k}^{-1} \cdot g_{k};
- 利用d_{k} =-H_{k}^{-1} \cdot g_{k} 得到步长\lambda _{k} ,并令x_{k+1} =x_{k} +\lambda _{k} d_{k}
- 令k=k+1,转至2。
- 拟牛顿法
由于牛顿法每一步都要求解目标函数的Hessen矩阵的逆矩阵,计算量比较大(求矩阵的逆运算量比较大),因此提出一种改进方法,即通过正定矩阵近似代替Hessen矩阵的逆矩阵,简化这一计算过程,改进后的方法称为拟牛顿法。
拟牛顿法的推导:
先将目标函数在x_{k+1}处展开,得到:
两边同时取梯度,得:
取上式中的x=x_{k},得:
即:g_{k+1} -g_{k} =H_{k+1} \cdot \left( x_{k+1} -x_{k} \right)
可得:H_{k}^{-1} \cdot \left( g_{k+1} -g_{k} \right) =x_{k+1} -x_{k}。
上面这个式子称为“拟牛顿条件”,由它来对Hessen矩阵做约束。
6.2 卷积神经网络(CNN)的结构设计
从LeNet5到VGG(基于深度的设计):LeNet5不是CNN的起点,但却是它的hello world,让大家看到了卷积神经网络商用的前景。
AlexNet是CNN向大规模商用打响的第一枪,夺得ImageNet 2012年分类冠军,宣告神经网络的王者归来。VGG以其简单的结构,在提出的若干年内在各大计算机视觉领域都成为了最广泛使用的benchmark。它们都有着简单而又优雅的结构,同出一门。诠释了增加深度是如何提高了深度学习模型的性能。
- LeNet5
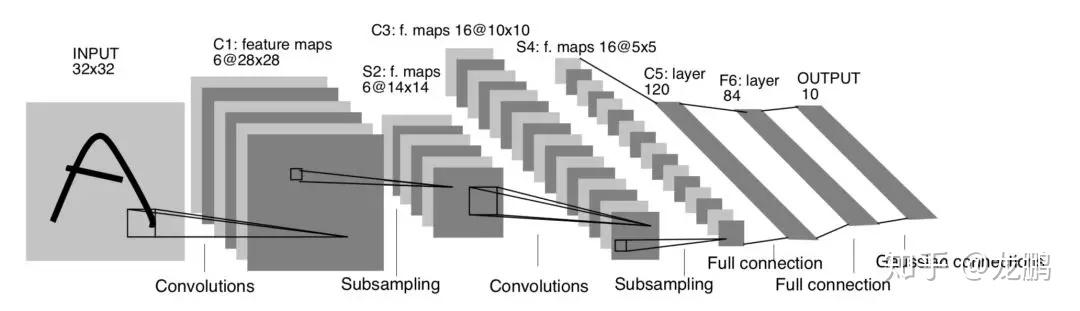
LeNet5有3个卷积层,2个池化层,2个全连接层。卷积层的卷积核都为5*5,stride=1,池化层都为Max pooling,激活函数为Sigmoid,具体网络结构如下图:
下面我们详细解读一下网络结构,先约定一些称呼。比如featuremap为28*28*6,卷积参数大小为(5*5*1)*6。其中28*28是featuremap的高度,宽度,6是featuremap的通道数。(5*5*1)*6卷积核表示5*5的高度,宽度,通道数为1的卷积核有6个。
- Input:输入图像统一归一化为32*32
- C1卷积层:经过(5*5*1)*6卷积核,stride=1,生成featuremap为28*28*6
- S2池化层:经过(2*2)采样核,stride=2,生成featuremap为14*14*6
- C3卷积层:经过(5*5*6)*16卷积核,stride=1,生成featuremap为10*10*16
- S4池化层:经过(2*2)采样核,stride=2,生成featuremap为5*5*16
- C5卷积层:经过(5*5*16)*120卷积核,stride=1,生成featuremap为1*1*120
- F6全连接层:输入为1*1*120,输出为1*1*84,总参数量为120*84
- Output全连接层:输入为1*1*84,输出为1*1*10,总参数量为84*10。10就是分类的类别数。
- AlexNet
2012年,Imagenet比赛冠军—Alexnet直接刷新了ImageNet的识别率,奠定了深度学习在图像识别领域的优势地位。网络结构如下图:
- Input:输入图像为224*224*3
- Conv1:经过(11*11*3)*96卷积核,stride=4,(224-11)/4+2=55,生成featuremap为55*55*96
- Pool1:经过3*3的池化核,stride=2,(55-3)/2+1=27,生成featuremap为27*27*96
- Norm1:local_size=5,生成featuremap为27*27*96
- Conv2:经过(5*5*96)*256的卷积核,pad=2,group=2,(27+2*2-5)/1+1=27,生成featuremap为27*27*256
- Pool2:经过3*3的池化核,stride=2,(27-3)/2+1=13,生成featuremap为13*13*256
- Norm2:local_size=5, 生成featuremap为13*13*256
- Conv3:经过(3*3*256)*384卷积核,pad=1,(13+1*2-3)/1+1=13,生成featuremap为13*13*384
- Conv4:经过(3*3*384)*384卷积核,pad=1,(13+1*2-3)/1+1=13,生成featuremap为13*13*384
- Conv5:经过(3*3*384)*256卷积核,pad=1,(13+1*2-3)/1+1=13,生成featuremap为13*13*256
- Pool5:经过(3*3)的池化核,stride=2,(13-3)/2+1=6,生成featuremap为6*6*256
- Fc6:输入为(6*6*256)*4096全连接,生成featuremap为1*1*4096
- Dropout6:在训练的时候以1/2概率使得隐藏层的某些神经元的输出为0,这样就丢掉了一半节点的输出,BP的时候也不更新这些节点,以下Droupout同理。
- Fc7:输入为1*1*4096,输出为1*1*4096,总参数量为4096*4096
- Dropout7:生成featuremap为1*1*4096
- Fc8:输入为1*1*4096,输出为1000,总参数量为4096*1000
总结:
- 网络比LeNet更深,包括5个卷积层和3个全连接层。
- 使用relu激活函数,收敛很快,解决了Sigmoid在网络较深时出现的梯度弥散问题。
- 加入了dropout层,防止过拟合。
- 使用了LRN归一化层,对局部神经元的活动创建竞争机制,抑制反馈较小的神经元放大反应大的神经元,增强了模型的泛化能力。
- 使用裁剪翻转等操作做数据增强,增强了模型的泛化能力。预测时使用提取图片四个角加中间五个位置并进行左右翻转一共十幅图片的方法求取平均值,这也是后面刷比赛的基本使用技巧。
- 分块训练,当年的GPU没有这么强大,Alexnet创新地将图像分为上下两块分别训练,然后在全连接层合并在一起。
- 总体的数据参数大概为240M。
- VGG
VGGNet主要的贡献是利用带有很小卷积核(3*3)的网络结构对逐渐加深的网络进行评估,结果表明通过加深网络深度至16-19层可以极大地改进前人的网络结构。这些发现也是参加2014年ImageNet比赛的基础,并且在这次比赛中,分别在定位和分类跟踪任务中取得第一名和第二名。
VGGNet的网络结构如下图:
类型从A到E。此处重点讲解VGG16。也就是图中的类型D。如图中所示,共有13个卷积层,3个全连接层。其全部采用3*3卷积核,步长为1,和2*2最大池化核,步长为2。
- Input层:输入图片为224*224*3。
- CONV3-64:经过(3*3*3)*64卷积核,生成featuremap为224*224*64
- CONV3-64:经过(3*3*64)*64卷积核,生成featuremap为224*224*64
- Max pool:经过(2*2)max pool核,生成featuremap为112*112*64
- CONV3-128:经过(3*3*64)*128卷积核,生成featuremap为112*112*128 CONV3-128:经过(3*3*128)*128卷积,生成featuremap为112*112*128
- Max pool:经过(2*2)maxpool,生成featuremap为56*56*128
- CONV3-256:经过(3*3*128)*256卷积核,生成featuremap为56*56*256
- CONV3-256:经过(3*3*256)*256卷积核,生成featuremap为56*56*256
- CONV3-256:经过(3*3*256)*256卷积核,生成featuremap为56*56*256
- Max pool:经过(2*2)maxpool,生成featuremap为28*28*256
- CONV3-512:经过(3*3*256)*512卷积核,生成featuremap为28*28*512
- CONV3-512:经过(3*3*512)*512卷积核,生成featuremap为28*28*512
- CONV3-512:经过(3*3*512)*512卷积核,生成featuremap为28*28*512
- Max pool:经过(2*2)maxpool,生成featuremap为14*14*512
- CONV3-512:经过(3*3*512)*512卷积核,生成featuremap为14*14*512
- CONV3-512:经过(3*3*512)*512卷积核,生成featuremap为14*14*512
- CONV3-512:经过(3*3*512)*512卷积核,生成featuremap为14*14*512
- Max pool:经过2*2卷积,生成featuremap为7*7*512
- FC-4096:输入为7*7*512,输出为1*1*4096,总参数量为7*7*512*4096
- FC-4096:输入为1*1*4096,输出为1*1*4096,总参数量为4096*4096
- FC-1000:输入为1*1*4096,输出为1000,总参数量为4096*1000。
总结:
- 共包含参数约为550M。
- 全部使用3*3的卷积核和2*2的最大池化核。
- 简化了卷积神经网络的结构。
https://www.zhihu.com/question/312556066 https://zhuanlan.zhihu.com/p/44106492 https://cloud.tencent.com/developer/article/1352583 https://www.leiphone.com/news/201709/AzBc9Sg44fs57hyY.html
1*1卷积(基于升维降维的设计)
11卷积本身只是NN卷积的卷积核半径大小退化为1时的特例,但是由于它以较小的计算代价增强了网络的非线性表达能力,给网络结构在横向和纵向拓展提供了非常好的工具,常用于升维和降维操作,尤其是在深层网络和对计算效率有较高要求的网络中广泛使用。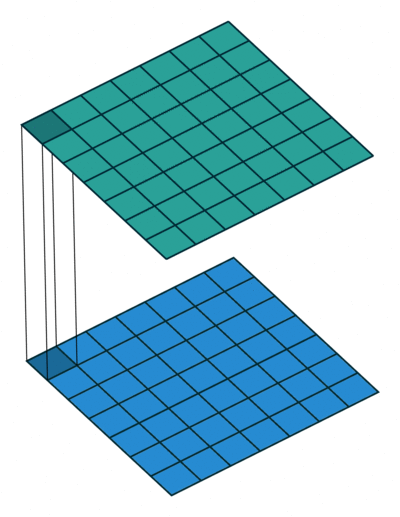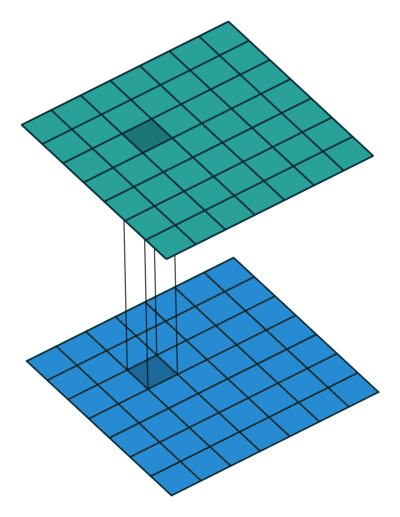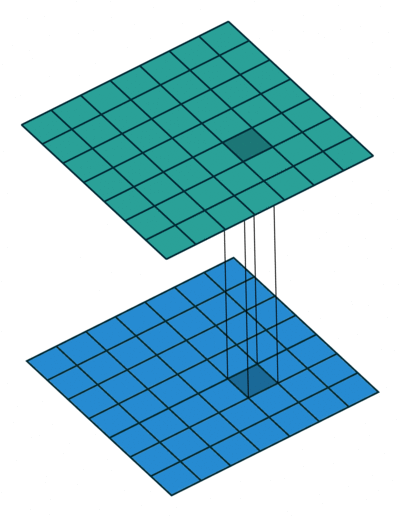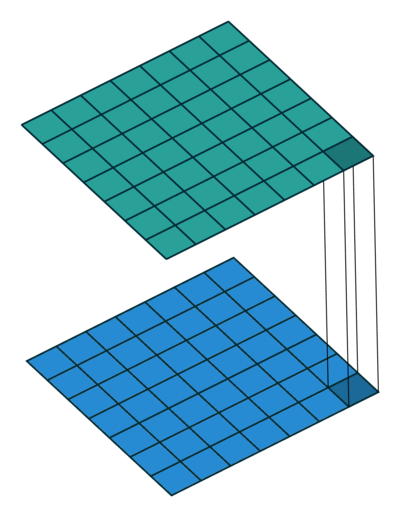 详细解读如下:【模型解读】network in network中的11卷积,你懂了吗03 GoogLeNet(基于宽度和多尺度的设计)GoogLeNet夺得ImageNet2014年分类冠军,也被称为Inception V1。Inception V1有22层深,参数量为5M。同一时期的VGGNet性能和Inception V1差不多,但是参数量却远大于Inception V1。Inception的优良特性得益于Inception Module,结构如下图:
详细解读如下:【模型解读】network in network中的11卷积,你懂了吗03 GoogLeNet(基于宽度和多尺度的设计)GoogLeNet夺得ImageNet2014年分类冠军,也被称为Inception V1。Inception V1有22层深,参数量为5M。同一时期的VGGNet性能和Inception V1差不多,但是参数量却远大于Inception V1。Inception的优良特性得益于Inception Module,结构如下图: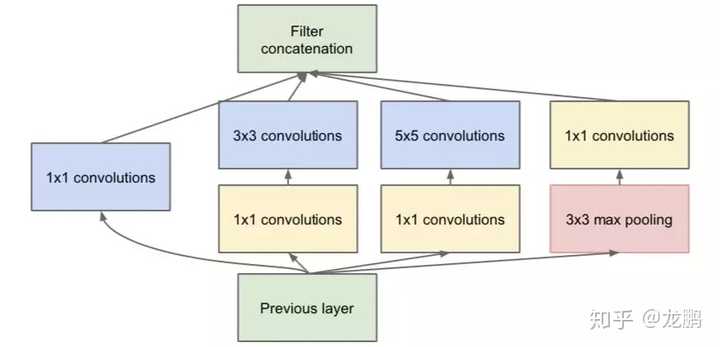 由11卷积,33卷积,55卷积,33最大池化四个并行通道运算结果进行融合,提取图像不同尺度的信息。如果说VGG是以深度取胜,那么GoogLeNet可以说是以宽度取胜,当然11卷积起到了很大的作用,这一点在SqueezeNet中也很关键。详细解读如下:【模型解读】GoogLeNet中的inception结构,你看懂了吗4 MobileNets(基于分组卷积的设计)脱胎于Xception的网络结构MobileNets使用Depthwise Separable Convolution(深度可分离卷积)构建了轻量级的28层神经网络,成为了移动端上的高性能优秀基准模型。
由11卷积,33卷积,55卷积,33最大池化四个并行通道运算结果进行融合,提取图像不同尺度的信息。如果说VGG是以深度取胜,那么GoogLeNet可以说是以宽度取胜,当然11卷积起到了很大的作用,这一点在SqueezeNet中也很关键。详细解读如下:【模型解读】GoogLeNet中的inception结构,你看懂了吗4 MobileNets(基于分组卷积的设计)脱胎于Xception的网络结构MobileNets使用Depthwise Separable Convolution(深度可分离卷积)构建了轻量级的28层神经网络,成为了移动端上的高性能优秀基准模型。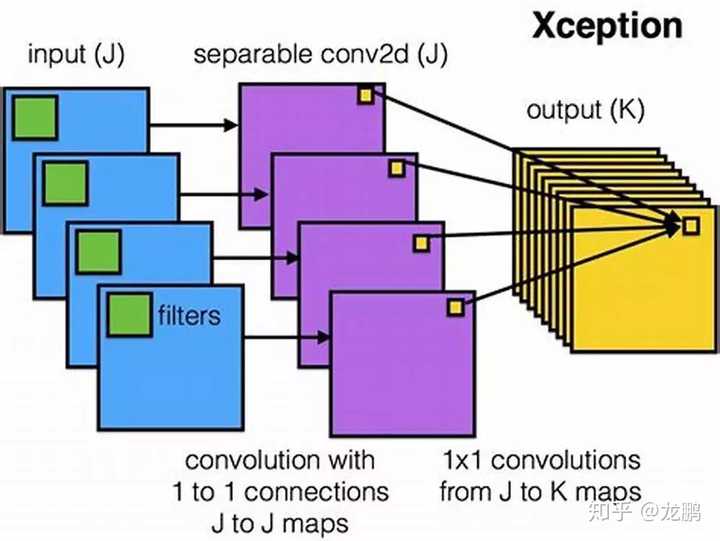 一个depthwise convolution,专注于该通道内的空间信息,一个pointwise convolution,专注于跨通道的信息融合,两者共同努力,然后强大,在此基础上的一系列模型如shufflenet等都是后话。详细解读如下:【模型解读】说说移动端基准模型MobileNets5 残差网络当深层网络陷身于梯度消失等问题而导致不能很有效地训练更深的网络时,脱胎于highway network的残差网络应运而生,附带着MSRA和何凯明的学术光环,诠释了因为简单,所以有效,但你未必能想到和做到的朴素的道理。
一个depthwise convolution,专注于该通道内的空间信息,一个pointwise convolution,专注于跨通道的信息融合,两者共同努力,然后强大,在此基础上的一系列模型如shufflenet等都是后话。详细解读如下:【模型解读】说说移动端基准模型MobileNets5 残差网络当深层网络陷身于梯度消失等问题而导致不能很有效地训练更深的网络时,脱胎于highway network的残差网络应运而生,附带着MSRA和何凯明的学术光环,诠释了因为简单,所以有效,但你未必能想到和做到的朴素的道理。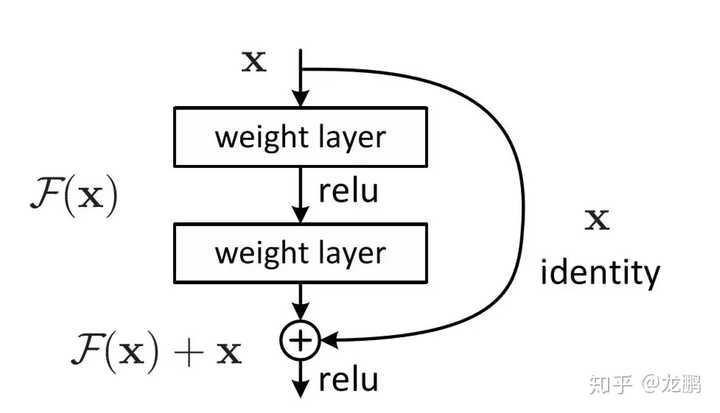 详细解读如下:【模型解读】resnet中的残差连接,你确定真的看懂了?6 非正常卷积(基于不规则卷积和感受野调整的设计)谁说卷积一定要规规矩矩四四方方呢?MSRA总是一个出新点子的地方,在spatial transform network和active convolution的铺垫下,可变形卷积deformable convolution network如期而至。
详细解读如下:【模型解读】resnet中的残差连接,你确定真的看懂了?6 非正常卷积(基于不规则卷积和感受野调整的设计)谁说卷积一定要规规矩矩四四方方呢?MSRA总是一个出新点子的地方,在spatial transform network和active convolution的铺垫下,可变形卷积deformable convolution network如期而至。 文章依旧写的很简单,这是一个致力于提升CNN对具有不同几何形变物体识别能力的模型,关键在于可变的感受野。【模型解读】“不正经”的卷积神经网络7 密集连接网络(残差网络的升级,极致的不同层间的信息融合)说起来,DenseNet只不过是残差网络的升级版,将网络中的每一层都直接与其前面层相连,把残差做到了极致,提高了特征的利用率;因为可以把网络的每一层设计得很窄,提高计算性能。
文章依旧写的很简单,这是一个致力于提升CNN对具有不同几何形变物体识别能力的模型,关键在于可变的感受野。【模型解读】“不正经”的卷积神经网络7 密集连接网络(残差网络的升级,极致的不同层间的信息融合)说起来,DenseNet只不过是残差网络的升级版,将网络中的每一层都直接与其前面层相连,把残差做到了极致,提高了特征的利用率;因为可以把网络的每一层设计得很窄,提高计算性能。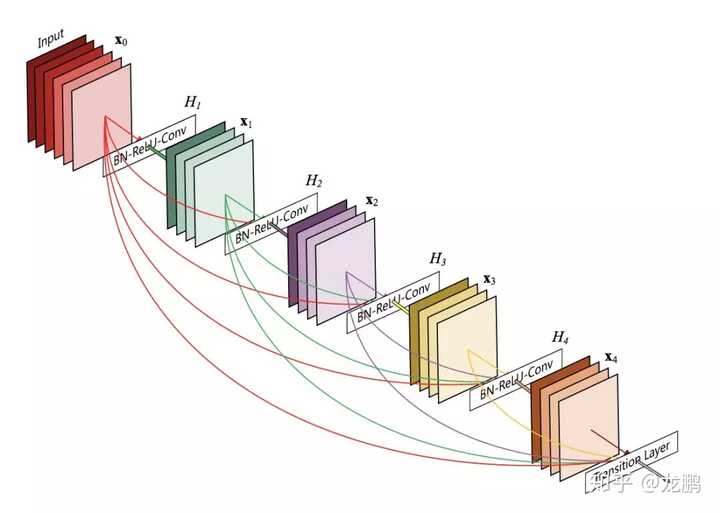 不过还是那句话,就算你能想到,也未必能做到,我们还是单独详细解读如下:【模型解读】全连接的卷积网络,有什么好?8 非局部神经网络(充分提高层内感受野的设计)卷积神经网络因为局部连接和权重共享而成功,但是它的感受野是有限的。为了这样,我们不得不使用更深的网络,由此带来了三个问题。(1) 计算效率不高。(2) 感知效率不高。(3) 增加优化难度。这一次又是学神凯明带队出发,从传统降噪算法Non-Local中完成借鉴。
不过还是那句话,就算你能想到,也未必能做到,我们还是单独详细解读如下:【模型解读】全连接的卷积网络,有什么好?8 非局部神经网络(充分提高层内感受野的设计)卷积神经网络因为局部连接和权重共享而成功,但是它的感受野是有限的。为了这样,我们不得不使用更深的网络,由此带来了三个问题。(1) 计算效率不高。(2) 感知效率不高。(3) 增加优化难度。这一次又是学神凯明带队出发,从传统降噪算法Non-Local中完成借鉴。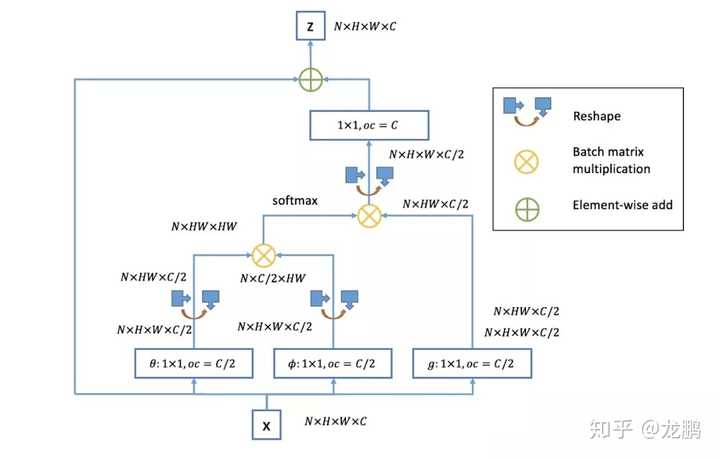 虽非真主流,了解一下也无妨。【模型解读】从“局部连接”回到“全连接”的神经网络9 多输入网络(一类有多种应用的网络)见惯了输入一个图像或者视频序列,输出分类,分割,目标检测等结果的网络,是否会想起输入两张,或者多张图片来完成一些任务呢,这就是多输入网络结构。
虽非真主流,了解一下也无妨。【模型解读】从“局部连接”回到“全连接”的神经网络9 多输入网络(一类有多种应用的网络)见惯了输入一个图像或者视频序列,输出分类,分割,目标检测等结果的网络,是否会想起输入两张,或者多张图片来完成一些任务呢,这就是多输入网络结构。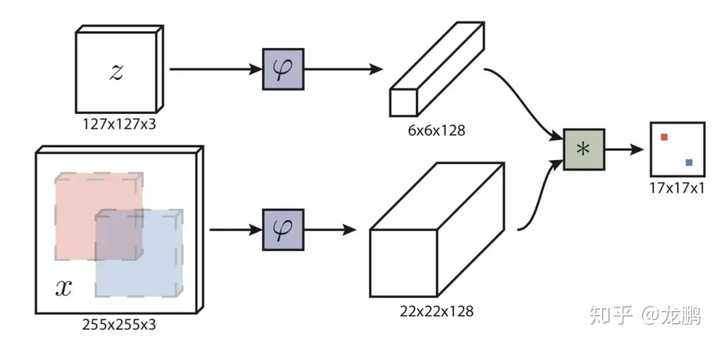 从检索,比对,到排序,跟踪,它可以做的事情有很多,你应该了解一下。【模型解读】深度学习网络只能有一个输入吗10 3D卷积(将卷积升维到3D空间设计)2D卷积玩腻了,该跳到更加高维的卷积了,常见的也就是3D卷积了。
从检索,比对,到排序,跟踪,它可以做的事情有很多,你应该了解一下。【模型解读】深度学习网络只能有一个输入吗10 3D卷积(将卷积升维到3D空间设计)2D卷积玩腻了,该跳到更加高维的卷积了,常见的也就是3D卷积了。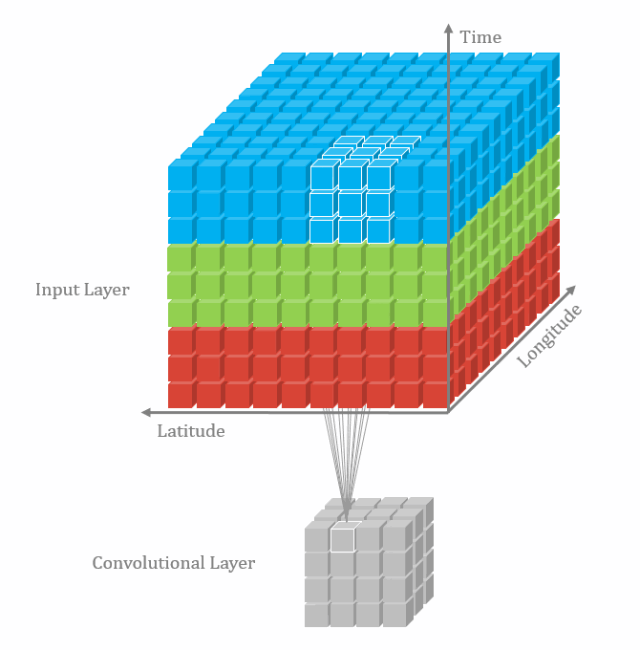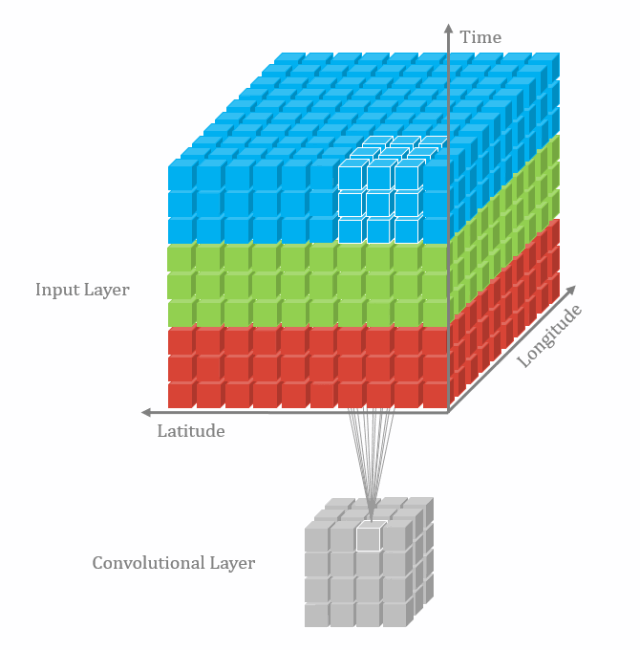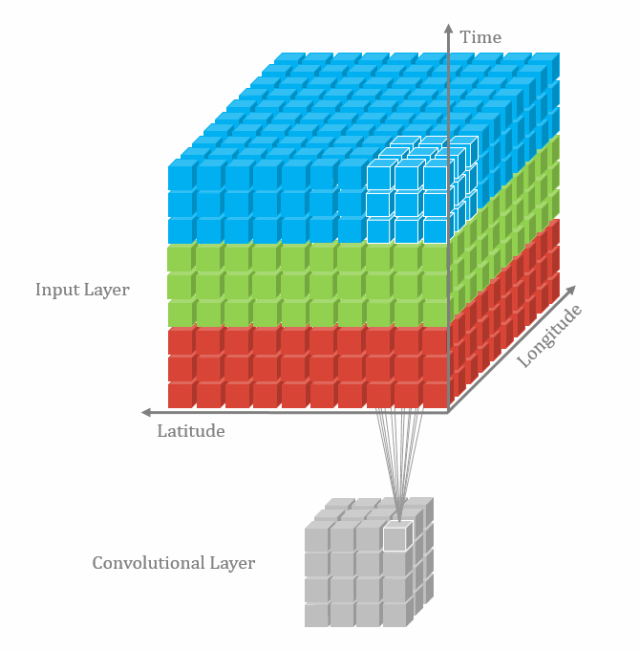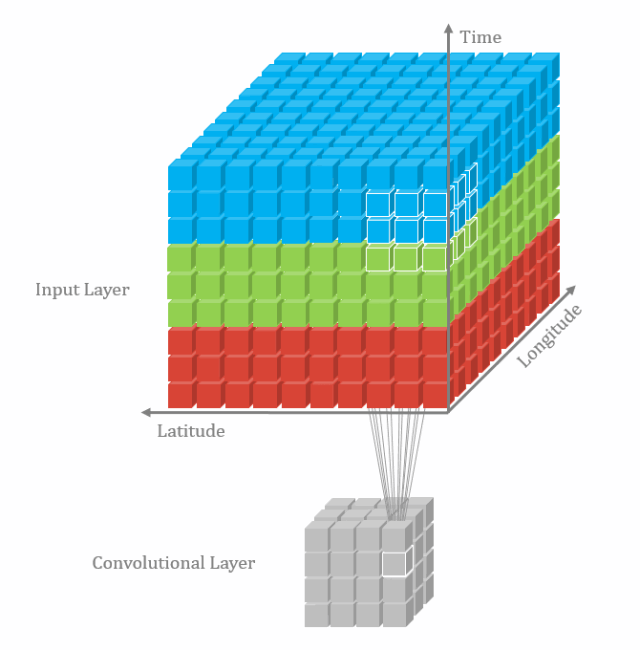 虽然3D带来了暴涨的计算量,但是想想可以用于视频分类和分割,3D点云,想想也是有些小激动呢。【模型解读】从2D卷积到3D卷积,都有什么不一样11 RNN和LSTM(时序网络结构模型)不是所有的输入都是一张图片,有很多的信息是非固定长度或者大小的,比如视频,语音,此时就轮到RNN,LSTM出场了。
虽然3D带来了暴涨的计算量,但是想想可以用于视频分类和分割,3D点云,想想也是有些小激动呢。【模型解读】从2D卷积到3D卷积,都有什么不一样11 RNN和LSTM(时序网络结构模型)不是所有的输入都是一张图片,有很多的信息是非固定长度或者大小的,比如视频,语音,此时就轮到RNN,LSTM出场了。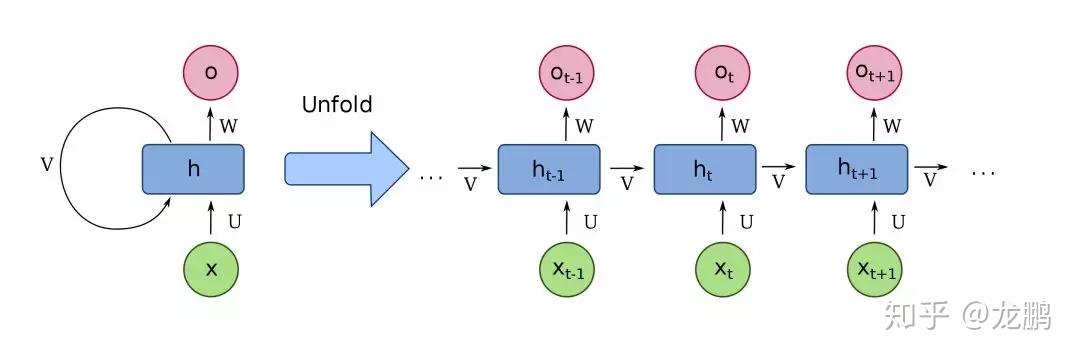 话不多说,好好学:【模型解读】浅析RNN到LSTM12 GAN(近两年最火的下一代无监督深度学习网络)近几年来无监督学习领域甚至是深度学习领域里最大的进展非生成对抗网络GAN莫属,被誉为下一代深度学习,不管是研究热度还是论文数量,已经逼近甚至超越传统判别式的CNN架构。在研究者们的热情下,GAN已经从刚开始的一个生成器一个判别器发展到了多个生成器多个判别器等各种各样的结构。
话不多说,好好学:【模型解读】浅析RNN到LSTM12 GAN(近两年最火的下一代无监督深度学习网络)近几年来无监督学习领域甚至是深度学习领域里最大的进展非生成对抗网络GAN莫属,被誉为下一代深度学习,不管是研究热度还是论文数量,已经逼近甚至超越传统判别式的CNN架构。在研究者们的热情下,GAN已经从刚开始的一个生成器一个判别器发展到了多个生成器多个判别器等各种各样的结构。 快上车,因为真的快来不及了。【模型解读】历数GAN的5大基本结构 还有很多精力有限,以下是分割线,未完待续┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉编辑于 2019-02-17
快上车,因为真的快来不及了。【模型解读】历数GAN的5大基本结构 还有很多精力有限,以下是分割线,未完待续┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉┉┉ ∞ ∞ ┉┉┉┉ ∞ ∞ ┉┉┉编辑于 2019-02-17
https://www.zhihu.com/question/291032522/answer/605843215 1471 https://www.zhihu.com/question/312556066
https://zhuanlan.zhihu.com/p/83578219