题目1143:最长公共子序列
题目描述
给定两个字符串text1和text2,返回这两个字符串的最长公共子序列的长度。
一个字符串的子序列是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。例如,"ace"是"abcde"的子序列,但"aec"不是"abcde"的子序列。两个字符串的公共子序列是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回0。
示例 1:
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是"ace",它的长度为3。
示例2:
输入:text1 = "abc", text2 = "abc"
输出:3
解释:最长公共子序列是"abc",它的长度为3。
示例3:
输入:text1 = "abc", text2 = "def"
输出:0
解释:两个字符串没有公共子序列,返回0。
提示:
1 <= text1.length <= 1000
1 <= text2.length <= 1000
输入的字符串只含有小写英文字符。
解答技巧
- 动态规划思路
第一步,一定要明确dp数组的含义。对于两个字符串的动态规划问题,套路是通用的。比如说对于字符串s1和s2,一般来说都要构造一个这样的DP table:
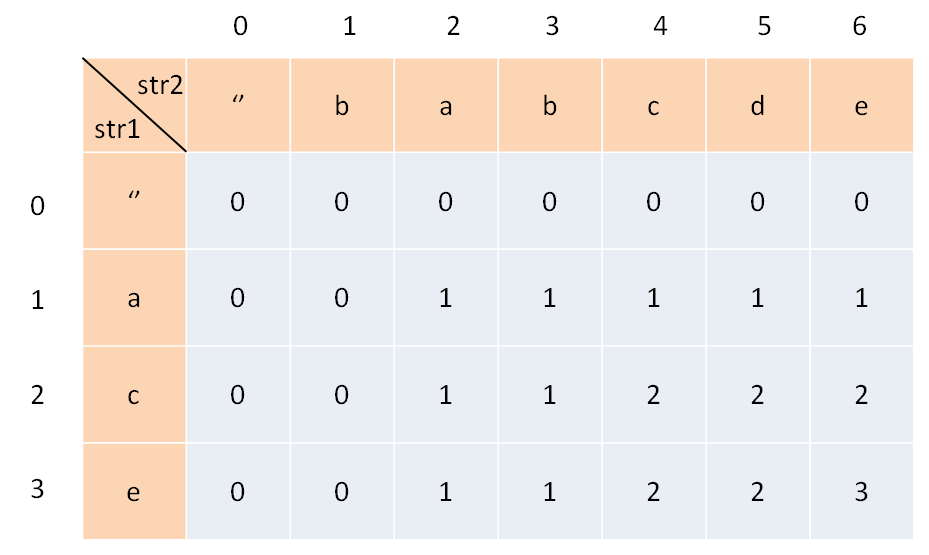
为了方便理解此表,我们暂时认为索引是从1开始的,待会的代码中只要稍作调整即可。其中,dp[i][j]的含义是:对于s1[1..i]和s2[1..j],它们的LCS长度是dp[i][j]。
比如上图的例子,d[2][4]的含义就是:对于"ac"和"babc",它们的LCS长度是2。我们最终想得到的答案应该是dp[3][6]。
第二步,定义base case。
我们专门让索引为0的行和列表示空串,dp[0][..]和dp[..][0]都应该初始化为0,这就是base case。
比如说,按照刚才dp数组的定义,dp[0][3]=0的含义是:对于字符串""和"bab",其LCS的长度为0。因为有一个字符串是空串,它们的最长公共子序列的长度显然应该是0。
第三步,找状态转移方程。
这是动态规划最难的一步,不过好在这种字符串问题的套路都差不多,权且借这道题来聊聊处理这类问题的思路。
状态转移说简单些就是做选择,比如说这个问题,是求s1和s2的最长公共子序列,不妨称这个子序列为lcs。那么对于s1和s2中的每个字符,有什么选择?很简单,两种选择,要么在lcs中,要么不在。
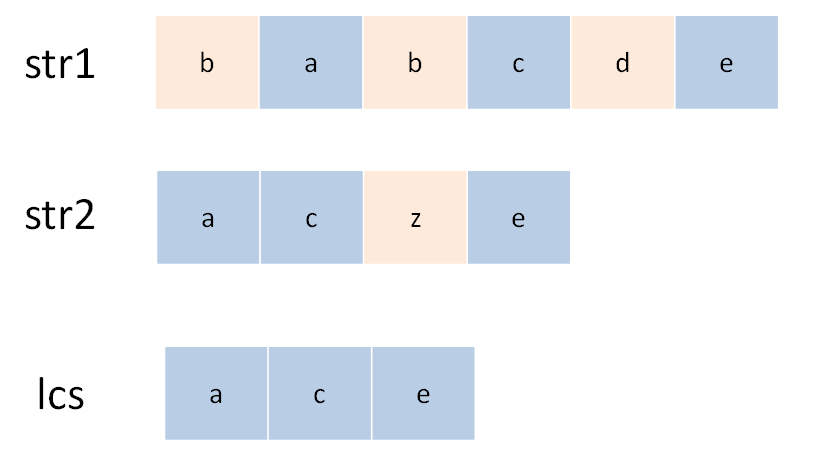
这个在和不在就是选择,关键是,应该如何选择呢?这个需要动点脑筋:如果某个字符应该在lcs中,那么这个字符肯定同时存在于s1和s2中,因为lcs是最长公共子序列嘛。所以本题的思路是这样:
用两个指针i和j从后往前遍历s1和s2,如果s1[i]==s2[j],那么这个字符一定在lcs中;否则的话,s1[i]和s2[j]这两个字符至少有一个不在lcs中,需要丢弃一个。先看一下递归解法,比较容易理解:
def longestCommonSubsequence(str1, str2) -> int:
def dp(i, j):
# 空串的base case
if i == -1 or j == -1:
return 0
if str1[i] == str2[j]:
# 这边找到一个lcs的元素,继续往前找
return dp(i - 1, j - 1) + 1
else:
# 谁能让lcs最长,就听谁的
return max(dp(i-1, j), dp(i, j-1))
# i和j初始化为最后一个索引
return dp(len(str1)-1, len(str2)-1)
对于第一种情况,找到一个lcs中的字符,同时将i,j向前移动一位,并给lcs的长度加一;对于后者,则尝试两种情况,取更大的结果。
其实这段代码就是暴力解法,我们可以通过备忘录或者DP table来优化时间复杂度,比如通过前文描述的DP table来解决:
def longestCommonSubsequence(str1, str2) -> int:
m, n = len(str1), len(str2)
# 构建DP table和base case
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 进行状态转移
for i in range(1, m + 1):
for j in range(1, n + 1):
if str1[i - 1] == str2[j - 1]:
# 找到一个lcs中的字符
dp[i][j] = 1 + dp[i-1][j-1]
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
return dp[-1][-1]
第四步,空间压缩
从i的角度来看, 只与前一行有关,其他行无关。可以根据此进行空间压缩,准备一个dp n+1的长度,其实的0位置存放一个空字符串
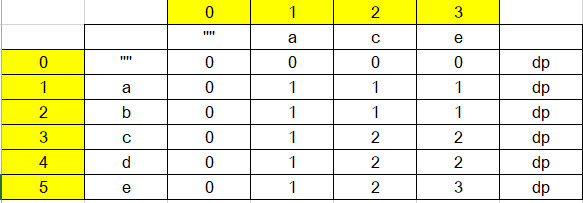

准备几个变量:
last:表示是当前dp[j](dp[i][j])左上角的数,相当于dp[i-1][j-1],初始化的时候为0
tmp:表示是当前dp[j](dp[i][j])正上方的数,相当于dp[i- 1][j]
dp[j-1]:表示是当前dp[j](dp[i][j])左边的数,相当于dp[i][j-1]每一轮结束后,last的值都向前滚动一个,变成正上方的数,也就是tmp
class Solution:
def longestCommonSubsequence(self, text1: str, text2: str) -> int:
m, n = len(text1), len(text2)
if m==0 or n==0: return 0;
dp = [0]*(n+1)
tmp = 0
for i in range(1,m+1,1):
last =0
for j in range(1,n+1,1):
tmp = dp[j]
if text1[i-1] == text2[j-1]:
dp[j]=last+1
else:
dp[j]=max(tmp, dp[j-1]);
last = tmp;
return dp[n]