python基础教程
参考:python标准库
一、python基础
1.1.简化版python解释器
python解释器主要包含了两大部分,一个部分相当于编译器,另一个部分相当于虚拟机.python解释器的编译器部分首先把程序编译成中间码(字节码),再由python解释器里的虚拟机部分(python Virtual Machine(PVM))运行字节码.
1.2 简化版对象(object)与类(class)
我们知道,给函数提供输入(input),则函数会处理输入(input),返回结果(output)或者不返回.程序就是解决问题的一系列步骤,这被称为面向过程(Procedure Oriented)的编程方式.后来编程语言中出现了一种面向对象(Object Orientend)的思想,简单来说,对象借鉴了现实世界由一个个客体组成的概念,用一个个对象间的互动来组织起程序,跟现实世界的客体类似,对象有自己的特征(对象里的各种值),对象也有自己能够做到的事(通过对象里的各种方法).对象里的各种值被叫做对象的字段(field),对象里的各种方法被叫做对象的方法(method),对象的字段跟方法统称为对象的属性(attribute).
对象的字段类似于编程语言里的普通变量,所不同的是对象的字段是对象独有的.如果一个对象叫a,a有个属性是b,我们如何访问b呢?答案是通过a.b这种形式的写法访问。a.b的意思就是a的属性b。
对象的方法类似于编程语言中的函数,所不同的是对象的方法是对象独有的,如果一个对象叫c,c有个方法是d,我们如何使用(调用)d呢?答案是通过c.d()这种形式的写法来是使用,d方法可以带参数,形如这样:c.d(a)。c.d()的意思就是使用(调用)c的方法d。
如何实现对象呢?有一种方法就是通过类(class)来实现。对象对应于现实中一个个具体的客体,这些客体各不相同,但是很明显,有一些客体是可以归到同一个阵营里去的,比如所有的人,所有的苹果,所有的猫,这里的人、苹果、猫是抽象的一般概念,程序中的类(class)就是基于像这样的一般概念而抽象出来的某一类客体的模板,可以是人的类,苹果的类,猫的类。从类(模板)中可以构造出这一类客体的对象。从类到对象,相当于从蓝图中实现了一个对象,所以可以说某对象是某个类的一个实例(实现了的例子)。反过来,某个类规定了将要实现的对象的该有的属性跟方法,跟别的类实现的对象有了区别,所以对象的类型(type)就是它所承袭的类。
1.3 简化版调用栈(call stack)和堆(heap)
内存(memory):是指计算中的随机存取内存(random access memory(RAM))。可以认为,内存是一张很大的表,其中的每个表格(1个字节)有两个属性:地址和值。地址表示了某个表格在内存这张大表中的位置,因此我们可以通过地址找到该表格;一旦找到该表格,就可以对该表格的值进行擦除并重写的操作,或者只是读取该表格的值。具体的细节我们可以不用去考虑,我们需要更加抽象的思考地址和值,任意大小的一块内存都可以有一个(标识)地址来让我们在整个内存中找到它,该内存块中能存储复杂的值。
程序要运行时,操作系统就会给它分配一块可用的内存,或者由某高级语言虚拟机提供运行时环境。在该内存空间(运行时环境)里,首先会载入程序本身(机器码或者字节码),接下来会载入整个程序可以用的东西(全局(类)变量,模块等),除此之外的内存会划分为两种,一种是程序运行时的调用栈(call stack),另一种则是堆(heap)。在这里,内存并非计算机中真实的物理内存,而是由操作系统通过软硬件结合的一种技术分配的一块虚拟内存,该虚拟内存中的虚拟地址跟计算机中真实的物理内存地址之间有着映射的关系。在这样的虚拟内存空间里,地址是连续的,也就是说程序运行在某一块特定的虚拟内存中,可以想象成一个长块儿。
当程序运行时,主函数(main函数)或者首先被执行的函数(方法)会被放入到调用栈中,因为调用栈中只有这一帧,所以它处在调用栈的顶层,一旦处在调用栈的顶层,就会被激活,被激活的帧(frame)得到程序的执行权,该帧中的代码被一步步执行,我们把这一帧姑且叫第0帧吧。第0帧中调用另一个函数(方法)时,被调用函数(方法)的帧被放入到调用栈的最顶层,我们把这一帧叫第1帧,现在,被激活的帧就变成了第1帧,程序的执行权转移到第1帧中,它首先会把被调用时传进来的参数(如果有)存储,接着就声明和初始化局部(实例)变量,操作变量...,当第1帧调用另一个函数(方法)时,被调用函数(方法)的帧被放入到调用栈的最顶层,我们把这一帧叫第2帧,如前所述,第2帧被激活,得到程序执行权,当第2帧执行结束,返回值(如果有),这时候第2帧的内存被销毁,包括其中的局部(实例)变量、参数等等,第2帧在调用栈中不在存在,这时候,第1帧成为调用栈的顶层,程序的执行权又重新回到第1帧,第1帧继续执行剩余的代码,当第1帧执行结束,返回值(如果有),第1帧被销毁,调用栈中最顶层的帧重新变成第0帧,如果第0帧执行结束,则调用栈空白...,这其中,被调用函数(方法)放入调用栈最顶层被称为推入(push),而在调用栈中被销毁则被称为弹出(pop)。
调用栈(call stack)中的函数(方法)里存储着程序运行过程中该如何做的行为(动作、指令)和需要处理的局部(实例)变量,这些变量实际上是怎么被存储的呢?不同的编程语言有不同的存储方式,实际上有两种最为主流的做法。
变量的值有各种各样的类型,像简单的数字,布尔值,字符串...,对于这些比较简单的值,一种方法就是把它们看做原始(内置)类型,直接在调用栈内存中分配出一块能容纳该类型值的内存,把该值存进去,通过变量名来使用该值。这时候变量仿佛就是这些值了。这种存储类型又被称为值类型(value type)。需要注意的是,静态类型语言中的变量是有类型的,一旦声明成某种类型的,则只能存储该类型的值;动态类型语言中的变量不存在类型,可以存储任何类型的值。
对于简单的数字,布尔值,字符串...这些类型的值,另一种方法就是把它们都存在堆(heap)内存空间里。在调用栈中的变量里,实际存储的是堆(heap)内存空间里的某一块内存的地址。当一个变量被声明并且被赋值的时候发生了什么呢?实际上发生的是首先在堆(heap)内存空间中分配出一块能容纳该类型值的内存,把该值存进去;然后把该内存的地址绑定到变量上。这时候我们就说该变量引用(reference) 了该值。这种存储类型被称为引用类型(reference type)。有时候也能够看到这种说法:变量里存储的是值的引用,可以看到,值的内存地址跟值的引用的说法可以互换。
前面我们简略介绍了对象,对象可以看做是种复杂类型的值,你可以想想,对象里的各种属性和各种方法。那么当我们有一个对象的时候,或者有某个复杂类型的值的时候,不同的编程语言都不约而同的选择了堆(heap)内存空间。这是为什么呢?因为调用栈中的值需要的内存块的大小一旦确定就不能改变,而堆则没有这个限制,有可能一个对象占用很大的一块内存,并且在程序运行过程中动态的变大或者变小。
1.4 数据类型
变量用来存储值,值可以被改变。正如我们之前好几次说到的那样,值的类型各种各样,但都携带了某种信息,并且这种信息可以被操作(处理),我们可以认为,它们都是数据(data)。
数据的类型(type)是各种各样的,python中非常普遍数据类型有:数字,布尔值,字符串。对这些简单的数据类型,我们已经知道普遍存在的两种存储方式,那么在在python中,一切数据类型都是对象,所以,我们存储任何数据类型的方式都是通过引用(reference)。
在python中有个内置函数type(),可以通过它来检查一个对象的类型:
type(1) # <class 'int'>
type(1.1) # <class 'float'>
type("int") # <class 'str'>
type(True) # <class 'bool'>
出现的是四种简单的数据类型,分别是int,float,str,bool。如果两个变量同时引用了相同的对象,会发生什么呢?在python中有个内置的函数id(),这个函数返回对象的一个id,可以把该id看做该对象的引用(内存地址)。让我们看看两个变量同时引用相同的对象时发生了什么:
a,b=1,1
id(a) # 255681632
id(b) # 255681632
可以看到,两个变量指向了同一个对象,那么当我们改变了其中某个变量引用的对象,是不是另一个变量引用的对象也同时改变了呢?从理论上讲会改变,对吧,因为是同一个对象。我们来看看:
a,b=1,1
id(a) # 255681632
id(b) # 255681632
b=2 # 改变b的值
a # 1
事实并不像我们认为的那样,另一个变量的对象并没有改变。这是因为,在python中上面出现的这四种简单的数据类型都是不可变(immutable)对象。举个数字的例子来理解这种不可变性:数字1是个对象,是个独立的客体,看起来这个对象简单到不能再简单,我们无法改变它,如果将变量的引用从数字1改变成数字2,那么,已经是另一个对象了,相当于是更新了变量的引用。
1.4.1 列表(list)
直到现在,我们处理过的数据类型都很简单,但是当我们想要存储更为复杂多变的数据,用我们目前知道的数据类型来存储就会越来越繁琐,容易出错了。比如我们想要在程序里一次性处理包含6个数字的内容(7,9,11,36,74,12),难道我们要给每个数字都提供一个变量名,并一一存储吗?我们还有更多选择,在python中,它提供了一种叫列表(list)的数据类型,这种数据类型像个容器,可以装进去其他各种数据类型,甚至也可以将其他列表(list)嵌套进去。我们要把7,9,11,36,74,12放进一个列表(list)中,可以这么做:
# 把这几个数字放进列表,并赋值给变量x
x=[7,9,11,36,74,12]
# 可以定义一个空列表
y=[]
# 使用内置函数list()创建列表
a=list("abc")
b=list()
现在把数字放进一个列表了,那么我们怎么拿出某个数字呢?跟字符串类似,列表中的元素组成了一串,每个元素在列表中都是有顺序的。每个元素都被分配了一个位置索引(index)。我们可以通过特定的索引来访问对应的元素,根据惯例,索引总是从0开始。
x=[7,9,11,36,74,12]
z=len(x)
# 从列表x中循环取出数字,并打印到命令行
for index in range(z):
print(str(x[index]))
列表中的元素的值能不能改变呢?能不能增加或者减少元素?答案是可以的。我们说python中一切数据类型都是对象,列表也是对象,所有它有自己的专属方法。可以通过列表的append()方法来增加元素,增加的元素被追加到列表结尾。删除一个元素呢,可以通过del语句来删除,也可以通过列表的remove()方法或者pop()方法来删除。这里要注意,remove方法通过值来删除,pop方法通过索引来删除,并且remove方法没有返回值,而pop方法则返回要删除的值。如果我们不只想删除某一个元素,而是想清空整个列表,则可以使用列表的clear()方法。看下面:
a=['change me',['first',1,2],2019,True]
# 以下注释都根据惯例,从0开始计数
# 改变第0个元素的值
a[0]='changed'
print('列表a: {}'.format(a))
# 改变第1个元素(list)中的第0个元素
a[1][0]=0
print('列表a: {}'.format(a))
# 增加一个元素
a.append(2019)
print('列表a: {}'.format(a))
# 删除一个元素,通过del语句
del a[0]
print('列表a: {}'.format(a))
# 删除一个元素,通过remove方法
a.remove(True)
print('列表a: {}'.format(a))
# 删除一个元素,通过pop方法,并将返回值赋给变量b
b=a.pop(2)
print("被删除的元素是{}".format(b))
print('列表a: {}'.format(a))
# 清空列表
a.clear()
print('列表a: {}'.format(a))
以上代码中,用到了str的format()方法,这种方法通过在字符串保留一对{},来让format方法中的参数填充其中,参数可以是任意多个(需要与前面{}的数量一致),可以是各种数据类型。这个方法大大简化了我们想把其他数据类型加入到字符串的过程。运行结果如下:
列表a: ['changed', ['first', 1, 2], 2019, True]
列表a: ['changed', [0, 1, 2], 2019, True]
列表a: ['changed', [0, 1, 2], 2019, True, 2019]
列表a: [[0, 1, 2], 2019, True, 2019]
列表a: [[0, 1, 2], 2019, 2019]
被删除的元素是2019
列表a: [[0, 1, 2], 2019]
列表a: []
既然python中的数据类型都是对象,那么我们如何判断两个对象是否是同一个呢。答案用is操作符,比如我们想要判断a对象与b对象是否同一个,则可以通过a is b来判断,其结果是布尔值。
我们看到,列表里的元素可以比一个多,字符串里的字符也可以比一个多,所以我们给这种其中的元素或者属性可以比一个多的对象运用in操作符(查看某元素是否属于该对象,这被称为成员检测),来提供给for循环语句或者别的语句,让这些语句逐个访问其中的元素或者属性,这个行为可以称为迭代。前面说到的内置函数list()可接受的参数就是可以被迭代的对象。上篇文章中讲到的for...in循环就是迭代的一个例子。
# in操作符的例子
x='hello'
'h' in x # True
在讲列表(list)之前,我们说到了不可变对象。那么列表的情况又是如何呢?我们把那个例子中的数据类型换成列表来看看:
a=['change me',['first',1,2],2019,True]
# 把同样的引用赋值给变量b
b=a
# 看看引用是否相同,是否对象是同一个
print(a is b)
# 通过变量b改变列表
b[0]='changed'
# 现在打印出变量a,看是否有变化
print(a)
以上代码运行结果如下:
True
['changed', ['first', 1, 2], 2019, True]
从运行结果来看,列表是可以改变的,所以是可变(mutable)对象。现在我们已经把可变对象和不可变对象的行为差不多摸清楚了。讲不可变对象的时候我们讲解了一个数字对象的例子来帮助理解不可变对象,现在我们来通过字符串的例子来进一步说明,假如我们把一个字符串“string”的引用赋值给变量a,那么我们是不能对其中的字符来进行修改的,如下图:
>>> a="string"
>>> a[0]="a"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
但是对于变量a来说,它是完全可以更新的,可以把另一个对象的引用重新赋值给它:
>>> a="string"
>>> a[0]="a"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
>>> a="hello"
>>> a
'hello'
事实上不可变对象无论是看着无法改变的,还是直觉上感觉可以改变的(比如字符串),都是python中规定好了的。所以不必纠结于直觉,我们要做的是记住哪些数据类型是可变的,而哪些数据类型又是不可变的。下面将介绍一种新的数据类型,它跟列表类似,最大的不同是,它是不可变的。它叫元组(tuple)。
1.4.2 元组(tuple)
元组(tuple)中可以装进去其他各种数据类型,甚至也可以将其他元组(tuple)嵌套进去。元组(tuple)的元素有索引(index),可以通过索引访问到。
# 空元组
tuple1=()
# 一个元素的tuple,写法特殊一点。如果在元素后面不加逗号
# 则python解释器会当成元素的数据类型,而不认为是个元组
tuple2=(2,)
# 另一个元组,它里面有个列表作为元素
tuple3=(2,"lalala",True,45,[4,5])
# 使用内置函数tuple()创建元组,该函参数接受可迭代的对象
a=tuple()
b=tuple([1,2,3])
因为元组是不可变对象,所以它其中的元素是不能修改的。元素也不能增删。但整个元组是可以通过del语句删除的。但是当元组中的元素是可变对象时,比如元组中的某个元素是列表,那该列表能不能修改?因为该列表是可变对象,所以该列表中的元素是可以自然增删修改的,但该列表因为是不可变对象中的元素,所以无法删除,如下:
>>> d=(2, 'lalala', True, 45, [5, 5])
>>> d[4][0]=88
>>> print(d)
(2, 'lalala', True, 45, [88, 5])
>>> del d[4]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object doesn't support item deletion
>>> del d[4][0]
>>> print(d)
(2, 'lalala', True, 45, [5])
那么情况反过来呢?当可变对象中的元素是不可变对象时,比如当列表中的某元素是个元组,该元组是否能够被修改?因为该元组是不可变对象,所以该元组中的元素不能被修改,但是该元组本身是可变对象的元素,所以可以被删除,如下:
>>> e=['he!',0,(4,5,'last')]
>>> e[2][0]=5
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> del e[2][0]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object doesn't support item deletion
>>> del e[2]
>>> print(e)
['he!', 0]
1.4.3 序列(sequence)
一个数据集合里面的元素根据放入的先后顺序排成一串,这种形式的数据可以被称为序列。字符串,列表,元组都有着类似序列的结构,所以也就有类似的行为,它们都可以被索引,都可以被迭代,都能够通过索引访问到其中的元素;不仅仅是能够访问到其中的某一个元素,还能访问到其中的某几个元素,这种同时访问到好几个元素的行为,称为切片(也可以把被访问的这些元素称为数据的切片),因为这样做相当于从整个数据序列中切下来一部分,如下:
x='string'
y=[1,2,3,4,5,6]
z=(7,8,9,10,11,12)
# 以下注释都根据惯例,从0开始计数
# 打印出字符串的第3个字符
print(x[3])
# 打印出字符串的倒数第2个字符
print(x[-2])
# 打印出字符串的一部分,从第1个开始,到第3个字符,不包括第4个字符
print(x[1:4])
# 打印出列表的倒数第3个元素
print(str(y[-3]))
# 打印出列表的一部分,从第1个元素开始,到第4个元素,不包括第5个元素
print(str(y[1:5]))
# 打印出列表的一部分,从第1个元素开始,直到结束
print(str(y[1:]))
# 打印出元组的倒数第4个元素
print(str(z[-4]))
# 打印出元组的一部分,从第1个元素开始,到第4个元素,不包括第5个元素
print(str(z[1:5]))
# 打印出列表的一部分,从第1个元素开始,直到结束
print(str(z[1:]))
运行如下:
i
n
tri
4
[2, 3, 4, 5]
[2, 3, 4, 5, 6]
9
(8, 9, 10, 11)
(8, 9, 10, 11, 12)
切片中可以设置步长,就是说可以设置隔着几个元素的方式访问数据的一部分,默认步长为1,如下:
>>> a=(1,2,3,4,5,6,7,8,9,10)
>>> a[::1]
(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
>>> a[::2]
(1, 3, 5, 7, 9)
当我们把数据的切片赋值给变量时会发生什么?一般来说,数据被切片部分会被复制一份副本,然后把副本的引用赋值给变量。但是,有个特殊情况,就是当数据的被切片部分是全部数据本身时,那该数据要看是可变对象还是不可变对象了。列表(可变对象)则会复制一份副本,然后把副本的引用赋值给变量,而字符串、元组(不可变对象)则会直接将该数据本身的引用直接赋值给变量,如下:
>>> a=[1,2,3,4]
>>> b=a[:] # 省略掉开头跟结尾index则切片结果是数据本身
>>> id(a)
140046385947272
>>> id(b)
140046386409992
>>> c=(1,2,[2,3])
>>> d=c[:]
>>> id(c)
140046385743768
>>> id(d)
140046385743768
1.4.4 字典(dict)
前面介绍了序列,我们知道序列的索引隐含在数据类型里,不需要我们明确去定义,因为都是0,1,2,3,4...有顺序的排列下去,当可变对象里的元素被删除,保留下来的元素的索引会改变,因为序列里的索引永远都是顺序排列的数字,这些数字没有跟元素绑定,而只是允许我们通过索引的数字来访问该位置的元素。那如果我们想要自定义索引,用字符串,数字等来做索引,并希望这些索引能够跟特定的元素绑定在一起,我们该怎么办?更简单的说,就是我们希望索引是独特并且容易记住,有语义,我们该怎么办?python给我们提供了一种数据类型字典(dict),可以胜任这样的要求。我们把这样的索引可以看作是键(keys),它与要存储的值绑定在一起,叫做键值对。
字典里存储键值对儿,索引独特,所以是没有顺序的。顺序已经无关紧要,我们只需要记住独特的键就行了。如何创建字典,如何存储键值对,看下面的例子:
>>> a={} # 创建一个空字典
>>> type(a)
<class 'dict'>
>>> b={"id":4667,"name":"john"} # 创建一个有两对键值对的字典
>>> b["id"] # 通过键"id"来获得对应的值
4667
>>> c=dict(id=4555,name="li") # 通过内置的dict函数创建字典
>>> print(c)
{'id': 4555, 'name': 'li'}
字典是可变对象,为了通过键来查找值,就需要字典键(keys)保持唯一性,如果键用了可变对象来存储,会出现不可控因素,举个例子,假如两个键都是由列表来存储,则一旦把这两个列表修改相同,那么查找这两个键所对应的值时就会出现矛盾,所以键一定要用不可变对象来存储,包括数字,布尔值,字符串,元组(需要元组中的元素不包含可变对象)。又因为字典是可变对象,所以字典中键值对里的值是可以改变的。如下:
>>> c={("id",):46678,"name":"john_ss"}
>>> c[("id",)]
46678
>>> d=8
>>> e={d:8,"d":"8"}
>>> e[d]
8
>>> e["d"]
'8'
>>> e[d]=123
>>> print(e)
{8: 123, 'd': '8'}
在字典中,也可以用字典的get()方法通过键获取值。如果要给字典里增加键值对,可以直接用方括号(下标)的方式增加,例如dict["key_word"]="some values"。可以用字典的pop()方法来删除键值对,要注意的是,pop()方法在删除键值对的同时会返回要移除的键值对,把返回值赋给变量,变量就会得到被移除的键值对:pair=dict.pop("id")。如果我们不只想删除某一个键值对,而是想清空整个字典,则可以使用字典的clear()方法。如果看下面的例子:
>>> a={1:1,2:2,3:3}
>>> a.get(1)
1
>>> a["appended"]="ok,then!"
>>> print(a)
{1: 1, 2: 2, 3: 3, 'appended': 'ok,then!'}
>>> a.pop(2)
2
>>> print(a)
{1: 1, 3: 3, 'appended': 'ok,then!'}
>>> a.clear()
>>> print(a)
{}
复当我们尝试像迭代序列那样直接迭代字典时,交互命令行显示结果如下,明显只迭代了键值对中的键(key):
>>> a={1: 1, 2: 2, 3: 3, 'appended': 'ok,then!'}
>>> for item in a:
... print(item)
...
1
2
3
appended
这时候字典中有两个内置方法可以协助来完成迭代,分别是items()跟keys()。items()返回字典中无序的键值对,keys()返回字典中无序的键(keys)。如下:
>>> a={1: 1, 2: 2, 3: 3, 'appended': 'ok,then!'}
>>> for item in a.items():
... print(item)
...
(1, 1) # 可以看到把键值对装进了元组
(2, 2)
(3, 3)
('appended', 'ok,then!')
>>> for key in a.keys():
... print(key)
1
2
3
appended
1.4.5 集合(set),frozenset
前面我们介绍了字典,跟字典类似,在python里还有一种无序的数据类型:集合(set)。基本上,这儿的集合跟数学上的集合的概念是一样的。其中的元素是无序的,并且每个元素都是唯一不可重复的。创建集合跟创建字典的符号一样,都是花括号“{}”,所以当创建空集合时,会跟创建空字典的符号有冲突,所以python里“{}”表示创建空字典,而创建空集合只能用内置函数set()来创建,如下:
>>> a={1,4,7,"string",("lalala",2,3,4)} # 创建集合
>>> print(a)
{1, 4, 7, 'string', ('lalala', 2, 3, 4)}
>>> b={} # 空字典
>>> type(b)
<class 'dict'>
>>> c=set() # 空集合
>>> type(c)
<class 'set'>
集合是可变对象,但是它的元素则要求一定是不可变对象,根据集合的定义,每个元素都是唯一不可重复,那么一旦元素是可变对象,则有了可重复的可能,比如元素中有两个列表的话,通过一些操作有可能会让这两个列表成为一样的。如下:
>>> d={1,2,[1,2]}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
既然集合是可变对象,我们就可以通过add()方法增加元素,通过remove()、discard()方法、pop()方法删除元素,前提是所有元素都要是不同的,通过pop()方法删除元素时,不带参数,并且集合无序,所以无法预知哪个元素被丢掉,但pop()方法会返回被丢的元素:
>>> a={1,4,7,("string",55),"hello"}
>>> a.add("hello,world!") # add方法新增元素
>>> print(a)
{1, 4, 7, 'hello,world!', ('string', 55), 'hello'}
>>> a.remove(7) # remove方法删除元素
>>> print(a)
{1, 4, 'hello,world!', ('string', 55), 'hello'}
>>> a.discard(1) # discard方法删除元素
>>> print(a)
{4, 'hello,world!', ('string', 55), 'hello'}
>>> a.pop() # 通过pop方法删除随机某个元素并返回被删除的元素,可以使用变量来存储
4
>>> print(a)
{'hello,world!', ('string', 55), 'hello'}
可以使用update方法来增加多个元素,使用clear()方法来清空整个集合,接上面的例子:
>>> a.update([1,2,3,4]) # 用列表来更新集合
>>> a.update((5,6,7)) # 用元组来更新集合
>>> print(a)
{1, 2, 3, 4, 5, 6, 7, 'hello,world!', ('string', 55), 'hello'}
>>> a.clear()
>>> print(a)
set() # 代表空集合
集合可以实现数学上的并集,交集,差集,对称差,有两种方式:操作符跟方法。并集是两个集合中所有的元素组成的新集合,交集是两个集合中都存在的元素组成的新集合。差集是两个集合中在某个集合中存在,并且在另一个集合中不存在的元素组成的新集合。对称差集是两个集合中所有元素,除去在交集中的元素,由这样的元素组成的新集合。下面这个表显示python的操作方法:
| 操作名称 | 操作符 | 集合(比如A,B)内置方法 |
|---|---|---|
| 并 | | |
A.union(B) |
| 交 | & |
A.intersection(B) |
| 差 | - |
A.difference(B) |
| 对称差 | ^ |
A.symmetric_difference(B) |
通过例子来看看:
>>> A={1,2,4,6,7}
>>> B={1,3,4,5,8}
>>> print(A | B)
{1, 2, 3, 4, 5, 6, 7, 8}
>>> print(A.union(B))
{1, 2, 3, 4, 5, 6, 7, 8}
>>> print(A & B)
{1, 4}
>>> print(A.intersection(B))
{1, 4}
>>> print(A - B)
{2, 6, 7}
>>> print(A.difference(B))
{2, 6, 7}
>>> print(B - A)
{8, 3, 5}
>>> print(B.difference(A))
{8, 3, 5}
>>> print(A ^ B)
{2, 3, 5, 6, 7, 8}
>>> print(A.symmetric_difference(B))
{2, 3, 5, 6, 7, 8}
从上面的例子可以看出来,两个集合的并集,交集,对称差集都是可以互换的,而差集不是,差集需要区分A-B跟B-A。在python中,还可以创建类似于tuple这样的不可变对象的set,那就是frozenset,frozen在英文中是冻结了的意思,顾名思义,frozenset就是冻结的集合。frozenset不能增加或者更新元素,删除或者清除元素,类似于只读文件。并集,交集,差集,对称差的操作对于frozenset同样适用。如下:
>>> a=frozenset([1,2,3]) # 创建一个frozenset
>>> print(a)
frozenset({1, 2, 3})
>>> a.add(4)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'add'
>>> a.clear()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'frozenset' object has no attribute 'clear'
>>> b=frozenset((4,5,3))
>>> a.union(b)
frozenset({1, 2, 3, 4, 5})
1.4.6 关于None
>>> type(None)
<class 'NoneType'>
None属于NoneType这个数据类型(对象),是它唯一的值。并且,NoneType对象并不像别的数据类型一样,可以有很多实例,而是从始至终都只能有一个实例。
>>> None==False
False
>>> None==1
False
>>> None==""
False
>>> None==0
False
>>> None=={}
False
>>> None==None
True
从上面的例子(做逻辑判断)可以看出来,None不等于其他任何值,None只等于None。None一般用来代表数据的缺失,看下面的例子:
def addTwo(a,b):
if (type(a)==int or type(a)==float) and ((type(b)==int or type(b)==float)):
return a+b
else:
return None
b=addTwo("ss",4)
print(b)
# OUTPUT应该为None,None代表函数没法合理的处理参数,只能返回None。
当我们拿到某个数据,我们想要判断它不是None的时候该如何做呢,这时候应该用is,因为None是数据类型,也是对象,所以我们一般会想要这样做:if an_object is not None:。此处not的位置跟成员检测if an_object not in an_object:的位置不同,需要特别注意。如下:
a=1
if a is not None:
print("a is not None")
else:
print("a is None")
# OUTPUT应该为"a is not None"。
有些时候我们会在别人的代码中看到if an_object:这样的写法,这种写法跟上面的判断某数据(对象)是不是None的写法没有什么联系,这种代码暗示了数据(对象)本身在做逻辑判断时会另外呈现出或真或假的布尔值,事实上也的确如此,在各种数据类型中,会有某些特殊的值在逻辑判断的时候布尔值表现为False,其余值表现为True。在python中,规定了一套规则,当我们拿某个数据本身来做逻辑判断的时候,解释器如何解确定其布尔值:
布尔型,False表示False,其他为True
整数和浮点数,0表示False,其他为True
字符串和类字符串类型(包括bytes和unicode),空字符串表示False,其他为True
序列类型(包括tuple,list,dict,set等),空表示False,非空表示True
None永远表示False
举个例子,当我们在理论上来说从某函数(方法)返回了一个列表list1,我们用if list1:来判断的时候,则会出现三种情况:list1是None,list1是空列表,list1是非空列表,这时候list1在第一和第二种情况下表现出的布尔值为False,在第三种情况下表现出的布尔值为True。如下:
list1=[]
while True:
if list1:
print("true")
else:
if list1 != None:
print("false,empty list")
list1=None
else:
print("false,None")
list1=[]
# OUTPUT应该永远在None跟空列表之间徘徊。交替打印“false,empty list”和“false,None”
1.4.7 简化内置的help函数
在python中,有个help()内置函数可以获取关于对象的说明文档。但说明文档中有关于该对象实现的细节,当我们只是想知道各数据类型的常用内置方法及其使用时,就会变得很不方便。写了一个很短的程序,运行该程序可以将help函数的输出简化(删去实现对象的相关细节)并存入当前目录新建的一个文本文件中,并且该程序还有将方法的解释翻译成中文的可选功能。下面是该程序内容:
# -*- coding: utf-8 -*-
import os, sys, re
from translate import Translator
def command_line_arguments(usge,len_of_arguments):
if len(sys.argv)!=len_of_arguments+1:
print(usge)
return sys.argv
def stdout_to_file(dir, func, func_arguments):
# 把函数的标准输出存入文件中
default_stdout = sys.stdout
with open(dir, "w") as w:
sys.stdout=w
func(func_arguments)
sys.stdout=default_stdout
def simpler_help(object):
stdout_to_file("simpler_help_{}.txt".format(object), help, object)
# 把文件中的内容分行存入内存
with open("simpler_help_{}.txt".format(object),"r") as r:
lines=r.readlines()
# 将内存中的内容修改后写入同名文件,覆盖原有文件
# mark1,为了将带有“__”的特殊函数不要写入,并将其下面的解释一并略过
mark1=False
# mark2,为了将“---”下面的内容略过
mark2=False
with open("simpler_help_{}.txt".format(object),"w") as w:
for line in lines:
#将带有“__”的特殊方法不要写入,并将其下面的解释一并略过
if "__" in line:
mark1=True
continue
elif mark1==True:
result=re.search("[A-Za-z]+", line)
if result==None:
mark1=False
continue
# 将“---”下面的内容略过
elif "---" in line:
mark2=True
continue
elif mark2==True:
pass
# 将行中的self跟“/”替换成空
else:
if ("self," in line) or ("/" in line):
if ("self," in line) and ("/" in line):
w.write(line.replace("self,","").replace("/","").replace(", )"," )").replace(" , "," "))
elif ("self," in line) and ("/" not in line):
w.write(line.replace("self,",""))
elif ("self," not in line) and ("/" in line):
w.write(line.replace("/","").replace(", )"," )").replace(" , "," "))
else:
w.write(line)
def translation_of_help(object):
translator= Translator(to_lang="zh")
with open("simpler_help_{}_zh.txt".format(object),"r") as r:
lines=r.readlines()
with open("simpler_help_{}_zh.txt".format(object),"w") as w:
line_process=""
count_line=0
for line in lines:
if ("(" in line) and (")"in line) and ("." not in line):
w.write(line)
else:
if count_line<=1:
w.write(translator.translate(line)+"\n")
else:
line_process=line.replace("|","")
w.write(" | "+translator.translate(line_process)+"\n")
count_line=count_line+1
len_of_arguments=1
arguments=command_line_arguments('''You need provide a name of object,for example:
python3 simpler_help.py list''',len_of_arguments)
if len(arguments)==len_of_arguments+1:
simpler_help(arguments[1])
translation_of_help(arguments[1])
将上面内容复制粘贴,并命名为simpler_help.py。举个例子,如果想知道列表中的内置方法,则在命令行中通过类似这样的python3 simpler_help.py list命令来运行,特别注意需要在文件名空一格后写上需要查询的数据类型名称。下面是程序创建的简化版的列表的help函数输出,保存在当前目录的simpler_help_list.txt中。通过程序创建的文件,可以大概了解各数据类型都有哪些内置方法,之后可以从网上通过关键词搜索出更为详细的介绍跟用例。
二、python内存使用
2.1 Python整型对象
在python中一切皆为对象,就不是象C语言中int占用4个字节这么简单了,Python提供了sys.getsizeof获取对象所占用的字节大小.它支持任何类型的对象:
import sys
sys.getsizeof ('a') # 50
sys.getsizeof(1) # 28
a = 1
a.__sizeof__() # 28
可以看到除了用sys.getsizeof,还可以用对象的__sizeof__()方法.可以看到占用的空间远超C语言的实现:这是因为python对象的结构体更复杂,成员更多.
- 整数1的28个字节怎么分配的
整数1占了28个字节,第一感觉肯定是好大啊!那这些内存空间是怎么分配的呢?
python3中int类型是长整型,所以int是struct_longobject的实例(Include/longintrepr.h,具体代码片段参考:https://github.com/python/cpython/blob/3.8/Include/longintrepr.h#L85-L88):
struct _longobject {
PyObject_VAR_HEAD
digit ob_digit[1];
};
ob_digit是一个数组指针,digit是int的别名。简单说一下python整型的存储机制,ob_digit中的每个元素最大存储15-30位的二进制数(不同位数操作系统位数不同:32位系统存15位,64位系统是30位).假如在64位系统中,一个整数小于1073741824(2的30次方),它可以独立的放在ob_digit的低位(索引为0),如果再大就把放不下的那部分放在索引为1的元素上,以此类推.做加减操作就是从低位起,在相对应的位作加减,并将多余的进位或不足的补位.而PyObject_HEAD是声明表示没有变化长度的对象的新类型时使用的宏(Include/object.h):
#define PyObject_VAR_HEAD PyVarObject ob_base;
结构体PyVarObject是这样的(Include/object.h):
typedef struct {
PyObject ob_base;
Py_ssize_t ob_size;
} PyVarObject;
其中ob_size包含了整数正负符号信息和ob_digit对象元素个数。结构体PyObject是这样的(Include/object.h):
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
其中_PyObject_HEAD_EXTRA以下划线开头的,这类变量一般都是内部使用,根据Include/object.h中的定义可以知道只有在DEBUG模式下才有用,一般为空.
按阅读源码的顺序,逆向的看看28个字节内存在64位系统编译的Python中是这样分配的:
- _object.Py_ssize_t:8个字节用于引用计数器
- _object._typeobject:8个字节用于指向类型对象&PyLong_Type(类型为PyTypeObject*的指针)
- PyVarObject.Py_ssize_t:8个字节用于表示对象的可变长度部分中的字节数
- _longobject.digit:整数中每30位数字4个字节,上面的例子中整数1在这个范围,所谓只占4个字节
首先看Py_ssize_t(configure文件中):
#ifdef HAVE_SSIZE_T
typedef ssize_t Py_ssize_t;
#elif SIZEOF_VOID_P == SIZEOF_LONG
typedef long Py_ssize_t;
#else
typedef int Py_ssize_t;
#endif
对于我的Mac电脑来说,应该看Include/pymacconfig.h:
ifdef __LP64__
# define SIZEOF_LONG 8
# define SIZEOF_VOID_P 8
在64位系统中,是Clong类型的,64bits也就是8字节了。另外是_object._typeobject中引用的ob_type这个指针变量所占内存大小取决于ob_type的类型,可以看到PyLong_Type有39位(Objects/longobject.c):
PyTypeObject PyLong_Type = {PyVarObject_HEAD_INIT (&PyType_Type, 0)
"int", /* tp_name */
offsetof (PyLongObject, ob_digit), /* tp_basicsize */
sizeof (digit),
....
PyLong_Type是int类型,但是由于位数超过4字节(32位),基于C语言数据结构补齐原则,需要补齐int的整数倍数位数,也就是64,就是8字节。找了半天没看到CPython的具体说明,但找到个辅证。在Modules/_pickle.c里面序列化时&PyLong_Type类型用的是Long类型保存的:
...
else if (type == &PyLong_Type) {return save_long (self, obj);
}
...
所以能确定这部分也是8字节。那么整数1占用的内存就是:8+8+8+4=28。再看看位宽超过30位的数字:
sys.getsizeof ((1 << 30) - 1) # 28
sys.getsizeof ((1 << 30)) # 32
sys.getsizeof ((1 << 60)) # 36
sys.getsizeof ((1 << 90)) # 40
这样也能得出每多30位宽,多占用4字节。前面提到_longobject的结构体中digit指向ob_digit[1]而不是ob_digit[0],也就是指向了高位,但事实上我们常用的都要小于30位,用不到ob_digit[1],也就是0)。不完全理解,那就要学习CPython的源码。这次我们换个思路想问题,先看看__sizeof__方法的返回值是怎么来的(Objects/clinic/longobject.c.h):
static Py_ssize_t
int___sizeof___impl (PyObject *self);
static PyObject *
int___sizeof__(PyObject *self, PyObject *Py_UNUSED (ignored))
{
PyObject *return_value = NULL;
Py_ssize_t _return_value;
_return_value = int___sizeof___impl (self);
if ((_return_value == -1) && PyErr_Occurred ()) {goto exit;}
return_value = PyLong_FromSsize_t (_return_value);
exit:
return return_value;
}
也就是通过int___sizeof___impl(self)获得对象占用字节数。接着找int___sizeof___impl的实现(Objects/longobject.c):
static Py_ssize_t
int___sizeof___impl (PyObject *self)
{
Py_ssize_t res;
res = offsetof (PyLongObject, ob_digit) + Py_ABS (Py_SIZE (self))*sizeof (digit);
return res;
}
上面的实现中,offsetof是一个C语言的宏,找到结构成员相对于结构开头的字节偏移量.之前说int是struct_longobject的实例,在这里也得到了印证:
typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
而Py_ABS看名字可以猜出来:返回数字的绝对值.Py_SIZE宏访问self的ob_size,sizeof是C语言中判断数据类型的函数,digit在CPython中这么定义(Include/longintrepr.h,延伸阅读链接13):python
#if PYLONG_BITS_IN_DIGIT == 30
typedef uint32_t digit;
...
在64位系统中,C中sizeof(uint32_t)的结果是4。好,到这里就非常清晰了。整数占用28字节包含2部分:
offsetof (PyLongObject, ob_digit)
这个偏移量就是前面我们看结构体的_object.Py_ssize_t + _object._typeobject + PyVarObject.Py_ssize_t = 24。
Py_ABS (Py_SIZE (self))*sizeof (digit)
其中ob_size为1,sizeof(digit)为4,所以整体的结果是4。
2.2 python格式化字符串
2.2.1 %格式化字符串
格式化字符串时,python使用一个字符串作为模板。模板中有格式符,这些格式符为真实值预留位置,并说明真实数值应该呈现的格式。python用一个tuple将多个值传递给模板,每个值对应一个格式符。比如:print("I'm %s. I'm %d year old" %('Vamei', 99)),其中"I'm %s. I'm %d year old" 为模板。%s为第一个格式符,表示一个字符串。%d为第二个格式符,表示一个整数。('Vamei', 99)的两个元素'Vamei'和99为替换%s和%d的真实值。
在模板和tuple之间,有一个%号分隔,它代表了格式化操作。
- 格式符
格式符为真实值预留位置,并控制显示的格式。格式符可以包含有一个类型码,用以控制显示的类型,如下:
| 类型 | 说明 |
|---|---|
| %s | 字符串(采用str()的显示) |
| %r | 字符串(采用repr()的显示) |
| %c | 单个字符 |
| %b | 二进制整数 |
| %d | 十进制整数 |
| %i | 十进制整数 |
| %o | 八进制整数 |
| %x | 十六进制整数 |
| %e | 指数(基底写为e) |
| %E | 指数(基底写为E) |
| %f | 浮点数 |
| %F | 浮点数,与上相同 |
| %g | 指数(e)或浮点数(根据显示长度) |
| %G | 指数(E)或浮点数(根据显示长度) |
| %% | 字符"%" |
- 精确控制
可以用如下的方式,对格式进行进一步的控制:%[(name)][flags][width].[precision]typecode,参数如下:
- (name)为命名
- flags可以有+,-,' '或0。+表示右对齐;-表示左对齐;' '为一个空格,表示在正数的左侧填充一个空格,从而与负数对齐;0表示使用0填充。
- width表示显示宽度
- precision表示小数点后精度
2.2.2 format使用
简单使用: print("{} {}.".format("Hello", "world"))
- format调用
- 通过位置
>>> "{0} {1}".format("hello", "world") # 设置指定位置
>>> >>> "{1} {0} {1}".format("hello", "world") # 设置指定位置
- 通过关键字参数
>> print("网站名({name})的地址:{url}".format(name="百度", url="www.baidu.com"))
>>> # 通过字典设置参数
>>> site = {"name": "百度", "url": "www.baidu.com"}
>>> print("网站名({name})的地址:{url}".format(**site))
- 通过下标
>>> # 通过列表索引设置参数
>>> my_list = ['百度', 'www.baidu.com']
>>> print("网站名({0[0]})的地址:{0[1]}".format(my_list)) # "0"是必须的
- 通过对象属性
>>> # 通过类
>>> class AssignValue(object):
>>> def __init__(self, value):
>>> self.value = value
>>> my_value = AssignValue(6)
>>> print('value 为: {0.value}'.format(my_value)) # "0"是可选的
- 格式控制字符
format()方法中<模板字符串>的槽除了包括参数序号,还可以包括格式控制信息。此时槽的内部样式如下:{<参数序号>:<格式控制标记>},其中,<格式控制标记>用来控制参数显示时的格式,包括:<填充><对齐><宽度>,<.精度><类型>6个字段,这些字段都是可选的,可以组合使用,逐一介绍如下
<填充> : 用于填充的单个字符,填充到宽度,默认为空格。
代码示例:"{0:*^30}".format(s)
<对齐> : 参数在<宽度>内输出时的对齐方式:
<,左对齐;>,右对齐;^,居中对齐。代码示例: "{0:*^30}".format(s)
<宽度> : 指当前槽的设定输出字符宽度:
如果该槽对应的format()参数长度比<宽度>设定值大,则使用参数实际长度;
如果该值的实际位数小于指定宽度,则位数将被默认以空格字符补充。
代码示例: "{0:*^30}".format(s)
, : 用于显示数字的千位分隔符。
代码示例: "{0:-^20,}".format(1234567890)
<.精度> : 由小数点(.)开头,表示两个含义:
对于浮点数,精度表示小数部分输出的有效位数;
对于字符串,精度表示输出的最大长度;
代码示例:"{0:.2f}".format(12345.67890)
<类型> : 表示输出整数和浮点数类型的格式规则。
对于整数类型,输出格式包括6 种:
b,输出整数的二进制方式;
c,输出整数对应的Unicode字符;
d,输出整数的十进制方式;
o,输出整数的八进制方式;
x,输出整数的小写十六进制方式;
X,输出整数的大写十六进制方式。
对于浮点数类型,输出格式包括4种:
e,输出浮点数对应的小写字母e的指数形式;
E,输出浮点数对应的大写字母E的指数形式;
f,输出浮点数的标准浮点形式;
%,输出浮点数的百分形式。
代码示例:"{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425)
2.2.3 f-string概览
- 简介
f-string,亦称为格式化字符串常量(formatted string literals),是Python3.6新引入的一种字符串格式化方法,该方法源于PEP 498 – Literal String Interpolation,主要目的是使格式化字符串的操作更加简便。f-string在形式上是以f或F 修饰符引领的字符串(f'xxx'或F'xxx'),以大括号{}标明被替换的字段;f-string在本质上并不是字符串常量,而是一个在运行时运算求值的表达式.
f-string 在功能方面不逊于传统的%-formatting语句和str.format()函数,同时性能又优于二者,且使用起来也更加简洁明了,因此对于Python3.6及以后的版本,推荐使用f-string进行字符串格式化。
- 简单使用
f-string用大括号{}表示被替换字段,其中直接填入替换内容:
>>> name = 'Eric'
>>> f'Hello, my name is {name}'
# 'Hello, my name is Eric'
>>> number = 7
>>> f'My lucky number is {number}'
# 'My lucky number is 7'
>>> price = 19.99
>>> f'The price of this book is {price}'
# 'The price of this book is 19.99'
- 表达式求值与函数调用
f-string的大括号{}可以填入表达式或调用函数,Python会求出其结果并填入返回的字符串内:
>>> f'A total number of {24 * 8 + 4}'
# 'A total number of 196'
>>> f'Complex number {(2 + 2j) / (2 - 3j)}'
# 'Complex number (-0.15384615384615388+0.7692307692307692j)'
>>> name = 'ERIC'
>>> f'My name is {name.lower()}'
# 'My name is eric'
>>> import math
>>> f'The answer is {math.log(math.pi)}'
# 'The answer is 1.1447298858494002'
- 引号、大括号与反斜杠
f-string大括号内所用的引号不能和大括号外的引号定界符冲突,可根据情况灵活切换'和":
>>> f'I am {'Eric'}'
File "<stdin>", line 1
f'I am {'Eric'}'
^
SyntaxError: invalid syntax
若'和"不足以满足要求,还可以使用'''和""":
>>> f"""He said {"I'm Eric"}"""
# "He said I'm Eric"
>>> f'''He said {"I'm Eric"}'''
# "He said I'm Eric"
大括号外的引号还可以使用\转义,但大括号内不能使用\转义:
>>> f'''He\'ll say {"I'm Eric"}'''
# "He'll say I'm Eric"
f-string大括号外如果需要显示大括号,则应输入连续两个大括号{{和}}:
>>> f'5 {"{stars}"}'
# '5 {stars}'
>>> f'{{5}} {"stars"}'
# '{5} stars'
上面提到,f-string大括号内不能使用\转义,事实上不仅如此,f-string大括号内根本就不允许出现\。如果确实需要\,则应首先将包含\的内容用一个变量表示,再在f-string大括号内填入变量名:
>>> f"newline: {ord('\n')}"
File "<stdin>", line 1
SyntaxError: f-string expression part cannot include a backslash
>>> newline = ord('\n')
>>> f'newline: {newline}'
# 'newline: 10'
- 多行
f-string
f-string还可用于多行字符串:
>>> name, age = 'Eric', 27
>>> f"Hello!" \
... f"I'm {name}." \
... f"I'm {age}."
# "Hello!I'm Eric.I'm 27."
- 自定义格式:对齐、宽度、符号、补零、精度、进制等
f-string采用{content:format}设置字符串格式,其中content是替换并填入字符串的内容,可以是变量、表达式或函数等,format是格式描述符。采用默认格式时不必指定{:format}.
# 对齐相关格式描述符
< : 左对齐(字符串默认对齐方式)
> : 右对齐(数值默认对齐方式)
^ : 居中
# 数字符号相关格式描述符
+ : 负数前加负号(-),正数前加正号(+)
- : 负数前加负号(-),正数前不加任何符号(默认)
(空格) : 负数前加负号(-),正数前加一个空格
* 注:仅适用于数值类型
# 数字显示方式相关格式描述符
# : 切换数字显示方式
* 注1:仅适用于数值类型。
* 注2:#对不同数值类型的作用效果不同,详见下表:
数值类型 | 不加#(默认) | 加# | 区别
二进制整数 | '1111011' | '0b1111011' | 开头是否显示 0b
八进制整数 | '173' | '0o173' | 开头是否显示 0o
十进制整数 | '123' | '123' | 无区别
十六进制整数(小写字母) | '7b' | '0x7b' | 开头是否显示 0x
十六进制整数(大写字母) | '7B' | '0X7B' | 开头是否显示 0X
# 宽度与精度相关格式描述符
width : 整数width指定宽度
0width : 整数width指定宽度,开头的0指定高位用0补足宽度
width.precision : 整数width指定宽度,整数precision指定显示精度
* 注1:0width 不可用于复数类型和非数值类型,width.precision不可用于整数类型。
* 注2:width.precision用于不同格式类型的浮点数、复数时的含义也不同:
用于f、F、e、E和%时precision指定的是小数点后的位数,
用于g和G时precision指定的是有效数字位数(小数点前位数+小数点后位数)。
* 注3:width.precision除浮点数、复数外还可用于字符串,
此时precision含义是只使用字符串中前precision位字符
>>> a = 123.456
>>> f'a is {a:8.2f}' # 'a is 123.46'
>>> f'a is {a:08.2f}' # 'a is 00123.46'
>>> f'a is {a:8.2e}' # 'a is 1.23e+02'
>>> f'a is {a:8.2%}' # 'a is 12345.60%'
>>> f'a is {a:8.2g}' # 'a is 1.2e+02'
>>> s = 'hello'
>>> f's is {s:8s}' # 's is hello '
>>> f's is {s:8.3s}' # 's is hel '
# 千位分隔符相关格式描述符
, : 使用,作为千位分隔符
_ : 使用_作为千位分隔符
* 注1:若不指定,或_,则f-string不使用任何千位分隔符,此为默认设置。
* 注2:,仅适用于浮点数、复数与十进制整数:
对于浮点数和复数,只分隔小数点前的数位。
* 注3:_适用于浮点数、复数与二、八、十、十六进制整数:
对于浮点数和复数,_只分隔小数点前的数位;
对于二、八、十六进制整数,固定从低位到高位每隔四位插入一个_(十进制整数是每隔三位插入一个_)。
>>> a = 1234567890.098765
>>> f'a is {a:f}' # 'a is 1234567890.098765'
>>> f'a is {a:,f}' # 'a is 1,234,567,890.098765'
>>> f'a is {a:_f}' # 'a is 1_234_567_890.098765'
>>> b = 1234567890
>>> f'b is {b:_b}' # 'b is 100_1001_1001_0110_0000_0010_1101_0010'
>>> f'b is {b:_o}' # 'b is 111_4540_1322'
>>> f'b is {b:_d}' # 'b is 1_234_567_890'
>>> f'b is {b:_x}' # 'b is 4996_02d2'
- 格式类型相关格式描述符
# 基本格式类型
格式描述符 | 含义与作用 | 适用变量类型
s | 普通字符串格式 | 字符串
b | 二进制整数格式 | 整数
c | 字符格式,按unicode编码将整数转换为对应字符 | 整数
d | 十进制整数格式 | 整数
o | 八进制整数格式 | 整数
x | 十六进制整数格式(小写字母) | 整数
X | 十六进制整数格式(大写字母) | 整数
e | 科学计数格式,以 e 表示×10^ | 浮点数、复数、整数(自动转换为浮点数)
E | 与e等价,但以E表示×10^ | 浮点数、复数、整数(自动转换为浮点数)
f | 定点数格式,默认精度(precision)是6 | 浮点数、复数、整数(自动转换为浮点数)
F | 与f等价,但将 nan 和 inf 换成 NAN 和 INF | 浮点数、复数、整数(自动转换为浮点数)
g | 通用格式,小数用 f,大数用 e | 浮点数、复数、整数(自动转换为浮点数)
G | 与G等价,但小数用 F,大数用E | 浮点数、复数、整数(自动转换为浮点数)
% | 百分比格式,数字自动乘上100后按f格式排版,并加 % 后缀 | 浮点数、整数(自动转换为浮点数)
# 常用的特殊格式类型:标准库datetime
参考shell命令date
>>> a = 1234
>>> f'a is {a:^#10X}' # 'a is 0X4D2 ',居中,宽度10位,十六进制整数(大写字母),显示0X前缀
>>> b = 1234.5678
>>> f'b is {b:<+10.2f}'
# 'b is +1234.57 ',左对齐,宽度10位,显示正号(+),定点数格式,2位小数
>>> c = 12345678
>>> f'c is {c:015,d}'
# 'c is 000,012,345,678',
# 高位补零,宽度15位,十进制整数,使用,作为千分分割位
>>> d = 0.5 + 2.5j
>>> f'd is {d:30.3e}'
# 'd is 5.000e-01+2.500e+00j', 宽度30位,科学计数法,3位小数
>>> import datetime
>>> e = datetime.datetime.today()
>>> f'the time is {e:%Y-%m-%d (%a) %H:%M:%S}'
# 'the time is 2018-07-14 (Sat) 20:46:02', datetime时间格式
lambda表达式
f-string大括号内也可填入lambda表达式,但lambda表达式会被f-string误认为是表达式与格式描述符之间的分隔符,为避免歧义,需要将lambda表达式置于括号()内:
>>> f'result is {(lambda x: x ** 2 + 1) (2)}'
# 'result is 5'
>>> f'result is {(lambda x: x ** 2 + 1) (2):<+7.2f}'
# 'result is +5.00 '
2.3 python 对象
- 对象概念
究竟何谓对象?不同的编程语言以不同的方式定义“对象”。某些语言中,它意味着所有对象必须有属性和方法;另一些语言中,它意味着所有的对象都可以子类化。
在python中,定义是松散的,某些对象既没有属性也没有方法,而且不是所有的对象都可以子类化。但是python的万物皆对象从感性上可以解释为:python中的一切都可以赋值给变量或者作为参数传递给函数。
python 的所有对象都有三个特性:
- 身份
每个对象都有一个唯一的身份标识自己,任何对象的身份都可以使用内建函数id()来得到,可以简单的认为这个值是该对象的内存地址。
>>> a = 1
>>> id(a) # 26188904, 身份由这样一串类似的数字表示
- 类型
对象的类型决定了对象可以保存什么类型的值,有哪些属性和方法,可以进行哪些操作,遵循怎样的规则。可以使用内建函数type()来查看对象的类型。
>>> type(a) # <type 'int'>
>>> type(type) # <type 'type'>,万物皆对象,type 也是一种特殊的对象type
- 值
对象所表示的数据
>>> a # 1
"身份"、"类型"和"值"在所有对象创建时被赋值。如果对象支持更新操作,则它的值是可变的,否则为只读(数字、字符串、元组等均不可变)。只要对象还存在,这三个特性就一直存在。
对象的属性:大部分python对象有属性、值或方法,使用句点(.)标记法来访问属性。最常见的属性是函数和方法,一些python对象也有数据属性,如:类、模块、文件等。
- 对象创建和引用
>>> a = 3
简单来看,上边的代码执行了以下操作:
创建了一个对象来代表数字3
如果变量a不存在,创建一个新的变量a
将变量a和数字3进行连接,即a成为对象3的一个引用,从内部来看,变量是到对象的内存空间的一个指针,尤其注意:变量总是连接到对象,而不会连接到其他变量。
从概念上可以这样理解,对象是堆上分配的一个内存空间,用来表示对象所代表的值;变量是一个系统创建的表中的元素,拥有指向对象的引用;引用是从变量到对象的指针。
从技术上来说,每一个对象有两个标准的头部信息,一个类型标识符来标识类型,还有一个引用的计数器,用于决定是否需要对对象进行回收。这里还涉及到对象的一种优化方法,python缓存了某些不变的对象对其进行复用,而不是每次创建新的对象。
>>> a = 1
>>> b = 1
>>> id(a) # 26188904
>>> id(b) # 26188904, a和b都指向了同一对象
- 共享引用
在python中变量都是指向某一对象的引用,当多个变量都引用了相同的对象,成为共享引用。
>>> a = 1
>>> b = a
>>> a = 2
>>> b # 1, 由于变量仅是对对象的一个引用,因此改变a并不会导致b的变化
但对于像列表这种可变对象来说则不同
>>> a = [1, 2, 3]
>>> b = a
>>> a[0] = 0
>>> a # [0, 2, 3],这里并没有改变a的引用,而是改变了被引用对象的某个元素
>>> b # [0, 2, 3]
# 由于被引用对象发生了变化,因此b对应的值也发生了改变.
# 由于列表的这种可变性,在代码执行某些操作时可能出现一些意外,
# 因此需要对其进行拷贝来保持原来的列表
>>> a = [1, 2, 3]
>>> b = a[:]
>>> id(a) # 140200275166560
>>> id(b) # 140200275238712
# 由于b引用的是a引用对象的一个拷贝,两个变量指向的内存空间不同
>>> a[0] = 0
>>> b # [1, 2, 3], 改变a中的元素并不会引起b的变化
# 对于字典和集合等没有分片概念的类型来说
# 可以使用copy模块中的copy()方法进行拷贝
>>> import copy
>>> b = copy.copy(a)
- 深度拷贝与浅拷贝
- 赋值(assignment)
在《Python FAQ1》一文中,对赋值已经讲的很清楚了,关键要理解变量与对象的关系。
>>> a = [1, 2, 3]
>>> b = a
>>> print(id(a), id(b), sep='\n')
139701469405552
139701469405552
在python中,用一个变量给另一个变量赋值,其实就是给当前内存中的对象增加一个“标签”而已。如上例,通过使用内置函数id(),可以看出a和b指向内存中同一个对象。a is b会返回True。
- 浅拷贝(shallow copy)
注意:浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含了其它对象的对象,如列表,类实例。而对于数字、字符串以及其它“原子”类型,没有拷贝一说,产生的都是原对象的引用。
所谓“浅拷贝”,是指创建一个新的对象,其内容是原对象中元素的引用。(拷贝组合对象,不拷贝子对象)
常见的浅拷贝有:切片操作、工厂函数、对象的copy()方法、copy模块中的copy函数。
>>> a = [1, 2, 3]
>>> b = list(a)
>>> print(id(a), id(b)) # a和b身份不同
140601785066200 140601784764968
>>> for x, y in zip(a, b): # 但它们包含的子对象身份相同
... print(id(x), id(y))
...
140601911441984 140601911441984
140601911442016 140601911442016
140601911442048 140601911442048
从上面可以明显的看出来,a浅拷贝得到b,a和b指向内存中不同的list对象,但它们的元素却指向相同的int对象。这就是浅拷贝!
- 深拷贝(deep copy)
所谓“深拷贝”,是指创建一个新的对象,然后递归的拷贝原对象所包含的子对象。深拷贝出来的对象与原对象没有任何关联。深拷贝只有一种方式:copy模块中的deepcopy函数。
>>> import copy
>>> a = [1, 2, 3]
>>> b = copy.deepcopy(a)
>>> print(id(a), id(b))
140601785065840 140601785066200
>>> for x, y in zip(a, b):
... print(id(x), id(y))
...
140601911441984 140601911441984
140601911442016 140601911442016
140601911442048 140601911442048
对于不可变对象,当需要一个新的对象时,python可能会返回已经存在的某个类型和值都一致的对象的引用。而且这种机制并不会影响a和b的相互独立性,因为当两个元素指向同一个不可变对象时,对其中一个赋值不会影响另外一个。
可以用一个包含可变对象的列表来确切地展示"浅拷贝"与"深拷贝"的区别:
>>> import copy
>>> a = [[1, 2],[5, 6], [8, 9]]
>>> b = copy.copy(a) # 浅拷贝得到b
>>> c = copy.deepcopy(a) # 深拷贝得到c
>>> print(id(a), id(b)) # a 和 b 不同
139832578518984 139832578335520
>>> for x, y in zip(a, b): # a 和 b 的子对象相同
... print(id(x), id(y))
...
139832578622816 139832578622816
139832578622672 139832578622672
139832578623104 139832578623104
>>> print(id(a), id(c)) # a和c不同
139832578518984 139832578622456
>>> for x, y in zip(a, c): # a和c的子对象也不同
... print(id(x), id(y))
...
139832578622816 139832578621520
139832578622672 139832578518912
139832578623104 139832578623392
总结:
- 赋值:简单地拷贝对象的引用,两个对象的id相同。
- 浅拷贝:创建一个新的组合对象,这个新对象与原对象共享内存中的子对象。
- 深拷贝:创建一个新的组合对象,同时递归地拷贝所有子对象,新的组合对象与原对象没有任何关联。虽然实际上会共享不可变的子对象,但不影响它们的相互独立性。 浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含了其它对象的对象,如列表,类实例。而对于数字、字符串以及其它“原子”类型,没有拷贝一说,产生的都是原对象的引用。
- 对象相等
==操作符用于测试两个被引用的对象的值是否相等,is用于比较两个被引用的对象是否是同一个对象
>>> a = [1, 2, 3]
>>> b = a
>>> a is b
True # a和b指向相同的对象
>>> a = [1, 2, 3]
>>> b = [1, 2, 3]
>>> a is b
False # a和b指向不同的对象
当操作对象为一个较小的数字或较短的字符串时,又有不同:
>>> a = 7
>>> b = 7
>>> a is b
True # a和b指向相同的对象
这是由于python的缓存机制造成的,小的数字和字符串被缓存并复用,所以a和b指向同一个对象
- 对象回收机制
上边提到对象包含一个引用的计数器,计数器记录了当前指向该对象引用的数目,一旦对象的计数器为 0 ,即不存在对该对象的引用,则这个对象的内存空间会被回收。这就是python中对象的回收机制,一个最明显的好处即在编写代码过程中不需要考虑释放内存空间。
可以通过sys模块中的getrefcount()函数查询一个对象计数器的值
>>> import sys
>>> sys.getrefcount(1)
718
2.4 编码基础知识
计算机中储存的信息都是用二进制数表示的;而我们在屏幕上看到的英文、汉字等字符是二进制数转换之后的结果。通俗的说,按照何种规则将字符存储在计算机中,如'a'用什么表示,称为"编码";反之,将存储在计算机中的二进制数解析显示出来,称为"解码",如同密码学中的加密和解密。在解码过程中,如果使用了错误的解码规则,则导致'a'解析成'b'或者乱码。
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对。即在符号集合与数字系统之间建立对应关系,它是信息处理的一项基本技术。通常人们用符号集合(一般情况下就是文字)来表达信息。而以计算机为基础的信息处理系统则是利用元件(硬件)不同状态的组合来存储和处理信息的。元件不同状态的组合能代表数字系统的数字,因此字符编码就是将符号转换为计算机可以接受的数字系统的数,称为数字代码。
2.4.1 常用字符集和字符编码
常见字符集名称:ASCII字符集、GB2312字符集、BIG5字符集、GB18030字符集、Unicode字符集等。计算机要准确的处理各种字符集文字,需要进行字符编码,以便计算机能够识别和存储各种文字。
- ASCII字符集&编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统。它主要用于显示现代英语,而其扩展版本EASCII则可以勉强显示其他西欧语言。它是现今最通用的单字节编码系统(但是有被Unicode追上的迹象),并等同于国际标准ISO/IEC 646。
ASCII字符集:主要包括控制字符(回车键、退格、换行键等);可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
ASCII编码:将ASCII字符集转换为计算机可以接受的数字系统的数的规则。使用7位(bits)表示一个字符,共128字符;但是7位编码的字符集只能支持128个字符,为了表示更多的欧洲常用字符对ASCII进行了扩展,ASCII扩展字符集使用8位(bits)表示一个字符,共256字符。ASCII字符集映射到数字编码规则如下图所示:
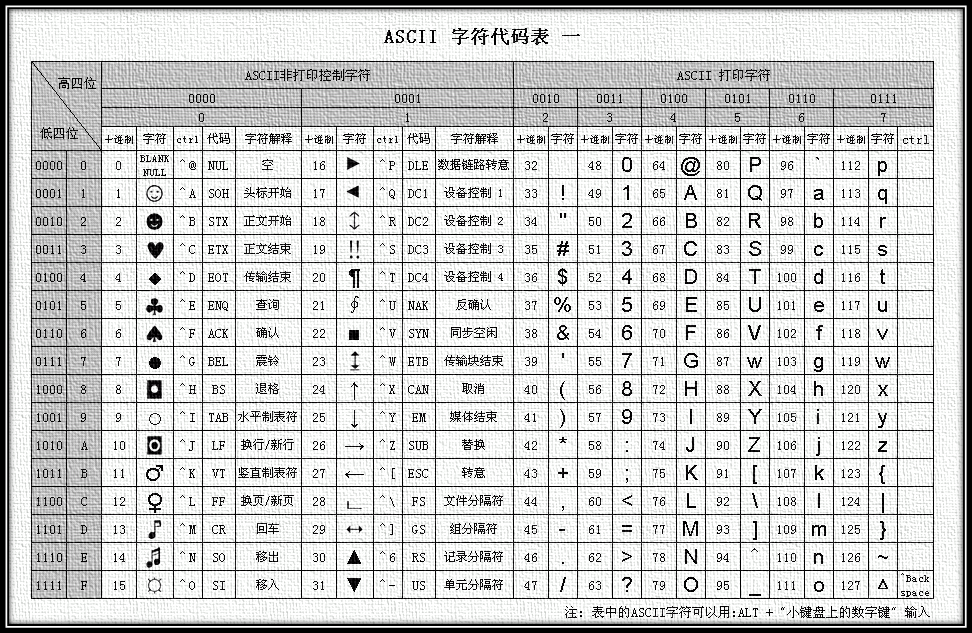
ASCII的最大缺点是只能显示26个基本拉丁字母、阿拉伯数目字和英式标点符号,因此只能用于显示现代美国英语(而且在处理英语当中的外来词如naïve、café、élite等等时,所有重音符号都不得不去掉,即使这样做会违反拼写规则)。而EASCII虽然解决了部份西欧语言的显示问题,但对更多其他语言依然无能为力。因此现在的苹果电脑已经抛弃ASCII而转用Unicode。
GBXXXX字符集&编码
计算机发明之处及后面很长一段时间,只用应用于美国及西方一些发达国家,ASCII能够很好满足用户的需求。但是当天朝也有了计算机之后,为了显示中文,必须设计一套编码规则用于将汉字转换为计算机可以接受的数字系统的数。
天朝专家把那些127号之后的奇异符号们(即EASCII)取消掉,规定:一个小于127的字符的意义与原来相同,但两个大于127的字符连在一起时,就表示一个汉字,前面的一个字节(他称之为高字节)从0xA1用到0xF7,后面一个字节(低字节)从0xA1到0xFE,这样我们就可以组合出大约7000多个简体汉字了。在这些编码里,还把数学符号、罗马希腊的 字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
上述编码规则就是GB2312。GB2312或GB2312-80是中国国家标准简体中文字符集,全称《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。GB2312编码通行于中国大陆;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。GB2312的出现,基本满足了汉字的计算机处理需要,它所收录的汉字已经覆盖中国大陆99.75%的使用频率。对于人名、古汉语等方面出现的罕用字,GB2312不能处理,这导致了后来GBK及GB18030汉字字符集的出现。下图是GB2312编码的开始部分(由于其非常庞大,只列举开始部分,具体可查看GB2312简体中文编码表):
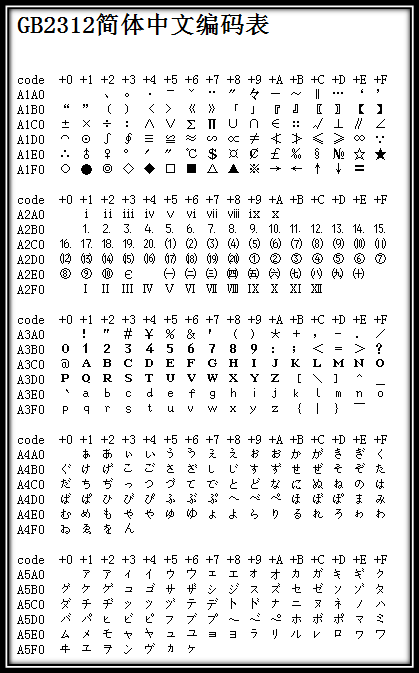
由于GB2312-80只收录6763个汉字,有不少汉字,如部分在GB2312-80推出以后才简化的汉字(如"啰"),部分人名用字(如中国前总理朱镕基的"镕"字),台湾及香港使用的繁体字,日语及朝鲜语汉字等,并未有收录在内。于是厂商微软利用GB2312-80未使用的编码空间,收录GB 13000.1-93全部字符制定了GBK编码。根据微软资料,GBK是对GB2312-80的扩展,也就是CP936字码表(Code Page 936)的扩展(之前CP936和GB2312-80一模一样),最早实现于Windows 95简体中文版。虽然GBK收录GB13000.1-93的全部字符,但编码方式并不相同。GBK自身并非国家标准,只是曾由国家技术监督局标准化司、电子工业部科技与质量监督司公布为"技术规范指导性文件"。原始GB13000一直未被业界采用,后续国家标准GB18030技术上兼容GBK而非GB13000。
Unicode以及对应编码
像天朝一样,当计算机传到世界各个国家时,为了适合当地语言和字符,设计和实现类似GB232/GBK/GB18030/BIG5的编码方案。这样各搞一套,在本地使用没有问题,一旦出现在网络中,由于不兼容,互相访问就出现了乱码现象。
为了解决这个问题,一个伟大的创想产生了——Unicode。Unicode编码系统为表达任意语言的任意字符而设计。它使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph)。每个数字代表唯一的至少在某种语言中使用的符号。(并不是所有的数字都用上了,但是总数已经超过了65535,所以2个字节的数字是不够用的。)被几种语言共用的字符通常使用相同的数字来编码,除非存在一个在理的语源学(etymological)理由使不这样做。不考虑这种情况的话,每个字符对应一个数字,每个数字对应一个字符。即不存在二义性。不再需要记录"模式"了。U+0041总是代表'A',即使这种语言没有'A'这个字符。
在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式对外发表。Unicode 还不断在扩增, 每个新版本插入更多新的字符。直至目前为止的第六版,Unicode就已经包含了超过十万个字符(在2005年,Unicode的第十万个字符被采纳且认可成为标准之一)、一组可用以作为视觉参考的代码图表、一套编码方法与一组标准字符编码、一套包含了上标字、下标字等字符特性的枚举等。Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导Unicode的后续发展,其目标在于:将既有的字符编码方案以Unicode编码方案来加以取代,特别是既有的方案在多语环境下,皆仅有有限的空间以及不兼容的问题。(Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。)
UTF-32
上述使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案,称为UTF-32。UTF-32又称UCS-4是一种将Unicode字符编码的协定,对每个字符都使用4字节。就空间而言,是非常没有效率的。
这种方法有其优点,最重要的一点就是可以在常数时间内定位字符串里的第N个字符,因为第N个字符从第4×Nth个字节开始。虽然每一个码位使用固定长定的字节看似方便,它并不如其它Unicode编码使用得广泛。
UTF-16
尽管有Unicode字符非常多,但是实际上大多数人不会用到超过前65535个以外的字符。因此,就有了另外一种Unicode编码方式,叫做UTF-16(因为16位 = 2字节)。UTF-16将0–65535范围内的字符编码成2个字节,如果真的需要表达那些很少使用的"星芒层(astral plane)"内超过这65535范围的Unicode字符,则需要使用一些诡异的技巧来实现。UTF-16编码最明显的优点是它在空间效率上比UTF-32高两倍,因为每个字符只需要2个字节来存储(除去65535范围以外的),而不是UTF-32中的4个字节。并且,如果我们假设某个字符串不包含任何星芒层中的字符,那么我们依然可以在常数时间内找到其中的第N个字符,直到它不成立为止这总是一个不错的推断。其编码方法是:
如果字符编码U小于0x10000,也就是十进制的0到65535之内,则直接使用两字节表示; 如果字符编码U大于0x10000,由于UNICODE编码范围最大为0x10FFFF,从0x10000到0x10FFFF之间 共有0xFFFFF个编码,也就是需要20个bit就可以标示这些编码。用U'表示从0-0xFFFFF之间的值,将其前 10 bit作为高位和16 bit的数值0xD800进行 逻辑or 操作,将后10 bit作为低位和0xDC00做 逻辑or 操作,这样组成的 4个byte就构成了U的编码。
对于UTF-32和UTF-16编码方式还有一些其他不明显的缺点。不同的计算机系统会以不同的顺序保存字节。这意味着字符U+4E2D在UTF-16编码方式下可能被保存为4E 2D或者2D 4E,这取决于该系统使用的是大尾端(big-endian)还是小尾端(little-endian)。(对于UTF-32编码方式,则有更多种可能的字节排列。)只要文档没有离开你的计算机,它还是安全的——同一台电脑上的不同程序使用相同的字节顺序(byte order)。但是当我们需要在系统之间传输这个文档的时候,也许在万维网中,我们就需要一种方法来指示当前我们的字节是怎样存储的。不然的话,接收文档的计算机就无法知道这两个字节4E 2D表达的到底是U+4E2D还是U+2D4E。
为了解决这个问题,多字节的Unicode编码方式定义了一个"字节顺序标记(Byte Order Mark)",它是一个特殊的非打印字符,你可以把它包含在文档的开头来指示你所使用的字节顺序。对于UTF-16,字节顺序标记是U+FEFF。如果收到一个以字节FF FE开头的UTF-16编码的文档,你就能确定它的字节顺序是单向的(one way)的了;如果它以FE FF开头,则可以确定字节顺序反向了。
UTF-8
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码(定长码),也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部份修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。
UTF-8使用一至四个字节为每个字符编码:
- 128个US-ASCII字符只需一个字节编码(Unicode范围由U+0000至U+007F)。
- 带有附加符号的拉丁文、希腊文、西里尔字母、亚美尼亚语、希伯来文、阿拉伯文、叙利亚文及它拿字母则需要二个字节编码(Unicode范围由U+0080至U+07FF)。
- 其他基本多文种平面(BMP)中的字符(这包含了大部分常用字)使用三个字节编码。
- 其他极少使用的Unicode辅助平面的字符使用四字节编码。在处理经常会用到的ASCII字符方面非常有效。在处理扩展的拉丁字符集方面也不比UTF-16差。对于中文字符来说,比UTF-32要好。同时,由位操作的天性使然,使用UTF-8不再存在字节顺序的问题了。一份以utf-8编码的文档在不同的计算机之间是一样的比特流。
总体来说,在Unicode字符串中不可能由码点数量决定显示它所需要的长度,或者显示字符串之后在文本缓冲区中光标应该放置的位置;组合字符、变宽字体、不可打印字符和从右至左的文字都是其归因。所以尽管在UTF-8字符串中字符数量与码点数量的关系比UTF-32更为复杂,在实际中很少会遇到有不同的情形。
优点
- UTF-8是ASCII的一个超集。因为一个纯ASCII字符串也是一个合法的UTF-8字符串,所以现存的ASCII文本不需要转换。为传统的扩展ASCII字符集设计的软件通常可以不经修改或很少修改就能与UTF-8一起使用。
- 使用标准的面向字节的排序例程对UTF-8排序将产生与基于Unicode代码点排序相同的结果。(尽管这只有有限的有用性,因为在任何特定语言或文化下都不太可能有仍可接受的文字排列顺序。)
- UTF-8和UTF-16都是可扩展标记语言文档的标准编码。所有其它编码都必须通过显式或文本声明来指定。
- 任何面向字节的字符串搜索算法都可以用于UTF-8的数据(只要输入仅由完整的UTF-8字符组成)。但是,对于包含字符记数的正则表达式或其它结构必须小心。
- UTF-8字符串可以由一个简单的算法可靠地识别出来。就是,一个字符串在任何其它编码中表现为合法的UTF-8的可能性很低,并随字符串长度增长而减小。举例说,字符值C0,C1,F5至FF从来没有出现。为了更好的可靠性,可以使用正则表达式来统计非法过长和替代值(可以查看W3 FAQ: Multilingual Forms上的验证UTF-8字符串的正则表达式)。
缺点
因为每个字符使用不同数量的字节编码,所以寻找串中第N个字符是一个O(N)复杂度的操作 — 即,串越长,则需要更多的时间来定位特定的字符。同时,还需要位变换来把字符编码成字节,把字节解码成字符。
2.4.2 python中的编码
import sys, locale
s = "小甲"
print(s) # 小甲
print(type(s)) # <class 'str'>
# 系统默认编码,python编译器本身的默认编码
print(sys.getdefaultencoding()) # utf-8
# 本地默认编码(操作系统的编码)
print(locale.getdefaultlocale()) # ('zh_CN', 'UTF-8')
with open("utf1","w",encoding = "utf-8") as f:
f.write(s)
with open("gbk1","w",encoding = "gbk") as f:
f.write(s)
with open("jis1","w",encoding = "shift-jis") as f:
f.write(s)
系统默认编码指在python3编译器读取.py文件时,若没有头文件编码声明,则默认使用“utf-8”来对.py文件进行解码。并且在调用encode()这个函数时,不传参的话默认是“utf-8”。(与下面的open()函数中的“encoding”参数要做区分)
本地默认编码指在你编写的python3程序时,若使用了open()函数,而不给它传入"encoding"这个参数,那么会自动使用本地默认编码。
2.5 python代码调试
print可能错误的变量
# err.py
def foo(s):
n = int(s)
print '>>> n = %d' % n
return 10 / n
foo('0')
用print最大的坏处是将来还得删掉它。
assert断言
凡是用print来辅助查看的地方,都可以用断言(assert)来替代:
# err.py
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
foo('0')
assert的意思是,表达式n!=0应该是True,否则,后面的代码就会出错。如果断言失败,assert语句本身就会抛出AssertionError,在启动Python解释器时可以用-O参数来关闭assert,关闭后,可以把所有的assert语句当成pass来看。
logging
logging不会抛出错误,而且可以输出到文件:
# err.py
import logging
logging.basicConfig(level=logging.INFO)
s = '0'
n = int(s)
logging.info('n = %d' % n)
print 10 / n
logging允许你指定记录信息的级别,有debug,info,warning,error等几个级别。logging的另一个好处是通过简单的配置,一条语句可以同时输出到不同的地方,比如console和文件。
pdb
启动python的调试器pdb,让程序以单步方式运行,可以随时查看运行状态。
# err.py
s = '0'
n = int(s)
print 10 / n
然后启动:python -m pdb err.py,以参数-m pdb启动后, pdb定位到下一步要执行的代码-> s = '0'。输入命令l来查看代码,输入命令n可以单步执行代码,任何时候都可以输入命令p 变量名来查看变量,输入命令q结束调试,退出程序。
pdb.set_trace()不需要单步执行,只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点:
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print 10 / n
pdb常用命令
| 命令 | 解释 |
|---|---|
break或b设置断点 |
设置断点 |
continue或c |
继续执行程序 |
list或l |
查看当前行的代码段 |
step或s |
进入函数 |
return或r |
执行代码直到从当前函数返回 |
exit或q |
中止并退出 |
next或n |
执行下一行 |
pp |
打印变量的值 |
help |
帮助 |
2.6 python代码执行shell
os.system()
>>> os.system('ls')
anaconda-ks.cfg install.log install.log.syslog
这个方法得不到shell命令的输出
os.popen()
这个方法能得到命令执行后的结果,其中结果以字符串显示,要自行处理才能得到想要的信息。
# os.popen(command[, mode[, bufsize]])
>>> import os
>>> str = os.popen("ls").read()
>>> a = str.split("\n")
>>> for b in a:
print(b)
这样得到的结果与第一个方法是一样的。
commands模块
可以很方便的取得命令的输出(包括标准和错误输出)和执行状态位
>>> import commands
>>> a,b = commands.getstatusoutput('ls') # a是退出状态,b是输出的结果。
>>> print a
0
>>> print b
anaconda-ks.cfg
install.log
install.log.syslog
commands.getstatusoutput(cmd)返回(status,output),commands.getoutput(cmd)只返回输出结果;commands.getstatus(file)返回ls -ld file的执行结果字符串。
subprocess模块
使用subprocess模块可以创建新的进程,可以与新建进程的输入/输出/错误管道连通,并可以获得新建进程执行的返回状态。使用subprocess模块的目的是替代os.system()、os.popen*()、commands.*等旧的函数或模块。
subprocess.call(command, shell=True): 会直接打印出结果。
subprocess.Popen(command, shell=True): 也可以是subprocess.Popen(command, stdout=subprocess.PIPE, shell=True)这样就可以输出结果了。
2.7 特殊的内置函数
参考链接:python3内置函数
compile()函数
compile()函数将一个字符串编译为字节代码。
compile()方法的语法:compile(source, filename, mode[, flags[, dont_inherit]])
参数:
- source: 字符串或者AST(Abstract Syntax Trees)对象。
- filename: 代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
- mode:指定编译代码的种类,可以指定为exec,eval,single。
- flags: 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。。
- flags和dont_inherit是用来控制编译源码时的标志
返回值:返回表达式执行结果。
>>>str = "for i in range(0,2): print(i)"
>>> c = compile(str,'','exec') # 编译为字节代码对象
>>> c
<code object <module> at 0x10141e0b0, file "", line 1>
>>> exec(c)
0
1
>>> str = "3 * 4 + 5"
>>> a = compile(str,'','eval')
>>> eval(a)
17
dict()函数
dict()函数用于创建一个字典。
dict 语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数说明:
**kwargs -- 关键字
mapping -- 元素的容器。
iterable -- 可迭代对象。
返回值:
返回一个字典。
# 代码示例
>>>dict() # {}, 创建空字典
>>> dict(a='a', b='b', t='t') # {'a': 'a', 'b': 'b', 't': 't'},传入关键字
>>> dict(zip(['one', 'two', 'three'], [1, 2, 3])) # {'three': 3, 'two': 2, 'one': 1},映射函数方式来构造字典
>>> dict([('one', 1), ('two', 2), ('three', 3)]) # {'three': 3, 'two': 2, 'one': 1},可迭代对象方式来构造字典
enumerate()函数
enumerate()函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
enumerate()方法的语法: enumerate(sequence, [start=0])
参数
sequence -- 一个序列、迭代器或其他支持迭代对象。
start -- 下标起始位置。
返回值
返回 enumerate(枚举)对象。
# 代码示例
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>>list(enumerate(seasons)) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>>list(enumerate(seasons, start=3)) # [(3, 'Fall'), (4, 'Winter')],小标从3开始
eval()函数
eval()函数用来执行一个字符串表达式,并返回表达式的值。
eval()方法的语法: eval(expression[, globals[, locals]])
参数:
- expression: 表达式。
- globals: 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
- locals: 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值:返回表达式计算结果。
# 代码示例
>>> x = 7
>>> eval( '3 * x' ) # 21
>>> eval('pow(2,2)') # 4
exec函数
exec执行储存在字符串或文件中的Python语句,相比于eval,exec可以执行更复杂的Python代码。
exec的语法: exec(object[, globals[, locals]])
参数:
- object: 必选参数,表示需要被指定的Python代码。它必须是字符串或code对象。如果object是一个字符串, 该字符串会先被解析为一组Python语句,然后在执行(除非发生语法错误)。如果object是一个code对象,那么它只是被简单的执行。
- globals: 可选参数,表示全局命名空间(存放全局变量),如果被提供,则必须是一个字典对象。
- locals:可选参数,表示当前局部命名空间(存放局部变量),如果被提供,可以是任何映射对象。如果该参数被忽略,那么它将会取与globals相同的值。
返回值: exec返回值永远为None。
# 代码示例
>>>exec('print("Hello World")') # Hello World
>>> exec("print ('runoob.com')") # runoob.com
>>> exec ("""for i in range(2):
... print ("iter time: %d" % i)
... """)
iter time: 0
iter time: 1
filter()函数
filter()函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用list()来转换。该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回True或False,最后将返回True的元素放到新列表中。filter()方法的语法: filter(function, iterable)
参数
function: 判断函数
iterable: 可迭代对象。
返回值: 返回一个迭代器对象
# 1. 过滤出列表中的所有奇数:
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
print(list(tmplist)) # [1, 3, 5, 7, 9]
# 2. 过滤出1~100中平方根是整数的数:
import math
def is_sqr(x):
return math.sqrt(x) % 1 == 0
tmplist = filter(is_sqr, range(1, 101))
print(list(tmplist))
# [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
frozenset()函数
frozenset()返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
frozenset()函数语法: class frozenset([iterable])
参数
iterable -- 可迭代的对象,比如列表、字典、元组等等。
返回值
返回新的frozenset对象,如果不提供任何参数,默认会生成空集合。
# 代码示例
>>> a = frozenset(range(10))
# frozenset([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]),生成一个新的不可变集合
>>> b = frozenset('runoob')
# frozenset(['b', 'r', 'u', 'o', 'n']), 创建不可变集合
getattr()函数
getattr()函数用于返回一个对象属性值。
getattr语法: getattr(object, name[, default])
参数
object -- 对象。
name -- 字符串,对象属性。
default -- 默认返回值,如果不提供该参数,在没有对应属性时,将触发 AttributeError。
返回值
返回对象属性值。
# 代码示例
>>>class A(object):
... bar = 1
...
>>> a = A()
>>> getattr(a, 'bar') # 1, 获取属性bar值
hasattr()函数
hasattr()函数用于判断对象是否包含对应的属性。
hasattr语法:hasattr(object, name)
参数
object -- 对象。
name -- 字符串,属性名。
返回值
如果对象有该属性返回True,否则返回False。
# 代码示例
class Coordinate:
x = 10
point1 = Coordinate()
print(hasattr(point1, 'x'))
print(hasattr(point1, 'no')) # 没有该属性
输出结果:
True
False
hash()函数
hash()用于获取取一个对象(字符串或者数值等)的哈希值。
hash 语法: hash(object)
参数说明:
object -- 对象;
返回值
返回对象的哈希值。
# 代码示例
>>> hash('test') # 2314058222102390712, 字符串
>>> hash(1) # 1, 数字
>>> hash(str([1,2,3])) # 1335416675971793195, 集合
id()函数
id()函数用于获取对象的内存地址。
id语法: id([object])
参数说明:
object -- 对象。
返回值
返回对象的内存地址。
# 代码示例
>>> a = 'runoob'
>>> id(a) # 4531887632
issubclass()函数
issubclass()方法用于判断参数class是否是类型参数classinfo的子类。
issubclass()方法的语法: issubclass(class, classinfo)
参数
class -- 类。
classinfo -- 类。
返回值
如果class是classinfo的子类返回 True,否则返回 False。
class A:
pass
class B(A):
pass
print(issubclass(B,A)) # 返回True
iter()函数
iter()函数用来生成迭代器。
iter()方法的语法: iter(object[, sentinel])
参数
object -- 支持迭代的集合对象。
sentinel -- 如果传递了第二个参数,则参数object必须是一个可调用的对象(如函数),
此时,iter创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用object。
返回值
迭代器对象。
map()函数
map()会根据提供的函数对指定序列做映射。第一个参数function以参数序列中的每一个元素调用function函数,返回包含每次function函数返回值的新列表。map()函数语法: map(function, iterable, ...)
参数:
function: 函数
iterable: 一个或多个序列
返回值: python 2.x返回列表,python 3.x返回迭代器。
# 代码示例
map(lambda x: x ** 2, [1, 2, 3, 4, 5]) # [1, 4, 9, 16, 25]
三、进程线程和协程
3.1 进程
- 进程介绍:
进程是一个实体,每个进程都有自己的地址空间(CPU分配)。实体空间包括三部分:
- 文本区域:存储处理器执行的代码。
- 数据区域:存储变量或进程执行期间使用的动态分配的内存。
- 堆栈:进程执行时调用的指令和本地变量。
进程是一个“执行中的程序”。程序是指令与数据的有序集合,程序本身是没有生命的,只有CPU赋予程序生命时(CPU执行程序),它才能成为一个活动的实体,称为"进程"。概括来说,进程就是一个具有独立功能的程序在某个数据集上的一次运行活动
进程的特点:
- 动态性:进程是程序的一次执行过程,动态产生,动态消亡。
- 独立性:进程是一个能独立运行的基本单元。是系统分配资源与调度的基本单元。
- 并发性:任何进程都可以与其他进程并发执行。
每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程比较重要,占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大,但相对比较稳定安全。
- 并发与并行
概念
并发:在操作系统中,某一时间段,几个程序在同一个CPU上运行,但在任意一个时间点上,只有一个程序在CPU上运行。当有多个线程时,如果系统只有一个CPU,那么CPU不可能真正同时进行多个线程,CPU的运行时间会被划分成若干个时间段,每个时间段分配给各个线程去执行,一个时间段里某个线程运行时,其他线程处于挂起状态,这就是并发。并发解决了程序排队等待的问题,如果一个程序发生阻塞,其他程序仍然可以正常执行。
并行:当操作系统有多个CPU时,一个CPU处理A线程,另一个CPU处理B线程,两个线程互相不抢占CPU资源,可以同时进行,这种方式成为并行。
区别 并发只是在宏观上给人感觉有多个程序在同时运行,但在实际的单CPU系统中,每一时刻只有一个程序在运行,微观上这些程序是分时交替执行。在多CPU系统中,将这些并发执行的程序分配到不同的CPU上处理,每个CPU用来处理一个程序,这样多个程序便可以实现同时执行。
python函数
python中查询线程/进程信息的函数:
- os.uname():返回当前操作系统的识别信息,返回值是一个有5个属性的对象:sysname(操作系统名),nodename(机器在网络上的名称[需要先设定]),release(操作系统发行信息),version(操作系统版本信息)和machine(硬件标识符),类似于Linux上的uname命令。
- os.umask(mask):设定当前数值掩码并返回之前的掩码,类似于Linux上的umask命令。
- os.get*():查询相关信息(*由以下代替):
- uid:返回当前进程的真实用户ID
- euid:返回当前进程的有效用户ID
- resuid:回一个由(ruid,euid,suid)所组成的元组,分别表示当前进程的真实用户ID,有效用户ID和甲暂存用户ID
- gid:返回当前进程的实际组ID
- egid:返回当前进程的有效组ID,对应当前进程执行文件的"set id"位
- resgid:返回一个由(rgid,egid,sgid)所组成的元组,分别表示当前进程的真实组ID,有效组ID和暂存组ID
- pid:返回当前进程ID
- pgid:根据进程id pid返回进程的组ID列表,如果pid为0,则返回当前进程的进程组ID列表
- ppid:返回父进程ID,当父进程已经结束,在Unix中返回的ID是初始进程(1)中的一个,在Windows中仍然是同一个进程ID,该进程ID有可能已经被进行进程所占用
- getsid:调用系统调用 getsid()
- os.put*():设置相关信息(*与get*相同)
- os.getenviron():获得进程的环境变量
- os.setenviron():更改进程的环境变量
多进程一般使用multiprocessing库,来利用多核CPU,主要是用在CPU密集型的程序上,当然生产者消费者这种也可以使用。多进程的优势就是一个子进程崩溃并不会影响其他子进程和主进程的运行,但缺点就是不能一次性启动太多进程,会严重影响系统的资源调度,特别是CPU使用率和负载。
- 创建进程
Process介绍:
构造方法:
Process([group [, target [, name [, args [, kwargs]]]]])
group::线程组,目前还没有实现,库引用中提示必须是None;
target:要执行的方法;
name:进程名;
args/kwargs:要传入方法的参数
实例方法:
is_alive():返回进程是否在运行
join([timeout]):阻塞当前上下文环境的进程程,直到调用此方法的进程终止或到达指定的timeout(可选参数)
start():进程准备就绪,等待CPU调度
run():strat()调用run方法,如果实例进程时未制定传入target,这star执行t默认run()方法
terminate():不管任务是否完成,立即停止工作进程
属性:
authkey
daemon:和线程的setDeamon功能一样(将父进程设置为守护进程,当父进程结束时,子进程也结束)
exitcode(进程在运行时为None,如果为N表示被信号N结束)
name:进程名字
pid:进程号
# 查看进程信息内容
multiprocessing.cpu_count() # 获取CPUs数量
multiprocessing.active_children() # 获取现在进程下激活的子进程
multiprocessing.current_process() # 获取现在运行的进程
# Process创建进程
from multiprocessing import Process
import os
def func(name):
print('hello {}'.format(name))
if hasattr(os, 'getppid'):
print('parent process: {}'.format(os.getppid()))
print('process id:{}'.format(os.getpid()))
if __name__ == '__main__':
p = Process(target=func, args=('bob',))
print(p.pid)
p.start()
print(p.pid)
p.join()
- 进程交换
# 不同进程之间交换对象
from multiprocessing import Process, Queue,Pipe
def func_queue(q):
q.put([42,None, 'queue'])
def func_pipe(conn):
conn.send([42, None, 'pipe'])
conn.close()
if __name__ == '__main__':
# 队列方法
q = Queue()
p = Process(target=func_queue, args=(q,))
p.start()
print(q.get()) # prints "[42, None, 'hello']"
p.join()
# 管道方法
parent_conn, child_conn = Pipe()
p = Process(target=func_pipe, args=(child_conn,))
p.start()
print(parent_conn.recv()) # prints "[42, None, 'hello']"
p.join()
- 进程同步
# 不同进程之间的同步
from multiprocessing import Process, Lock
def func(l, i):
l.acquire()
print('hello world {}.'.format(i))
l.release()
if __name__ == '__main__':
# 创建进程
lock = Lock()
for num in range(10):
Process(target=func, args=(lock, num)).start()
- 进程分享
# 进程间分享状态
from multiprocessing import Process, Value, Array,Manager
def func_memory(n, a):
n.value = 3.1415927
for i in range(len(a)):
a[i] = -a[i]
def func_server(d,l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.reverse()
if __name__ == '__main__':
# 内存分享
num = Value('d', 0.0)
arr = Array('i', range(10))
p = Process(target=func_memory, args=(num, arr))
p.start()
p.join()
print("{}\t{}.".format(num.value,arr[:]))
# 服务器Manager
manager = Manager()
d = manager.dict()
l = manager.list(range(10))
p = Process(target=func_server, args=(d, l))
p.start()
p.join()
print("{}\t{}.".format(d,l))
- 批量进程
# 批量创建进程
from multiprocessing import Pool, TimeoutError
import time, os
def func(x):
return x*x
if __name__ == '__main__':
pool = Pool(processes=4)
# map方法(返回有序的结果)
print(pool.map(func, range(10)))
# 以无序的方式打印
print(" ".join([str(i) for i in pool.imap_unordered(func, range(10))]))
# 验证异步的"os.getpid()"
res = pool.apply_async(os.getpid, ())
print(res.get(timeout=1))
# 开启多个线程验证
multiple_results = [pool.apply_async(os.getpid, ()) for i in range(4)]
print([res.get(timeout=1) for res in multiple_results])
# 让一个进程休息10seconds
res = pool.apply_async(time.sleep, (10,))
try:
print(res.get(timeout=1))
except TimeoutError:
print("We lacked patience and got a multiprocessing.TimeoutError")
# 多进程模版
import time
from multiprocessing import Pool, TimeoutError
pool = Pool(processes=4)
result = pool.map(time.sleep, range(4))
pool.close()
pool.join()
- 继承Process类
继承Process类,修改run函数代码
from multiprocessing import Process
import time
class MyProcess(Process):
# 继承Process类,类似threading.Thread
def __init__(self, arg):
super(MyProcess, self).__init__()
# multiprocessing.Process.__init__(self)
self.arg = arg
def run(self):
# 重构run函数
print('nMask {}'.format(self.arg))
time.sleep(1)
if __name__ == '__main__':
for i in range(10):
p = MyProcess(i)
p.start()
for i in range(10):
p.join()
3.2 线程
- 线程的引入
60年代,操作系统中拥有资源并独立运行的基本单位是进程,进程是资源的拥有者,进程的创建、撤销、切换花销太大。多CPU处理出现,可以满足多个单位同时运行,但是多个进程并行花销太大。80年代,出现了轻量级的,能够独立运行的基本单位。线程间通信主要通过共享内存,上下文切换很快,资源开销较少,但相比进程不够稳定容易丢失数据。
- 线程的概念
线程是进程中的一个实体,是被系统独立调度和分派的基本单位。线程的实体包括程序,数据,TCB。TCB包括:
- 线程状态
- 线程不运行时,被保存的现场资源
- 一组执行堆栈
- 每个线程的局部变量
- 访问统一进程中的资源
- 线程自己不拥有系统资源,只拥有一点运行中必不可少的资源。
- 同一进程中的多个线程并发执行,这些线程共享进程所拥有的资源。
- 进程与线程的区别
- 进程是CPU资源分配的基本单位,线程是独立运行和独立调度的基本单位(CPU上真正运行的是线程)。
- 进程拥有自己的资源空间,一个进程包含若干个线程,线程与CPU资源分配无关,多个线程共享同一进程内的资源。
- 线程的调度与切换比进程快很多。
python函数
多线程一般是使用threading库,完成一些IO密集型并发操作。多线程的优势是切换快,资源消耗低,但一个线程挂掉则会影响到所有线程,所以不够稳定。现实中使用线程池的场景会比较多。
# 工具函数
threading.currentThread() # 返回当前的线程变量。
threading.enumerate() # 返回一个包含正在运行的线程的list(正在运行指线程启动后、结束前,不包括启动前和终止后的线程)。
threading.activeCount() # 返回正在运行的线程数量.
threading.Timer # 可以在指定时间间隔后执行某个操作。
Thread类提供了以下方法:
run(): 用以表示线程活动的方法。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(name): 设置线程名。
ident:获取线程的标识符。线程标识符是一个非零整数,只有在调用了start()方法之后该属性才有效,否则它只返回None。
- 创建线程
# 简单启动多线程
import threading
# 构造Thread对象, 执行多线程
def thread_fun(num):
print("I come from %s, num: %s." %( threading.currentThread().getName(), num))
thread_list, thread_num = [], 10
for i in range(0, thread_num):
thread_name = "thread_%s" %i
# 常见线程
thread_list.append(threading.Thread(target = thread_fun, name = thread_name, args = (i,)))
# 启动所有线程
for thread in thread_list:
thread.start()
# 主线程中等待所有子线程退出
for thread in thread_list:
thread.join()
- 继承线程类
# 类继承threading.Thread类:
import threading
class TestThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self);
def run(self):
print("I am %s" %self.name)
for thread in range(0, 5):
TestThread().start()
- 批量线程
# 批量多线程
from multiprocessing.dummy import Pool as ThreadPool
urls=['http;//www.baidu.com','http;//www.weibo.com']
pool = ThreadPool(processes=8)
results = pool.map(urllib2.urlopen, urls)
pool.close()
pool.join()
3.3 协程
- 协程是一种用户态的轻量级线程,一种比线程更加轻量级的存在,最重要的是,协程不被操作系统内核管理,协程是完全由程序控制的。
- 协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈,直接操作栈则基本没有内核切换的开销
- 运行效率极高,协程的切换完全由程序控制,不像线程切换需要花费操作系统的开销,线程数量越多,协程的优势就越明显。
- 协程不需要多线程的锁机制,因为只有一个线程,不存在变量冲突。
协程一般是使用gevent库,当然这个库用起来比较麻烦,所以使用的并不是很多。相反,协程在tornado的运用就多得多了,使用协程让tornado做到单线程异步,据说还能解决C10K的问题。所以协程使用的地方最多的是在web应用上。
import gevent,urllib2
from gevent import monkey
monkey.patch_all()
urls = ['http://www.baidu.com','http://www.zhihu.com','http://www.weibo.com']
def print_head(url):
print ('Starting %s' % url)
data = urllib2.urlopen(url).read()
print ('%s: %s bytes: %r.' % (url, len(data), data[:50]))
jobs = [gevent.spawn(print_head, url) for url in urls]
gevent.joinall(jobs)
对于多核CPU,利用多进程+协程的方式,能充分利用CPU,获得极高的性能。
- Python中使用协程的例子
yield关键字相当于是暂停功能,程序运行到yield停止,send函数可以传参给生成器函数,参数赋值给yield。
def customer():
while True:
number = yield
print('开始消费:',number)
custom = customer()
next(custom)
for i in range(10):
print('开始生产:',i)
custom.send(i)
3.4 进程线程和协程
- 三者的区别
- 进程与线程比较
线程是指进程内的一个执行单元,也是进程内的可调度实体。
线程与进程的区别
地址空间:线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间
- 资源拥有:进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源
- 线程是处理器调度的基本单位,但进程不是
二者均可并发执行:每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制
协程多与线程进行比较
一个线程可以有多个协程,一个进程也可以单独拥有多个协程,这样python中则能使用多核CPU。
- 线程进程都是同步机制,而协程则是异步
- 协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态
总结一下就是IO密集型一般使用多线程或者多进程,CPU密集型一般使用多进程,强调非阻塞异步并发的一般都是使用协程,当然有时候也是需要多进程线程池结合的,或者是其他组合方式。
3.5 python守护进程
守护进程最重要的特性是后台运行;它必须与其运行前的环境隔离开来,这些环境包括未关闭的文件描述符、控制终端、会话和进程组、工作目录以及文件创建掩码等;它可以在系统启动时从启动脚本/etc/rc.d中启动,可以由inetd守护进程启动,也可以有作业规划进程crond启动,还可以由用户终端(通常是shell)执行。
import sys, os
'''
开启守护进程的基本步骤:
1. fork出子进程,退出父进程
2. 子进程变更工作目录(chdir)、文件权限掩码(umask)、进程组和会话组(setsid)
3. 子进程fork孙子进程,退出子进程
4. 孙子进程刷新缓冲,重定向标准输入/输出/错误(一般到/dev/null,意即丢弃)
5. (可选)pid写入文件
'''
def daemonize (stdin='/dev/null', stdout='/dev/null', stderr='/dev/null'):
# 重定向标准文件描述符(默认情况下定向到/dev/null)
try:
pid = os.fork()
# 父进程(会话组头领进程)退出,这意味着一个非会话组头领进程永远不能重新获得控制终端。
if pid > 0: sys.exit(0) # 父进程退出
except OSError as e:
sys.stderr.write("fork #1 failed: (%d) %s\n" % (e.error, e.message) )
sys.exit(1)
# 从母体环境脱离(Step 2)
os.chdir("/") # chdir确认进程不保持任何目录于使用状态,否则不能umount一个文件系统。也可以改变到对于守护程序运行重要的文件所在目录
os.umask(0) # 调用umask(0)以便拥有对于写的任何东西的完全控制,因为有时不知道继承了什么样的umask。
os.setsid() # setsid调用成功后,进程成为新的会话组长和新的进程组长,并与原来的登录会话和进程组脱离。
# 执行第二次fork
try:
pid = os.fork()
if pid > 0: sys.exit(0) # 第二个父进程退出
except OSError, e:
sys.stderr.write("fork #2 failed: (%d) %s\n" % (e.error, e.message) )
sys.exit(1)
# 进程已经是守护进程了,重定向标准文件描述符
for f in sys.stdout, sys.stderr: f.flush()
si = open(stdin, 'r')
so = open(stdout, 'a+')
se = open(stderr, 'a+', 0)
# dup2函数原子化关闭和复制文件描述符
os.dup2(si.fileno(), sys.stdin.fileno())
os.dup2(so.fileno(), sys.stdout.fileno())
os.dup2(se.fileno(), sys.stderr.fileno())
sys.stdout.write('Daemon started with pid %d\n' % os.getpid())
if __name__ == "__main__":
daemonize('/dev/null','/tmp/daemon_stdout.log','/tmp/daemon_error.log')
# 要执行的函数
- 为什么要fork两次
第一次fork,是为了脱离终端控制的魔爪。父进程之所以退出,是因为终端敲击键盘、或者关闭时给它发送了信号;而fork出来的子进程,在父进程自杀后成为孤儿进程,进而被操作系统的init进程接管,因此脱离终端控制。
所以其实,第二次fork并不是必须的(很多开源项目里的代码就没有fork两次)。只不过出于谨慎考虑,防止进程再次打开一个控制终端。因为子进程现在是会话组长了(对话期的首次进程),有能力打开控制终端,再fork一次,孙子进程就不能打开控制终端了。
- 文件描述符
Linux是"一切皆文件",文件描述符是内核为已打开的文件所创建的索引,通常是非负整数。进程通过文件描述符执行IO操作。默认情况下,0代表标准输入,1代表标准输出,2代表标准错误。
- umask权限掩码
在Linux中,任何一个文件都有读(read)、写(write)和执行(execute)的三种使用权限。其中,读的权限用数字4代表,写权限是2,执行权限是1。命令ls -l可以查看文件权限,r/w/x分别表示具有读/写/执行权限。
任何文件,也都有用户(User),用户组(Group),其他组(Others)三种身份权限。一般用3个数字表示文件权限,例如754:
- 7,是User权限,即文件拥有者权限
- 5,是Group权限,拥有者所在用户组的组员所具有的权限
- 4,是Others权限,即其他组用户的权限啦
而umask是为了控制默认权限,防止新建文件或文件夹具有权限。系统一般默认为022(使用命令umask查看),表示默认创建文件的权限是644,文件夹是755。你应该可以看出它们的规律,就是文件权限和umask的相加结果为666,文件夹权限和umask的相加结果为777。
- 进程组
每个进程都属于一个进程组(PG,Process Group),进程组可以包含多个进程。进程组有一个进程组长(Leader),进程组长的ID(PID, Process ID)就作为整个进程组的ID(PGID,Process Groupd ID)。
- 会话组
登陆终端时,就会创造一个会话,多个进程组可以包含在一个会话中。而创建会话的进程,就是会话组长。已经是会话组长的进程,不可以再调用setsid()方法创建会话。因此,上面代码中,子进程可以调用setsid(),而父进程不能,因为它本身就是会话组长。
另外,sh(Bourne Shell)不支持会话机制,因为会话机制需要shell支持工作控制(Job Control)。
- 守护进程与后台进程
通过&符号,可以把命令放到后台执行。它与守护进程是不同的:
- 守护进程与终端无关,是被init进程收养的孤儿进程;而后台进程的父进程是终端,仍然可以在终端打印
- 守护进程在关闭终端时依然坚挺;而后台进程会随用户退出而停止,除非加上nohup
- 守护进程改变了会话、进程组、工作目录和文件描述符,后台进程直接继承父进程(shell)的
- 类实现守护进程
import sys, os, time, atexit, string
from signal import SIGTERM
class Daemon:
def __init__(self, pidfile, stdin='/dev/null', stdout='/dev/null', stderr='/dev/null'):
# 需要获取调试信息,改为stdin='/dev/stdin', stdout='/dev/stdout', stderr='/dev/stderr',以root身份运行。
self.stdin = stdin
self.stdout = stdout
self.stderr = stderr
self.pidfile = pidfile
def _daemonize(self):
try:
pid = os.fork() # 第一次fork,生成子进程,脱离父进程
if pid > 0: sys.exit(0) # 退出主进程
except OSError as e:
sys.stderr.write('fork #1 failed: %d (%s)\n'%(e.error, e.message))
sys.exit(1)
os.chdir("/") # 修改工作目录
os.setsid() # 设置新的会话连接
os.umask(0) # 重新设置文件创建权限
try:
pid = os.fork() # 第二次fork,禁止进程打开终端
if pid > 0: sys.exit(0)
except OSError as e:
sys.stderr.write('fork #2 failed: %d (%s)\n' %(e.error, e.message))
sys.exit(1)
# 重定向文件描述符
sys.stdout.flush()
sys.stderr.flush()
si = file(self.stdin, 'r')
so = file(self.stdout, 'a+')
se = file(self.stderr, 'a+', 0)
os.dup2(si.fileno(), sys.stdin.fileno())
os.dup2(so.fileno(), sys.stdout.fileno())
os.dup2(se.fileno(), sys.stderr.fileno())
# 注册退出函数,根据文件pid判断是否存在进程
atexit.register(self.delpid)
pid = str(os.getpid())
file(self.pidfile,'w+').write('%s\n'%pid)
def delpid(self):
os.remove(self.pidfile)
def start(self):
# 检查pid文件是否存在以探测是否存在进程
try:
pf = file(self.pidfile,'r')
pid = int(pf.read().strip())
pf.close()
except IOError as e:
pid = None
if pid:
message = 'pidfile %s already exist. Daemon already running!\n'
sys.stderr.write(message%self.pidfile)
sys.exit(1)
# 启动监控
self._daemonize()
self.run()
def stop(self):
# 从pid文件中获取pid
try:
pf = file(self.pidfile,'r')
pid = int(pf.read().strip())
pf.close()
except IOError as e:
pid = None
if not pid: # 重启不报错
message = 'pidfile %s does not exist. Daemon not running!\n'
sys.stderr.write(message%self.pidfile)
return
# 杀进程
try:
while 1:
os.kill(pid, SIGTERM)
time.sleep(0.1)
except OSError as err:
err = str(err)
if err.find('No such process') > 0:
if os.path.exists(self.pidfile):
os.remove(self.pidfile)
else:
print(str(err))
sys.exit(1)
def restart(self):
self.stop()
self.start()
def run(self):
""" run your function"""
while True:
sys.stdout.write('%s:hello world\n' % (time.ctime(),))
sys.stdout.flush()
time.sleep(2)
if __name__ == '__main__':
daemon = Daemon('/tmp/watch_process.pid', stdout = '/tmp/watch_stdout.log')
if len(sys.argv) == 2:
if 'start' == sys.argv[1]:
daemon.start()
elif 'stop' == sys.argv[1]:
daemon.stop()
elif 'restart' == sys.argv[1]:
daemon.restart()
else:
print('unknown command')
sys.exit(2)
sys.exit(0)
else:
print('usage: %s start|stop|restart'% sys.argv[0])
sys.exit(2)
3.6 shell多任务
shell中并没有真正意义的多线程,要实现多线程可以启动多个后端进程,最大程度利用cpu性能。
- 顺序执行代码
date
for i in `seq 1 5`
do { echo "sleep 5"; sleep 5; } done
date
输出结果:
2018年11月27日 星期二 17时59分04秒 CST
...
2018年11月27日 星期二 17时59分29秒 CST
- 并行执行代码
date
for i in `seq 1 5`
do { echo "sleep 5"; sleep 5; } & done
wait # 等待所有子后台进程结束
date
输出结果:
2018年11月27日 星期二 18时02分46秒 CST
...
2018年11月27日 星期二 18时02分51秒 CST
- 数量可控并行处理代码(命名管道(fifo))
linux管道
在Unix或类Unix操作系统中,管道是一个由标准输入输出链接起来的进程集合,因此每一个进程的输出将直接作为下一个进程的输入。linux管道包含两种:匿名管道和命名管道。
管道有一个特点,如果管道中没有数据,那么取管道数据的操作就会滞留,直到管道内进入数据,然后读出后才会终止这一操作;同理,写入管道的操作如果没有读取管道的操作,这一动作就会滞留。
匿名管道: 在Unix或类Unix操作系统的命令行中,匿名管道使用ASCII中垂直线|作为匿名管道符,匿名管道的两端是两个普通的,匿名的,打开的文件描述符:一个只读端和一个只写端,这就让其它进程无法连接到该匿名管道。如:cat file | less
为了执行上面的指令,shell创建了两个进程来分别执行cat和less。下图展示了这两个进程是如何使用管道的:

有一点值得注意的是两个进程都连接到了管道上,这样写入进程cat就将其标准输出(文件描述符为fd 1)连接到了管道的写入端,读取进程less就将其标准输入(文件描述符为fd 0)连接到了管道的读入端。实际上,这两个进程并不知道管道的存在,它们只是从标准文件描述符中读取数据和写入数据。shell必须要完成相关的工作。
命名管道(FIFO,First In First Out): 命名管道也称FIFO,从语义上来讲,FIFO其实与匿名管道类似,但值得注意:
- 在文件系统中,FIFO拥有名称,并且是以设备特俗文件的形式存在的;
- 任何进程都可以通过FIFO共享数据;
- 除非FIFO两端同时有读与写的进程,否则FIFO的数据流通将会阻塞;
- 匿名管道是由shell自动创建的,存在于内核中;而FIFO则是由程序创建的(比如mkfifo命令),存在于文件系统中;
- 匿名管道是单向的字节流,而FIFO则是双向的字节流;
比如可以利用FIFO实现单服务器、多客户端的应用程序:

多任务shell代码样例:
function my_cmd(){
echo "sleep 5 s"
sleep 5
}
tmp_fifofile="/tmp/$$.fifo"
mkfifo $tmp_fifofile # 新建一个fifo类型的文件
exec 6<>$tmp_fifofile # 将fd6指向fifo类型
rm $tmp_fifofile # 删也可以
thread_num=6 # 最大可同时执行线程数量
# 根据线程总数量设置令牌个数
for ((i=0;i<${thread_num};i++));do
echo
done >&6 # 事实上就是在fd6中放置了$thread个回车符
job_num=12 # 任务总数
for ((i=0;i<${job_num};i++));do # 任务数量
# 一个read -u6命令执行一次,就从fd6中减去一个回车符,然后向下执行,
# fd6中没有回车符的时候,就停在这了,从而实现了线程数量控制
read -u6
# 可以把具体的需要执行的命令封装成一个函数
{
my_cmd # 自己的命令
echo >&6 # 当进程结束以后,再向fd6中加上一个回车符,即补上了read -u6减去的那个
} &
done
wait # 等待所有的后台子进程结束
exec 6>&- # 关闭fd6
echo "over"
四、代码片段
4.1 PyTorch Cookbook
引用的包:
import collections
import os
import shutil
import tqdm
import numpy as np
import PIL.Image
import torch
import torchvision
- 基础配置
检查PyTorch版本
torch.__version__ # PyTorch version
torch.version.cuda # Corresponding CUDA version
torch.backends.cudnn.version() # Corresponding cuDNN version
torch.cuda.get_device_name(0) # GPU type
固定随机种子
torch.manual_seed(0)
torch.cuda.manual_seed_all(0)
指定程序运行在特定GPU卡上
在命令行指定环境变量
CUDA_VISIBLE_DEVICES=0,1 python train.py
或在代码中指定
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1'
判断是否有CUDA支持
torch.cuda.is_available()
设置为cuDNN benchmark模式
Benchmark模式会提升计算速度,但是由于计算中有随机性,每次网络前馈结果略有差异。
torch.backends.cudnn.benchmark = True
如果想要避免这种结果波动,设置
torch.backends.cudnn.deterministic = True
清除GPU存储
有时Control-C中止运行后GPU存储没有及时释放,需要手动清空。在PyTorch内部可以
torch.cuda.empty_cache()
或在命令行可以先使用ps找到程序的PID,再使用kill结束该进程
ps aux | grep python
kill -9 [pid]
或者直接重置没有被清空的GPU
nvidia-smi --gpu-reset -i [gpu_id]
- 张量处理
张量基本信息
tensor.type() # Data type
tensor.size() # Shape of the tensor. It is a subclass of Python tuple
tensor.dim() # Number of dimensions.
数据类型转换
# Set default tensor type. Float in PyTorch is much faster than double.
torch.set_default_tensor_type(torch.FloatTensor)
# Type convertions.
tensor = tensor.cuda()
tensor = tensor.cpu()
tensor = tensor.float()
tensor = tensor.long()
torch.Tensor与np.ndarray转换
# torch.Tensor -> np.ndarray.
ndarray = tensor.cpu().numpy()
# np.ndarray -> torch.Tensor.
tensor = torch.from_numpy(ndarray).float()
tensor = torch.from_numpy(ndarray.copy()).float() # If ndarray has negative stride
torch.Tensor与PIL.Image转换
PyTorch中的张量默认采用N×D×H×W的顺序,并且数据范围在[0,1],需要进行转置和规范化。
# torch.Tensor -> PIL.Image.
image = PIL.Image.fromarray(torch.clamp(tensor * 255, min=0, max=255
).byte().permute(1, 2, 0).cpu().numpy())
image = torchvision.transforms.functional.to_pil_image(tensor) # Equivalently way
# PIL.Image -> torch.Tensor.
tensor = torch.from_numpy(np.asarray(PIL.Image.open(path))
).permute(2, 0, 1).float() / 255
tensor = torchvision.transforms.functional.to_tensor(PIL.Image.open(path)) # Equivalently way
np.ndarray与PIL.Image转换
# np.ndarray -> PIL.Image.
image = PIL.Image.fromarray(ndarray.astypde(np.uint8))
# PIL.Image -> np.ndarray.
ndarray = np.asarray(PIL.Image.open(path))
从只包含一个元素的张量中提取值
这在训练时统计loss的变化过程中特别有用。否则这将累积计算图,使GPU存储占用量越来越大。
value = tensor.item()
张量形变
张量形变常常需要用于将卷积层特征输入全连接层的情形。相比torch.view,torch.reshape可以自动处理输入张量不连续的情况。
tensor = torch.reshape(tensor, shape)
打乱顺序
tensor = tensor[torch.randperm(tensor.size(0))] # Shuffle the first dimension
水平翻转
PyTorch不支持tensor[::-1]这样的负步长操作,水平翻转可以用张量索引实现。
# Assume tensor has shape N*D*H*W.
tensor = tensor[:, :, :, torch.arange(tensor.size(3) - 1, -1, -1).long()]
复制张量
有三种复制的方式,对应不同的需求。
Operation |
New/Shared memory |
Still in computation graph |
|---|---|---|
tensor.clone() |
New |
Yes |
tensor.detach() |
Shared |
No |
tensor.detach.clone() |
New |
No |
拼接张量
注意torch.cat和torch.stack的区别在于torch.cat沿着给定的维度拼接,而torch.stack会新增一维。例如当参数是3个10×5的张量,torch.cat的结果是30×5的张量,而torch.stack的结果是3×10×5的张量。
tensor = torch.cat(list_of_tensors, dim=0)
tensor = torch.stack(list_of_tensors, dim=0)
将整数标记转换成独热(one-hot)编码
PyTorch中的标记默认从0开始。
N = tensor.size(0)
one_hot = torch.zeros(N, num_classes).long()
one_hot.scatter_(dim=1, index=torch.unsqueeze(tensor, dim=1), src=torch.ones(N, num_classes).long())
得到非零/零元素
torch.nonzero(tensor) # Index of non-zero elements
torch.nonzero(tensor == 0) # Index of zero elements
torch.nonzero(tensor).size(0) # Number of non-zero elements
torch.nonzero(tensor == 0).size(0) # Number of zero elements
判断两个张量相等
torch.allclose(tensor1, tensor2) # float tensor
torch.equal(tensor1, tensor2) # int tensor
张量扩展
# Expand tensor of shape 64*512 to shape 64*512*7*7.
torch.reshape(tensor, (64, 512, 1, 1)).expand(64, 512, 7, 7)
矩阵乘法
# Matrix multiplication: (m*n) * (n*p) -> (m*p).
result = torch.mm(tensor1, tensor2)
# Batch matrix multiplication: (b*m*n) * (b*n*p) -> (b*m*p).
result = torch.bmm(tensor1, tensor2)
# Element-wise multiplication.
result = tensor1 * tensor2
计算两组数据之间的两两欧式距离
# X1 is of shape m*d, X2 is of shape n*d.
dist = torch.sqrt(torch.sum((X1[:,None,:] - X2) ** 2, dim=2))
- 模型定义
卷积层
最常用的卷积层配置是
conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True)
conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=True)
如果卷积层配置比较复杂,不方便计算输出大小时,可以利用可视化工具辅助
GAP(Global average pooling)层
gap = torch.nn.AdaptiveAvgPool2d(output_size=1)
双线性汇合(bilinear pooling)
X = torch.reshape(N, D, H * W) # Assume X has shape N*D*H*W
X = torch.bmm(X, torch.transpose(X, 1, 2)) / (H * W) # Bilinear pooling
assert X.size() == (N, D, D)
X = torch.reshape(X, (N, D * D))
X = torch.sign(X) * torch.sqrt(torch.abs(X) + 1e-5) # Signed-sqrt normalization
X = torch.nn.functional.normalize(X) # L2 normalization
多卡同步BN(Batch normalization)
当使用torch.nn.DataParallel将代码运行在多张GPU卡上时,PyTorch的BN层默认操作是各卡上数据独立地计算均值和标准差,同步BN使用所有卡上的数据一起计算BN层的均值和标准差,缓解了当批量大小(batch size)比较小时对均值和标准差估计不准的情况,是在目标检测等任务中一个有效的提升性能的技巧。
现在PyTorch官方已经支持同步BN操作
sync_bn = torch.nn.SyncBatchNorm(num_features, eps=1e-05, momentum=0.1, affine=True,
track_running_stats=True)
将已有网络的所有BN层改为同步BN层
def convertBNtoSyncBN(module, process_group=None):
'''Recursively replace all BN layers to SyncBN layer.
Args:
module[torch.nn.Module]. Network
'''
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
sync_bn = torch.nn.SyncBatchNorm(module.num_features, module.eps, module.momentum,
module.affine, module.track_running_stats, process_group)
sync_bn.running_mean = module.running_mean
sync_bn.running_var = module.running_var
if module.affine:
sync_bn.weight = module.weight.clone().detach()
sync_bn.bias = module.bias.clone().detach()
return sync_bn
else:
for name, child_module in module.named_children():
setattr(module, name) = convert_syncbn_model(child_module, process_group=process_group))
return module
类似BN滑动平均
如果要实现类似BN滑动平均的操作,在forward函数中要使用原地(inplace)操作给滑动平均赋值。
class BN(torch.nn.Module)
def __init__(self):
...
self.register_buffer('running_mean', torch.zeros(num_features))
def forward(self, X):
...
self.running_mean += momentum * (current - self.running_mean)
计算模型整体参数量
num_parameters = sum(torch.numel(parameter) for parameter in model.parameters())
类似Keras的model.summary()输出模型信息
模型权值初始化
注意model.modules()和model.children()的区别:model.modules()会迭代地遍历模型的所有子层,而model.children()只会遍历模型下的一层。
# Common practise for initialization.
for layer in model.modules():
if isinstance(layer, torch.nn.Conv2d):
torch.nn.init.kaiming_normal_(layer.weight, mode='fan_out',
nonlinearity='relu')
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.BatchNorm2d):
torch.nn.init.constant_(layer.weight, val=1.0)
torch.nn.init.constant_(layer.bias, val=0.0)
elif isinstance(layer, torch.nn.Linear):
torch.nn.init.xavier_normal_(layer.weight)
if layer.bias is not None:
torch.nn.init.constant_(layer.bias, val=0.0)
# Initialization with given tensor.
layer.weight = torch.nn.Parameter(tensor)
部分层使用预训练模型
注意如果保存的模型是torch.nn.DataParallel,则当前的模型也需要是torch.nn.DataParallel。torch.nn.DataParallel(model).module == model。
model.load_state_dict(torch.load('model,pth'), strict=False)
将在GPU保存的模型加载到CPU
model.load_state_dict(torch.load('model,pth', map_location='cpu'))
- 数据准备、特征提取与微调
图像分块打散(image shuffle)/区域混淆机制(region confusion mechanism,RCM)
# X is torch.Tensor of size N*D*H*W.
# Shuffle rows
Q = (torch.unsqueeze(torch.arange(num_blocks), dim=1) * torch.ones(1, num_blocks).long()
+ torch.randint(low=-neighbour, high=neighbour, size=(num_blocks, num_blocks)))
Q = torch.argsort(Q, dim=0)
assert Q.size() == (num_blocks, num_blocks)
X = [torch.chunk(row, chunks=num_blocks, dim=2)
for row in torch.chunk(X, chunks=num_blocks, dim=1)]
X = [[X[Q[i, j].item()][j] for j in range(num_blocks)]
for i in range(num_blocks)]
# Shulle columns.
Q = (torch.ones(num_blocks, 1).long() * torch.unsqueeze(torch.arange(num_blocks), dim=0)
+ torch.randint(low=-neighbour, high=neighbour, size=(num_blocks, num_blocks)))
Q = torch.argsort(Q, dim=1)
assert Q.size() == (num_blocks, num_blocks)
X = [[X[i][Q[i, j].item()] for j in range(num_blocks)]
for i in range(num_blocks)]
Y = torch.cat([torch.cat(row, dim=2) for row in X], dim=1)
得到视频数据基本信息
import cv2
video = cv2.VideoCapture(mp4_path)
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
fps = int(video.get(cv2.CAP_PROP_FPS))
video.release()
TSN每段(segment)采样一帧视频
K = self._num_segments
if is_train:
if num_frames > K:
# Random index for each segment.
frame_indices = torch.randint(
high=num_frames // K, size=(K,), dtype=torch.long)
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.randint(
high=num_frames, size=(K - num_frames,), dtype=torch.long)
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), frame_indices)))[0]
else:
if num_frames > K:
# Middle index for each segment.
frame_indices = num_frames / K // 2
frame_indices += num_frames // K * torch.arange(K)
else:
frame_indices = torch.sort(torch.cat((
torch.arange(num_frames), torch.arange(K - num_frames))))[0]
assert frame_indices.size() == (K,)
return [frame_indices[i] for i in range(K)]
提取ImageNet预训练模型某层的卷积特征
# VGG-16 relu5-3 feature.
model = torchvision.models.vgg16(pretrained=True).features[:-1]
# VGG-16 pool5 feature.
model = torchvision.models.vgg16(pretrained=True).features
# VGG-16 fc7 feature.
model = torchvision.models.vgg16(pretrained=True)
model.classifier = torch.nn.Sequential(*list(model.classifier.children())[:-3])
# ResNet GAP feature.
model = torchvision.models.resnet18(pretrained=True)
model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
with torch.no_grad():
model.eval()
conv_representation = model(image)
提取ImageNet预训练模型多层的卷积特征
class FeatureExtractor(torch.nn.Module):
"""Helper class to extract several convolution features from the given
pre-trained model.
Attributes:
_model, torch.nn.Module.
_layers_to_extract, list<str> or set<str>
Example:
>>> model = torchvision.models.resnet152(pretrained=True)
>>> model = torch.nn.Sequential(collections.OrderedDict(
list(model.named_children())[:-1]))
>>> conv_representation = FeatureExtractor(
pretrained_model=model,
layers_to_extract={'layer1', 'layer2', 'layer3', 'layer4'})(image)
"""
def __init__(self, pretrained_model, layers_to_extract):
torch.nn.Module.__init__(self)
self._model = pretrained_model
self._model.eval()
self._layers_to_extract = set(layers_to_extract)
def forward(self, x):
with torch.no_grad():
conv_representation = []
for name, layer in self._model.named_children():
x = layer(x)
if name in self._layers_to_extract:
conv_representation.append(x)
return conv_representation
微调全连接层
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Linear(512, 100) # Replace the last fc layer
optimizer = torch.optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9, weight_decay=1e-4)
以较大学习率微调全连接层,较小学习率微调卷积层
model = torchvision.models.resnet18(pretrained=True)
finetuned_parameters = list(map(id, model.fc.parameters()))
conv_parameters = (p for p in model.parameters() if id(p) not in finetuned_parameters)
parameters = [{'params': conv_parameters, 'lr': 1e-3},
{'params': model.fc.parameters()}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
- 模型训练
常用训练和验证数据预处理
其中ToTensor操作会将PIL.Image或形状为H×W×D,数值范围为[0, 255]的np.ndarray转换为形状为D×H×W,数值范围为[0.0, 1.0]的torch.Tensor。
train_transform = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(size=224,
scale=(0.08, 1.0)),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
val_transform = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225)),
])
训练基本代码框架
for t in epoch(80):
for images, labels in tqdm.tqdm(train_loader, desc='Epoch %3d' % (t + 1)):
images, labels = images.cuda(), labels.cuda()
scores = model(images)
loss = loss_function(scores, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
标记平滑(label smoothing)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value=0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
score = model(images)
log_prob = torch.nn.functional.log_softmax(score, dim=1)
loss = -torch.sum(log_prob * smoothed_labels) / N
optimizer.zero_grad()
loss.backward()
optimizer.step()
Mixup
beta_distribution = torch.distributions.beta.Beta(alpha, alpha)
for images, labels in train_loader:
images, labels = images.cuda(), labels.cuda()
# Mixup images.
lambda_ = beta_distribution.sample([]).item()
index = torch.randperm(images.size(0)).cuda()
mixed_images = lambda_ * images + (1 - lambda_) * images[index, :]
# Mixup loss.
scores = model(mixed_images)
loss = (lambda_ * loss_function(scores, labels)
+ (1 - lambda_) * loss_function(scores, labels[index]))
optimizer.zero_grad()
loss.backward()
optimizer.step()
L1正则化
l1_regularization = torch.nn.L1Loss(reduction='sum')
loss = ... # Standard cross-entropy loss
for param in model.parameters():
loss += lambda_ * torch.sum(torch.abs(param))
loss.backward()
不对偏置项进行L2正则化/权值衰减(weight decay)
bias_list = (param for name, param in model.named_parameters() if name[-4:] == 'bias')
others_list = (param for name, param in model.named_parameters() if name[-4:] != 'bias')
parameters = [{'parameters': bias_list, 'weight_decay': 0},
{'parameters': others_list}]
optimizer = torch.optim.SGD(parameters, lr=1e-2, momentum=0.9, weight_decay=1e-4)
梯度裁剪(gradient clipping)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=20)
计算Softmax输出的准确率
score = model(images)
prediction = torch.argmax(score, dim=1)
num_correct = torch.sum(prediction == labels).item()
accuruacy = num_correct / labels.size(0)
可视化学习曲线
有Facebook自己开发的Visdom和Tensorboard(仍处于实验阶段)两个选择。
# Example using Visdom.
vis = visdom.Visdom(env='Learning curve', use_incoming_socket=False)
assert self._visdom.check_connection()
self._visdom.close()
options = collections.namedtuple('Options', ['loss', 'acc', 'lr'])(
loss={'xlabel': 'Epoch', 'ylabel': 'Loss', 'showlegend': True},
acc={'xlabel': 'Epoch', 'ylabel': 'Accuracy', 'showlegend': True},
lr={'xlabel': 'Epoch', 'ylabel': 'Learning rate', 'showlegend': True})
for t in epoch(80):
tran(...)
val(...)
vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([train_loss]),
name='train', win='Loss', update='append', opts=options.loss)
vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([val_loss]),
name='val', win='Loss', update='append', opts=options.loss)
vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([train_acc]),
name='train', win='Accuracy', update='append', opts=options.acc)
vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([val_acc]),
name='val', win='Accuracy', update='append', opts=options.acc)
vis.line(X=torch.Tensor([t + 1]), Y=torch.Tensor([lr]),
win='Learning rate', update='append', opts=options.lr)
得到当前学习率
# If there is one global learning rate (which is the common case).
lr = next(iter(optimizer.param_groups))['lr']
# If there are multiple learning rates for different layers.
all_lr = []
for param_group in optimizer.param_groups:
all_lr.append(param_group['lr'])
学习率衰减
# Reduce learning rate when validation accuarcy plateau.
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', patience=5, verbose=True)
for t in range(0, 80):
train(...); val(...)
scheduler.step(val_acc)
# Cosine annealing learning rate.
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=80)
# Reduce learning rate by 10 at given epochs.
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[50, 70], gamma=0.1)
for t in range(0, 80):
scheduler.step()
train(...); val(...)
# Learning rate warmup by 10 epochs.
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda t: t / 10)
for t in range(0, 10):
scheduler.step()
train(...); val(...)
保存与加载断点
注意为了能够恢复训练,我们需要同时保存模型和优化器的状态,以及当前的训练轮数。
# Save checkpoint.
is_best = current_acc > best_acc
best_acc = max(best_acc, current_acc)
checkpoint = {
'best_acc': best_acc,
'epoch': t + 1,
'model': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
model_path = os.path.join('model', 'checkpoint.pth.tar')
torch.save(checkpoint, model_path)
if is_best:
shutil.copy('checkpoint.pth.tar', model_path)
# Load checkpoint.
if resume:
model_path = os.path.join('model', 'checkpoint.pth.tar')
assert os.path.isfile(model_path)
checkpoint = torch.load(model_path)
best_acc = checkpoint['best_acc']
start_epoch = checkpoint['epoch']
model.load_state_dict(checkpoint['model'])
optimizer.load_state_dict(checkpoint['optimizer'])
print('Load checkpoint at epoch %d.' % start_epoch)
计算准确率/查准率(precision)/查全率(recall)
# data['label'] and data['prediction'] are groundtruth label and prediction
# for each image, respectively.
accuracy = np.mean(data['label'] == data['prediction']) * 100
# Compute recision and recall for each class.
for c in range(len(num_classes)):
tp = np.dot((data['label'] == c).astype(int),
(data['prediction'] == c).astype(int))
tp_fp = np.sum(data['prediction'] == c)
tp_fn = np.sum(data['label'] == c)
precision = tp / tp_fp * 100
recall = tp / tp_fn * 100
- 模型测试
计算每个类别的查准率(precision)、查全率(recall)、F1和总体指标
import sklearn.metrics
all_label = []
all_prediction = []
for images, labels in tqdm.tqdm(data_loader):
# Data.
images, labels = images.cuda(), labels.cuda()
# Forward pass.
score = model(images)
# Save label and predictions.
prediction = torch.argmax(score, dim=1)
all_label.append(labels.cpu().numpy())
all_prediction.append(prediction.cpu().numpy())
# Compute RP and confusion matrix.
all_label = np.concatenate(all_label)
assert len(all_label.shape) == 1
all_prediction = np.concatenate(all_prediction)
assert all_label.shape == all_prediction.shape
micro_p, micro_r, micro_f1, _ = sklearn.metrics.precision_recall_fscore_support(
all_label, all_prediction, average='micro', labels=range(num_classes))
class_p, class_r, class_f1, class_occurence = sklearn.metrics.precision_recall_fscore_support(
all_label, all_prediction, average=None, labels=range(num_classes))
# Ci,j = #{y=i and hat_y=j}
confusion_mat = sklearn.metrics.confusion_matrix(
all_label, all_prediction, labels=range(num_classes))
assert confusion_mat.shape == (num_classes, num_classes)
将各类结果写入电子表格
import csv
# Write results onto disk.
with open(os.path.join(path, filename), 'wt', encoding='utf-8') as f:
f = csv.writer(f)
f.writerow(['Class', 'Label', '# occurence', 'Precision', 'Recall', 'F1',
'Confused class 1', 'Confused class 2', 'Confused class 3',
'Confused 4', 'Confused class 5'])
for c in range(num_classes):
index = np.argsort(confusion_mat[:, c])[::-1][:5]
f.writerow([
label2class[c], c, class_occurence[c], '%4.3f' % class_p[c],
'%4.3f' % class_r[c], '%4.3f' % class_f1[c],
'%s:%d' % (label2class[index[0]], confusion_mat[index[0], c]),
'%s:%d' % (label2class[index[1]], confusion_mat[index[1], c]),
'%s:%d' % (label2class[index[2]], confusion_mat[index[2], c]),
'%s:%d' % (label2class[index[3]], confusion_mat[index[3], c]),
'%s:%d' % (label2class[index[4]], confusion_mat[index[4], c])])
f.writerow(['All', '', np.sum(class_occurence), micro_p, micro_r, micro_f1,
'', '', '', '', ''])
- 加载数据
torch.utils.data.Dataset
torch.utils.data.Dataset是一个抽象类,自定义的Dataset需要继承它并且实现两个成员方法:__getitem__()和__len__(),第一个最为重要,即每次怎么读数据.以图片为例:
def __getitem__(self, index):
img_path, label = self.data[index].img_path, self.data[index].label
img = Image.open(img_path)
return img, label
值得一提的是,pytorch还提供了很多常用的transform,在torchvision.transforms里面,在这里建议在__getitem__()里面用PIL来读图片,而不是用skimage.io.
第二个比较简单,就是返回整个数据集的长度:
def __len__(self):
return len(self.data)
复杂的例子:
class MLDataInstance(data.Dataset):
# Metric Learning Dataset.
def __init__(self, src_dir, dataset_name, train = True, transform=None, target_transform=None, nnIndex = None):
data_dir = src_dir + dataset_name + '/'
if train:
img_data = np.load(data_dir + '{}_{}_256resized_img.npy'.format('training',dataset_name))
img_label = np.load(data_dir + '{}_{}_256resized_label.npy'.format('training',dataset_name))
else:
img_data = np.load(data_dir + '{}_{}_256resized_img.npy'.format('validation',dataset_name))
img_label = np.load(data_dir + '{}_{}_256resized_label.npy'.format('validation',dataset_name))
self.img_data = img_data
self.img_label = img_label
self.transform = transform
self.target_transform = target_transform
self.nnIndex = nnIndex
def __getitem__(self, index):
if self.nnIndex is not None:
img1, img2, target = self.img_data[index], self.img_data[self.nnIndex[index]], self.img_label[index]
img1 = self.transform(img1)
img2 = self.transform(img2)
if self.target_transform is not None:
target = self.target_transform(target)
return img1, img2, target, index
else:
img, target = self.img_data[index], self.img_label[index]
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target, index
def __len__(self):
return len(self.img_data)
torch.utils.data.DataLoader
类定义为:class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=<function default_collate>, pin_memory=False, drop_last=False),可以看到, 主要参数有这么几个:
dataset:即上面自定义的dataset.
collate_fn: 这个函数用来打包batch,后面详细讲.
num_worker:非常简单的多线程方法, 只要设置为>=1,就可以多线程预读数据啦.
这个类其实就是下面将要讲的DataLoaderIter的一个框架,一共干了两件事:
- 定义了一堆成员变量,到时候赋给
DataLoaderIter- 然后有一个
__iter__()函数,把自己"装进"DataLoaderIter里面.
def __iter__(self):
return DataLoaderIter(self)
torch.utils.data.dataloader.DataLoaderIter
上面提到,DataLoaderIter就是DataLoaderIter的一个框架,用来传给DataLoaderIter一堆参数,并把自己装进DataLoaderIter里.其实到这里就可以满足大多数训练的需求了, 比如
class CustomDataset(Dataset):
# 自定义自己的dataset
dataset = CustomDataset()
dataloader = Dataloader(dataset, ...)
for data in dataloader:
# training...
在for循环里,总共有三点操作:
调用了
dataloader的__iter__()方法,产生了一个DataLoaderIter反复调用
DataLoaderIter的__next__()来得到batch,具体操作就是,多次调用dataset的__getitem__()方法(如果num_worker>0就多线程调用),然后用collate_fn来把它们打包成batch.中间还会涉及到shuffle,以及sample的方法等,这里就不多说了.当数据读完后,
__next__()抛出一个StopIteration异常,for循环结束,dataloader失效.
仅供参考一个封装:
class DataProvider:
def __init__(self, batch_size, is_cuda):
self.batch_size = batch_size
self.dataset = Dataset_triple(self.batch_size,
transform_=transforms.Compose(
[transforms.Scale([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])]),
)
self.is_cuda = is_cuda # 是否将batch放到gpu上
self.dataiter = None
self.iteration = 0 # 当前epoch的batch数
self.epoch = 0 # 统计训练了多少个epoch
def build(self):
dataloader = DataLoader(self.dataset, batch_size=self.batch_size, shuffle=True, num_workers=0, drop_last=True)
self.dataiter = DataLoaderIter(dataloader)
def next(self):
if self.dataiter is None:
self.build()
try:
batch = self.dataiter.next()
self.iteration += 1
if self.is_cuda:
batch = [batch[0].cuda(), batch[1].cuda(), batch[2].cuda()]
return batch
except StopIteration: # 一个epoch结束后reload
self.epoch += 1
self.build()
self.iteration = 1 # reset and return the 1st batch
batch = self.dataiter.next()
if self.is_cuda:
batch = [batch[0].cuda(), batch[1].cuda(), batch[2].cuda()]
return batch
- 训练模型代码
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
def test(args, model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
kwargs = {'num_workers': 1, 'pin_memory': True} if use_cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(args, model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
if __name__ == '__main__':
main()