C/C++基础教程
一、基本知识
1.1 预定义宏
- 宏定义
C语言中用到宏定义的地方很多,如在头文件中为了防止头文件被重复包含,则用到:
#ifndef cTest_Header_h
#define cTest_Header_h
// 头文件内容
#endif
在我们常用的stdio.h头文件中也可以见到很多宏定义,如:
#define BUFSIZ 1024 // 缓冲区大小
#define EOF (-1) // 表文件末尾
#ifndef SEEK_SET
#define SEEK_SET 0 // 表示文件指针从文件的开头开始
#endif
#ifndef SEEK_CUR
#define SEEK_CUR 1 // 表示文件指针从现在的位置开始
#endif
#ifndef SEEK_END
#define SEEK_END 2 // 表示文件指针从文件的末尾开始
#endif
从开始写C语言到生成执行程序的流程大致如下(姑且忽略预处理之前的编译器的翻译处理流程等),在进行编译的第一次扫描(词法扫描和语法分析)之前,会有由预处理程序负责完成的预处理工作。
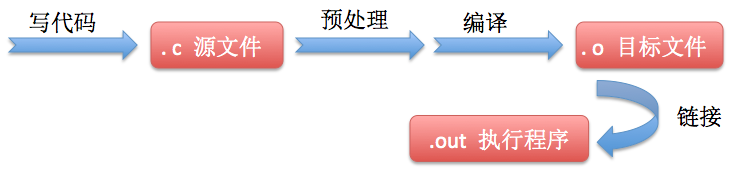
预处理工作是系统引用预处理程序对源程序中的预处理部分做处理,而预处理部分是指以"#"开头的、放在函数之外的、一般放在源文件的前面的预处理命令,如:包括命令#include,宏命令#define等,合理地利用预处理功能可以使得程序更加方便地阅读、修改、移植、调试等,也有利于模块化程序设计。本文主要介绍宏定义的以下几个部分:
- 概念及无参宏
一种最简单的宏的形式如下:#define 宏名 替换文本
每个#define行(即逻辑行)由三部分组成:第一部分是指令#define自身,"#"表示这是一条预处理命令,"define"为宏命令。第二部分为宏(macro),一般为缩略语,其名称(宏名)一般大写,而且不能有空格,遵循C变量命令规则。"替换文本"可以是任意常数、表达式、字符串等。在预处理工作过程中,代码中所有出现的"宏名",都会被"替换文本"替换。这个替换的过程被称为"宏代换"或"宏展开"(macroexpansion)。"宏代换"是由预处理程序自动完成的。在C语言中,"宏"分为两种:无参数和有参数。
无参宏是指宏名之后不带参数,上面最简单的宏就是无参宏。
#define M 5 // 宏定义
#define PI 3.14 // 宏定义
int a[M]; // 会被替换为: int a[5];
int b = M; // 会被替换为: int b = 5;
printf("PI = %.2f\n", PI); // 输出结果为: PI = 3.14
注意宏不是语句,结尾不需要加";",否则会被替换进程序中,如:
#define N 10; // 宏定义
int c[N]; // 会被替换为: int c[10;];
//error:… main.c:133:11: Expected ']'
以上几个宏都是用来代表值,所以被成为类对象宏(object-like macro,还有类函数宏。如果要写宏不止一行,则在结尾加反斜线符号使得多行能连接上,如:
#define HELLO "hello \
the world"
注意第二行要对齐,否则,如:
#define HELLO "hello the wo\
rld"
printf("HELLO is %s\n", HELLO);
// 输出结果为: HELLO is hello the wo rld
也就是行与行之间的空格也会被作为替换文本的一部分,而且由这个例子也可以看出:宏名如果出现在源程序中的""内,则不会被当做宏来进行宏代换。宏可以嵌套,但不参与运算:
#define M 5 // 宏定义
#define MM M * M // 宏的嵌套
printf("MM = %d\n", MM); // MM 被替换为: MM = M * M, 然后又变成 MM = 5 * 5
宏代换的过程在上句已经结束,实际的5*5相乘过程则在编译阶段完成,而不是在预处理器工作阶段完成,所以宏不进行运算,它只是按照指令进行文字的替换操作。再强调下,宏进行简单的文本替换,无论替换文本中是常数、表达式或者字符串等,预处理程序都不做任何检查,如果出现错误,只能是被宏代换之后的程序在编译阶段发现。
宏定义必须写在函数之外,其作用域是#define开始,到源程序结束。如果要提前结束它的作用域则用#undef命令,如:
#define M 5 // 宏定义
printf("M = %d\n", M); // 输出结果为: M = 5
#define M 100 // 取消宏定义
printf("M = %d\n", M); // error:… main.c:138:24: Use of undeclared identifier 'M'
也可以用宏定义表示数据类型,可以使代码简便:
#define STU struct Student // 宏定义STU
struct Student{ // 定义结构体Student
char *name;
int sNo;
};
STU stu = {"Jack", 20}; // 被替换为:struct Student stu = {"Jack", 20};
printf("name: %s, sNo: %d\n", stu.name, stu.sNo);
如果重复定义宏,则不同的编译器采用不同的重定义策略。有的编译器认为这是错误的,有的则只是提示警告。Xcode中采用第二种方式。如:
#define M 5 // 宏定义
#define M 100 // 重定义,warning:… main.c:26:9: 'M' macro redefined
这些简单的宏主要被用来定义那些显式常量(Manifest Constants)(Stephen Prata,2004),而且会使得程序更加容易修改,特别是某一常量的值在程序中多次被用到的时候,只需要改动一个宏定义,则程序中所有出现该变量的值都可以被改变。而且宏定义还有更多其他优点,如使得程序更容易理解,可以控制条件编译等。
#define与typedef的区别:
两者都可以用来表示数据类型,如:
#define INT1 int
typedef int INT2;
两者是等效的,调用也一样:
INT1 a1 = 3;
INT2 a2 = 5;
但当如下使用时,问题就来了:
#define INT1 int *
typedef int * INT2;
INT1 a1, b1;
INT2 a2, b2;
b1 = &m; // ... main.c:185:8: Incompatible pointer to integer conversion assigning to 'int' from 'int *'; remove &
b2 = &n; // OK
因为INT1 a1, b1;被宏代换后为:int * a1, b1;即定义的是一个指向int型变量的指针a1和一个int型的变量b1.而INT2 a2, b2;表示定义的是两个变量a2和b2,这两个变量的类型都是INT2的,也就是int *的,所以两个都是指向int型变量的指针。所以两者区别在于,宏定义只是简单的字符串代换,在预处理阶段完成。而typedef不是简单的字符串代换,而是可以用来做类型说明符的重命名的,类型的别名可以具有类型定义说明的功能,在编译阶段完成的。
- 有参宏
C语言中宏是可以有参数的,这样的宏就成了外形与函数相似的类函数宏(function-like macro),如:
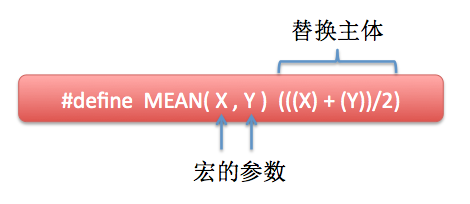
宏调用:宏名(实参表);
printf("MEAN = %d\n", MEAN(7, 9)); // 输出结果: MEAN = 8
和函数类似,在宏定义中的参数成为形式参数,在宏调用中的参数成为实际参数。而且和无参宏不同的一点是,有参宏在调用中,不仅要进行宏展开,而且还要用实参去替换形参。如:
#define M 5 // 无参宏
#define COUNT(M) M * M // 有参宏
printf("COUNT = %d\n", COUNT(10)); // 替换为: COUNT(10) = 10 * 10
// 输出结果: COUNT = 100
这看上去用法与函数调用类似,但实际上是有很大差别的。如:
#define COUNT(M) M * M // 定义有参宏
int x = 6;
printf("COUNT = %d\n", COUNT(x + 1)); // 输出结果: COUNT = 13
printf("COUNT = %d\n", COUNT(++x)); // 输出结果: COUNT = 56 // warning:... main.c:161:34: Multiple unsequenced modifications to 'x'
这两个结果和调用函数的方法的结果差别很大,因为如果是像函数那样的话,COUNT(x+1)应该相当于COUNT(7),结果应该是7*7=49,但输出结果却是21。原因在于,预处理器不进行技术,只是进行字符串替换,而且也不会自动加上括号(),所以COUNT(x+1)被替换为COUNT(x+1*x+1),代入x=6,即为6+1*6+1=13。而解决办法则是:尽量用括号把整个替换文本及其中的每个参数括起来:
#define COUNT(M) ((M) * (M))
但即使用括号,也不能解决上面例子的最后一个情况,COUNT(++x)被替换为++x*++x,即为7*8=56,而不是想要7*7=49,解决办法最简单的是:不要在有参宏用使用到"++"、"–"等。
上面说到宏名中不能有空格,宏名与形参表之间也不能有空格,而形参表中形参之间可以出现空格:
#define SUM (a,b) a + b // 定义有参宏
printf("SUM = %d\n", SUM(1,2)); // 调用有参宏。Build Failed!
因为SUM被替换为:(a,b) a+b
如果用函数求一个整数的平方,则是:
int count(int x){
return x * x;
}
所以在宏定义中:#define COUNT(M) M * M中的形参不分配内存单元,所以不作类型定义。而函数int count(int x)中形参是局部变量,会在栈区分配内存单元,所以要作类型定义,而且实参与形参之间是"值传递"。而宏只是符号代换,不存在值传递。
宏定义也可以用来定义表达式或者多个语句。如:
#define JI(a,b) a = i + 3; b = j + 5; // 宏定义多个语句
int i = 5, j = 10;
int m = 0, n = 0;
JI(m, n); // 宏代换后为: m = i + 3, n = j + 5;
printf("m = %d, n = %d\n", m, n); // 输出结果为: m = 8, n = 15
#运算符
比如如果我们宏定义了:
#define SUM (a,b) ((a) + (b))
我们想要输出"1+2+3+4=10",用以下方式显得比较麻烦,有重复代码,而且中间还有括号:
printf("(%d + %d) + (%d + %d) = %d\n", 1, 2, 3, 4, SUM(1 + 2, 3+ 4));
那么这时可以考虑用#运算符来在字符串中包含宏参数,#运算符的用处就是把语言符号转化为字符串。例如,如果a是一个宏的形参,则替换文本中的#a则被系统转化为"a"。而这个转化的过程成为"字符串化(stringizing)"。用这个方法实现上面的要求:
#define SUM(a,b) printf(#a " + "#b" = %d\n",((a) + (b))) // 宏定义,运用#运算符
SUM(1 + 2, 3 + 4); // 宏调用
// 输出结果:1 + 2 + 3 + 4 = 10
调用宏时,用1+2代替a,用3+4代替b,则替换文本为:printf("1+2""+""3+4""=%d\n",((1+2)+(3+4))),接着字符串连接功能将四个相邻的字符串转换为一个字符串:
"1 + 2 + 3 + 4 = %d\n"
##运算符
和#运算符一样,##运算符也可以用在替换文本中,而它的作用是起到粘合的作用,即将两个语言符号组合成一个语言符号,所以又称为"预处理器的粘合剂(Preprocessor Glue)"。用法:
#define NAME(n) num ## n // 宏定义,使用##运算符
int num0 = 10;
printf("num0 = %d\n", NAME(0)); // 宏调用
NAME(0)被替换为num ## 0,被粘合为:num0。
- 可变宏:
…和__VA_ARGS__
我们经常要输出结果时要多次使用prinf("…", …);如果用上面例子#define SUM(a,b) printf(#a " + "#b" = %d\n",((a) + (b))),则格式比较固定,不能用于输出其他格式。这时我们可以考虑用可变宏(Variadic Macros)。用法是:
#define PR(...) printf(__VA_ARGS__) // 宏定义
PR("hello\n"); // 宏调用
// 输出结果:hello
在宏定义中,形参列表的最后一个参数为省略号"…",而"__VA_ARGS__"就可以被用在替换文本中,来表示省略号"…"代表了什么。而上面例子宏代换之后为:printf("hello\n");
还有个例子如:
#define PR2(X, ...) printf("Message"#X":"__VA_ARGS__) // 宏定义
double msg = 10;
PR2(1, "msg = %.2f\n", msg); // 宏调用
// 输出结果:Message1:msg = 10.00
在宏调用中,X的值为10,所以#X被替换为"1"。宏代换后为:
printf("Message""1"":""msg = %.2f\n", msg);
接着这4个字符串连接成一个:
printf("Message1:msg = %.2f\n", msg);
要注意的是:省略号"…"只能用来替换宏的形参列表中最后一个!
- 常见的宏
常用的标准预定义宏
| 宏 | 描述 |
|---|---|
__DATE__ |
当前前源文件的编泽日期,用"Mmm dd yyy"形式的字符串常量表示 |
__FILE__ |
当前源文件的名称,用字符串常量表示 |
__LINE__ |
当前源义件中的行号,用十进制整数常量表示,它可以随#line指令改变 |
__TIME__ |
当前源文件的最新编译吋间,用"hh:mm:ss"形式的宁符串常量表示 |
__STDC__ |
如果今前编泽器符合ISO标准,那么该宏的值为1,否则未定义 |
__STDC_VERSION__ |
如果当前编译器符合C89,那么它被定义为199409L;如果符合C99,那么它被定义为199901L:在其他情况下,该宏为宋定义 |
__STDC_HOSTED__ |
(C99)如果当前是宿主系统,则该宏的值为1;如果当前是独立系统,则该宏的值为0 |
__STDC_IEC_559_ |
(C99)如果浮点数的实现符合IEC 60559标准时,则该宏的值为1,否则为未定义 |
__STDC_IEC_559_COMPLEX__ |
(C99)如果复数运算实现符合IEC60559标准时,则该宏的伉为1,否则为未定义 |
__STDC_ISO_10646__ |
(C99)定义为长整型常量,yyyymmL表示wchai_t值遵循ISO 10646标准及其指定年月的修订补充,否则该宏为未定义 |
操作系统宏大全参见predef
OS |
MACRO |
|---|---|
linux |
linux,__linux,__linux__ |
windows |
_WIN32 |
MacOS |
macintosh |
Android |
__ANDROID__ |
gnu linux |
__gnu_linux__ |
solaris |
sun,__sun |
FreeBSD |
__FreeBSD__ |
OpenBSD |
__OpenBSD__ |
1.2 指针的概念
指针是一个特殊的变量,它里面存储的数值被解释成为内存里的一个地址。要搞清一个指针需要搞清指针的四方面的内容:指针的类型,指针所指向的类型,指针的值或者叫指针所指向的内存区,还有指针本身所占据的内存区。让我们分别说明。 先声明几个指针放着做例子:
- int p; // 这是一个普通的整型变量
- int *p; // 首先从p处开始,先与*结合,所以说明p是一个指针,然后再与int结合,说明指针所指向的内容的类型为int型.所以p是一个返回整型数据的指针
- int p[3]; // 首先从p处开始,先与[]结合,说明p是一个数组,然后与int结合,说明数组里的元素是整型的,所以p是一个由整型数据组成的数组
- int *p[3]; // 首先从p 处开始,先与[]结合,因为其优先级比*高,所以p是一个数组,然后再与*结合,说明数组里的元素是指针类型,然后再与int结合,说明指针所指向的内容的类型是整型的,所以p是一个由返回整型数据的指针所组成的数组
- int (*p)[3]; // 首先从p处开始,先与*结合,说明p是一个指针然后再与[]结合(与"()"这步可以忽略,只是为了改变优先级),说明指针所指向的内容是一个数组,然后再与int结合,说明数组里的元素是整型的.所以p是一个指向由整型数据组成的数组的指针
- int **p; // 首先从p开始,先与*结合,说是p是一个指针,然后再与*结合,说明指针所指向的元素是指针,然后再与int结合,说明该指针所指向的元素是整型数据.由于二级指针以及更高级的指针极少用在复杂的类型中,所以后面更复杂的类型我们就不考虑多级指针了,最多只考虑一级指针.
- int p(int); // 从p处起,先与()结合,说明p是一个函数,然后进入()里分析,说明该函数有一个整型变量的参数,然后再与外面的int结合,说明函数的返回值是一个整型数据
- Int (*p)(int); // 从p处开始,先与指针结合,说明p是一个指针,然后与()结合,说明指针指向的是一个函数,然后再与()里的int 结合,说明函数有一个int 型的参数,再与最外层的int结合,说明函数的返回类型是整型,所以p是一个指向有一个整型参数且返回类型为整型的函数的指针
- int (p(int))[3]; // 可以先跳过,不看这个类型,过于复杂从p开始,先与()结合,说明p是一个函数,然后进入()里面,与int 结合,说明函数有一个整型变量参数,然后再与外面的结合,说明函数返回的是一个指针,,然后到最外面一层,先与[]结合,说明返回的指针指向的是一个数组,然后再与结合,说明数组里的元素是指针,然后再与int结合,说明指针指向的内容是整型数据.所以p是一个参数为一个整数据且返回一个指向由整型指针变量组成的数组的指针变量的函数.
- 指针的类型
指针所指向的类型,当你通过指针来访问指针所指向的内存区时,指针所指向的类型决定了编译器将把那片内存区里的内容当做什么来看待。从语法上看,你只须把指针声明语句中的指针名字和名字左边的指针声明符*去掉,剩下的就是指针所指向的类型。例如:
int *ptr; // 指针所指向的类型是int
char *ptr; // 指针所指向的的类型是char
int **ptr; // 指针所指向的的类型是int *
int (*ptr)[3]; // 指针所指向的的类型是int()[3]
int *(*ptr)[4]; // 指针所指向的的类型是int *()[4]
在指针的算术运算中,指针所指向的类型有很大的作用。
指针的类型(即指针本身的类型)和指针所指向的类型是两个概念。当你对C越来越熟悉时,你会发现,把与指针搅和在一起的"类型"这个概念分成"指针的类型"和"指针所指向的类型"两个概念,是精通指针的关键点之一。
- 指针的值
指针的值是指针本身存储的数值,这个值将被编译器当作一个地址,而不是一个一般的数值。在32位程序里,所有类型的指针的值都是一个32位整数,因为32位程序里内存地址全都是32位长。指针所指向的内存区就是从指针的值所代表的那个内存地址开始,长度为sizeof(指针所指向的类型)的一片内存区。以后,我们说一个指针的值是XX,就相当于说该指针指向了以XX为首地址的一片内存区域;我们说一个指针指向了某块内存区域,就相当于说该指针的值是这块内存区域的首地址。指针所指向的内存区和指针所指向的类型是两个完全不同的概念。在例一中,指针所指向的类型已经有了,但由于指针还未初始化,所以它所指向的内存区是不存在的,或者说是无意义的。
指针本身所占据的内存区:你只要用函数sizeof(指针的类型)测一下就知道了。在32位平台里,指针本身占据了4个字节的长度。指针本身占据的内存这个概念在判断一个指针表达式是否是左值时很有用。 * 指针的算术运算
指针可以加上或减去一个整数。指针的这种运算的意义和通常的数值的加减运算的意义是不一样的。例如:
char a[20];
int *ptr=a;
...
...
ptr++;
在上例中,指针ptr的类型是int*,它指向的类型是int,它被初始化为指向整形变量a。接下来的第3句中,指针ptr被加了1,编译器是这样处理的:它把指针ptr的值加上了sizeof(int),在32位程序中,是被加上了4。由于地址是用字节做单位的,故ptr所指向的地址由原来的变量a的地址向高地址方向增加了4个字节。由于char类型的长度是一个字节,所以,原来ptr是指向数组a的第0号单元开始的四个字节,此时指向了数组a中从第4号单元开始的四个字节。
我们可以用一个指针和一个循环来遍历一个数组,看例子:
int array[20];
int *ptr=array;
...
//此处略去为整型数组赋值的代码。
...
for(i=0;i<20;i++)
{
(*ptr)++;
ptr++;
}
这个例子将整型数组中各个单元的值加1。由于每次循环都将指针ptr加1,所以每次循环都能访问数组的下一个单元。再看例子:
char a[20];
int *ptr = a;
...
...
ptr += 5;
在这个例子中,ptr被加上了5,编译器是这样处理的:将指针ptr的值加上5乘sizeof(int),在32位程序中就是加上了5乘4=20。由于地址的单位是字节,故现在的ptr所指向的地址比起加5后的ptr所指向的地址来说,向高地址方向移动了20个字节。在这个例子中,没加5前的ptr指向数组a的第0号单元开始的四个字节,加5后,ptr已经指向了数组a的合法范围之外了。虽然这种情况在应用上会出问题,但在语法上却是可以的。这也体现出了指针的灵活性。
如果上例中,ptr是被减去5,那么处理过程大同小异,只不过ptr的值是被减去5乘sizeof(int),新的ptr指向的地址将比原来的ptr所指向的地址向低地址方向移动了20个字节。
总结一下,一个指针ptrold加上一个整数n后,结果是一个新的指针ptrnew,ptrnew的类型和ptrold的类型相同,ptrnew所指向的类型和ptrold所指向的类型也相同。ptrnew的值将比ptrold的值增加了n乘sizeof(ptrold所指向的类型)个字节。就是说,ptrnew所指向的内存区将比ptrold所指向的内存区向高地址方向移动了n乘sizeof(ptrold所指向的类型)个字节。一个指针ptrold减去一个整数n后,结果是一个新的指针ptrnew,ptrnew的类型和ptrold的类型相同,ptrnew所指向的类型和ptrold所指向的类型也相同。ptrnew的值将比ptrold的值减少了n乘sizeof(ptrold所指向的类型)个字节,就是说,ptrnew所指向的内存区将比ptrold所指向的内存区向低地址方向移动了n乘sizeof(ptrold所指向的类型)个字节。
- 运算符&和*
这里&是取地址运算符,*叫做"间接运算符"。&a的运算结果是一个指针,指针的类型是a的类型加个*,指针所指向的类型是a的类型,指针所指向的地址嘛,那就是a的地址。*p的运算结果就五花八门了。总之*p的结果是p所指向的东西,这个东西有这些特点:它的类型是p指向的类型,它所占用的地址是p所指向的地址。
int a=12;
int b;
int *p;
int **ptr;
p=&a; // &a的结果是一个指针,类型是int*,指向的类型是int,指向的地址是a的地址。
*p=24; // *p的结果,在这里它的类型是int,它所占用的地址是p所指向的地址,显然,*p就是变量a。
ptr=&p; // &p的结果是个指针,该指针的类型是p的类型加个*,在这里是int**。该指针所指向的类型是p的类型,这里是int*。该指针所指向的地址就是指针p自己的地址。
*ptr=&b;// *ptr是个指针,&b的结果也是个指针,且这两个指针的类型和所指向的类型是一样的,所以?amp;b来给*ptr赋值就是毫无问题的了。
**ptr=34; // *ptr的结果是ptr所指向的东西,在这里是一个指针,对这个指针再做一次*运算,结果就是一个int类型的变量。
- 指针表达式
一个表达式的最后结果如果是一个指针,那么这个表达式就叫指针表达式。下面是一些指针表达式的例子:
int a,b;
int array[10];
int *pa;
pa=&a; // &a是一个指针表达式。
int **ptr=&pa; // &pa也是一个指针表达式。
*ptr=&b; // *ptr和&b都是指针表达式。
pa=array;
pa++; // 这也是指针表达式。
char *arr[20];
char **parr=arr; // 如果把arr看作指针的话,arr也是指针表达式
char *str;
str=*parr; // *parr是指针表达式
str=*(parr+1); // *(parr+1)是指针表达式
str=*(parr+2); // *(parr+2)是指针表达式
由于指针表达式的结果是一个指针,所以指针表达式也具有指针所具有的四个要素:指针的类型,指针所指向的类型,指针指向的内存区,指针自身占据的内存。当一个指针表达式的结果指针已经明确地具有了指针自身占据的内存的话,这个指针表达式就是一个左值,否则就不是一个左值。 在例七中,&a不是一个左值,因为它还没有占据明确的内存。*ptr是一个左值,因为*ptr这个指针已经占据了内存,其实*ptr就是指针pa,既然pa已经在内存中有了自己的位置,那么*ptr当然也有了自己的位置。
- 数组和指针的关系
数组的数组名其实可以看作一个指针。看下例:
int array[10]={0,1,2,3,4,5,6,7,8,9},value;
...
...
value=array[0]; // 也可写成:value=*array;
value=array[3]; // 也可写成:value=*(array+3);
value=array[4]; // 也可写成:value=*(array+4);
一般而言数组名array代表数组本身,类型是int [10],但如果把array看做指针的话,它指向数组的第0个单元,类型是int *,所指向的类型是数组单元的类型即int。因此*array等于0就一点也不奇怪了。同理,array+3是一个指向数组第3个单元的指针,所以*(array+3)等于3。其它依此类推。
char *str[3]={
"Hello,this is a sample!",
"Hi,good morning.",
"Hello world"
};
char s[80];
strcpy(s,str[0]); // 也可写成strcpy(s,*str);
strcpy(s,str[1]); // 也可写成strcpy(s,*(str+1));
strcpy(s,str[2]); // 也可写成strcpy(s,*(str+2));
上例中,str是一个三单元的数组,该数组的每个单元都是一个指针,这些指针各指向一个字符串。把指针数组名str当作一个指针的话,它指向数组的第0号单元,它的类型是char**,它指向的类型是char *。*str也是一个指针,它的类型是char*,它所指向的类型是char,它指向的地址是字符串"Hello,this is a sample!"的第一个字符的地址,即'H'的地址。 str+1也是一个指针,它指向数组的第1号单元,它的类型是char**,它指向的类型是char *。 *(str+1)也是一个指针,它的类型是char*,它所指向的类型是char,它指向"Hi,good morning."的第一个字符'H',等等。
下面总结一下数组的数组名的问题。声明了一个数组TYPE array[n],则数组名称array就有了两重含义:第一,它代表整个数组,它的类型是TYPE [n];第二,它是一个指针,该指针的类型是TYPE*,该指针指向的类型是TYPE,也就是数组单元的类型,该指针指向的内存区就是数组第0号单元,该指针自己占有单独的内存区,注意它和数组第0号单元占据的内存区是不同的。该指针的值是不能修改的,即类似array++的表达式是错误的。
在不同的表达式中数组名array可以扮演不同的角色。
- 在表达式sizeof(array)中,数组名array代表数组本身,故这时sizeof函数测出的是整个数组的大小。
- 在表达式*array中,array扮演的是指针,因此这个表达式的结果就是数组第0号单元的值。sizeof(*array)测出的是数组单元的大小。
- 表达式array+n(其中n=0,1,2,....。)中,array扮演的是指针,故array+n的结果是一个指针,它的类型是TYPE*,它指向的类型是TYPE,它指向数组第n号单元。故sizeof(array+n)测出的是指针类型的大小。
int array[10];
int (*ptr)[10];
ptr=&array;
上例中ptr是一个指针,它的类型是int (*)[10],他指向的类型是int [10],我们用整个数组的首地址来初始化它。在语句ptr=&array中,array代表数组本身。
本节中提到了函数sizeof(),那么sizeof(指针名称)测出的究竟是指针自身类型的大小呢还是指针所指向的类型的大小?答案是前者。例如:
int (*ptr)[10];
则在32位程序中,有:
sizeof(int(*)[10])==4
sizeof(int [10])==40
sizeof(ptr)==4
实际上,sizeof(对象)测出的都是对象自身的类型的大小,而不是别的什么类型的大小。
- 指针和结构类型的关系
可以声明一个指向结构类型对象的指针。
struct MyStruct {
int a;
int b;
int c;
}
MyStruct ss={20,30,40}; // 声明了结构对象ss,并把ss的三个成员初始化为20,30和40。
MyStruct *ptr=&ss; // 声明了一个指向结构对象ss的指针。它的类型是MyStruct*,它指向的类型是MyStruct。
int *pstr=(int*)&ss; // 声明了一个指向结构对象ss的指针。但是它的类型和它指向的类型和ptr是不同的。
请问怎样通过指针ptr来访问ss的三个成员变量?
ptr->a;
ptr->b;
ptr->c;
又请问怎样通过指针pstr来访问ss的三个成员变量?
*pstr; // 访问了ss的成员a。
*(pstr+1); // 访问了ss的成员b。
*(pstr+2) // 访问了ss的成员c。
呵呵,虽然我在我的MSVC++6.0上调式过上述代码,但是要知道,这样使用pstr来访问结构成员是不正规的,为了说明为什么不正规,让我们看看怎样通过指针来访问数组的各个单元:
int array[3]={35,56,37};
int *pa=array;
通过指针pa访问数组array的三个单元的方法是:
*pa; // 访问了第0号单元
*(pa+1);// 访问了第1号单元
*(pa+2);// 访问了第2号单元
从格式上看倒是与通过指针访问结构成员的不正规方法的格式一样。
所有的C/C++编译器在排列数组的单元时,总是把各个数组单元存放在连续的存储区里,单元和单元之间没有空隙。但在存放结构对象的各个成员时,在某种编译环境下,可能会需要字对齐或双字对齐或者是别的什么对齐,需要在相邻两个成员之间加若干个"填充字节",这就导致各个成员之间可能会有若干个字节的空隙。
所以,在例子中,即使*pstr访问到了结构对象ss的第一个成员变量a,也不能保证*(pstr+1)就一定能访问到结构成员b。因为成员a和成员b之间可能会有若干填充字节,说不定*(pstr+1)就正好访问到了这些填充字节呢。这也证明了指针的灵活性。要是你的目的就是想看看各个结构成员之间到底有没有填充字节,嘿,这倒是个不错的方法。
- 指针和函数的关系
可以把一个指针声明成为一个指向函数的指针。
int fun1(char*,int);
int (*pfun1)(char*,int);
pfun1=fun1;
....
....
int a=(*pfun1)("abcdefg",7); // 通过函数指针调用函数。
可以把指针作为函数的形参。在函数调用语句中,可以用指针表达式来作为实参。
1.3 #pragma用法详解
在所有的预处理指令中,#Pragma指令可能是最复杂的了,它的作用是设定编译器的状态或者是指示编译器完成一些特定的动作。#pragma指令对每个编译器给出了一个方法,在保持与C和C++语言完全兼容的情况下,给出主机或操作系统专有的特征。依据定义,编译指示是机器或操作系统专有的,且对于每个编译器都是不同的。其格式一般为:#pragma Para。其中Para为参数,下面来看一些常用的参数:
| alloc_text | comment | init_seg* | optimize |
| auto_inline | component | inline_depth | pack |
| bss_seg | data_seg | inline_recursion | pointers_to_members* |
| check_stack | function | intrinsic | setlocale |
| code_seg | hdrstop | message | vtordisp* |
| const_seg | include_alias | once | warning |
- alloc_text
#pragma alloc_text( "textsection", function1, ... )
命名特别定义的函数驻留的代码段。该编译指示必须出现在函数说明符和函数定义之间。
alloc_text编译指示不处理C++成员函数或重载函数。它仅能应用在以C连接方式说明的函数。如果你试图将这个编译指示应用于一个具有C++连接方式的函数时,将出现一个编译程序错误。由于不支持使用__based的函数地址,需要使用alloc_text编译指示来指定段位置。由textsection指定的名字应该由双引号括起来。
alloc_text编译指示必须出现在任何需要指定的函数说明之后,以及这些函数的定义之前。在alloc_text编译指示中引用的函数必须和该编译指示处于同一个模块中。如果不这样做,使以后一个未定义的函数被编译到一个不同的代码段时,错误会也可能不会被捕获。即使程序一般会正常运行,但是函数不会分派到应该在的段。
alloc_text的其它限制如下:它不能用在一个函数内部,它必须用于函数说明以后,函数定义以前。
- code_seg
#pragma code_seg( ["section-name"[,"section-class"] ] )
指定分配函数的代码段。code_seg编译指示为函数指定默认的段。你也能够像段名一样指定一个可选的类名。使用没有段名字符串的#pragma code_seg将恢复分配到编译开始时候的状态。
- const_seg
#pragma const_seg( ["section-name"[, "section-class"] ] )
指定用于常量数据的默认段。data_seg编译指示除了可以工作于所有数据以外具有一样的效果。你能够使用该编译指示将你的常量数据保存在一个只读的段中。
#pragma const_seg( "MY_DATA" )
导致在#pragma语句后面的常量数据分配在一个叫做MY_DATA的段中。用const_seg编译指示分配的数据不包含任何关于其位置的信息。第二个参数section-class是用于兼容2.0版本以前的Visual C++的,现在将忽略它。
- comment
#pragma comment( comment-type [, commentstring] )
将描述记录安排到目标文件或可执行文件中去。comment-type是下面说明的五个预定义标识符中的一个,用来指定描述记录的类型。可选的commentstring是一个字符串文字值用于为一些描述类型提供附加的信息。因为commentstring是一个字符串文字值,所以它遵从字符串文字值的所有规则,例如换码字符、嵌入的引号(")和联接。
下面的编译指示导致连接程序在连接时搜索EMAPI.LIB库。连接程序首先在当前工作目录然后在LIB环境变量指定的路径中搜索。
#pragma comment( lib, "emapi" )
下面的编译指示导致编译程序将其名字和版本号放置到目标文件中去。
#pragma comment( compiler )
注意,对于具有commentstring参数的描述记录,你可以使用其它用作字符串文字量的宏来提供宏扩展为字符串文字量。你也能够联结任何字符串文字量和宏的组合来扩展成为一个字符串文字量。例如,下面的语句是可以接受的:
#pragma comment( user, "Compiled on " __DATE__ " at " __TIME__ )
- data_seg
#pragma data_seg( ["section-name"[, "section-class"] ] )
指定数据的默认段。例如:#pragma data_seg( "MY_DATA" )导致在#pragma语句后分配的数据保存在一个叫做MY_DATA的段中。
用data_seg编译指示分配的数据不包含任何关于其位置的信息,第二个参数section-class是用于兼容2.0版本以前的Visual C++的,现在将忽略它。
- init_seg
C++特有,#pragma init_seg({ compiler | lib | user | "section-name" [, "func-name"]} )
指定影响启动代码执行的关键字或代码段。因为全局静态对象的初始化可以包含执行代码,所以你必须指定一个关键字来定义什么时候构造对象。在使用需要初始化的动态连接库(DLL)或程序库时使用init_seg编译指示是尤其重要的。
- message
#pragma message( messagestring )
不中断编译,发送一个字符串文字量到标准输出。message编译指示的典型运用是在编译时显示信息。下面的代码段用message编译指示在编译过程中显示一条信息:
#if _M_IX86 == 500
#pragma message( "Pentium processor build" )
#endif
messagestring参数可以是一个能够扩展成字符串文字量的宏,并且你能够用字符串文字量和宏的任何组合来构造。例如,下面的语句显示被编译文件的文件名和文件最后一次修改的日期和时间。
#pragma message( "Compiling " __FILE__ )
#pragma message( "Last modified on " __TIMESTAMP__ )
- once
#pragma once
指定在创建过程中该编译指示所在的文件仅仅被编译程序包含(打开)一次。该编译指示的一种常见用法如下:
// header.h
#pragma once
- optimize
#pragma optimize( "[optimization-list]", {on | off} )
代码优化仅有Visual C++专业版和企业版支持。详见Visual C++ Edition。指定在函数层次执行的优化。optimize编译选项必须在函数外出现,并且在该编译指示出现以后的第一个函数定义开始起作用。on和off参数打开或关闭在optimization-list指定的选项。
optimization-list能够是0或更多个在表2.2中给出的参数:
optimize编译指示的参数:
| 参数 | 优化类型 |
|---|---|
| a | 假定没有别名。 |
| g | 允许全局优化。 |
| p | 增强浮点一致性。 |
| s或t | 指定更短或者更快的机器代码序列。 |
| w | 假定在函数调用中没有别名。 |
| y | 在程序堆栈中生成框架指针。 |
这些和在/O编译程序选项中使用的是相同的字母。例如:
#pragma optimize( "atp", on )
用空字符串("")的optimize编译指示是一种特别形式。它要么关闭所有的优化选项,要么恢复它们到原始(或默认)的设定。
#pragma optimize( "", off )
#pragma optimize( "", on )
- pack
#pragma pack( [ n] )
指定结构和联合成员的紧缩对齐。尽管用/Zp选项设定整个翻译单元的结构和联合成员的紧缩对齐,可以用pack编译指示在数据说明层次设定紧缩对齐。从出现该编译指示后的第一个结构或者联合说明开始生效。这个编译指示不影响定义。
当你使用#pragma pack(n),其中n是1,2,4,8或者16,第一个以后的每个结构成员保存在较小的成员类型或者n字节边界上。如果你使用没有参数的#pragma pack,结构成员将被紧缩到由/Zp指定的值。默认的/Zp紧缩的大小是/Zp8。
编译程序还支持下面的增强语法:
#pragma pack( [ [ { push | pop}, ] [ identifier, ] ] [ n ] )
该语法允许你将使用不同紧缩编译指示的组件合并到同一个翻译单元内。
每次出现有push参数的pack编译指示将保存当前的紧缩对齐值到一个内部的编译程序堆栈。编译指示的参数列表从左向右读取。如果你使用了push,当前紧缩值被保存。如果你提供了一个n值,这个值将成为新的紧缩值。如果你指定了一个你选定的标示符,这个标示符将和新的紧缩值关联。
每次出现有pop参数的pack编译指示从内部编译程序堆栈顶部取出一个值并将那个值作为新的紧缩对齐。如果你用了pop,而内部编译程序堆栈是空的,对齐值将从命令行得到,同时给出一个警告。如果你用了pop并指定了n的值,那个值将成为新的紧缩值。如果你用了pop并指定了一个标示符,将移去所有保存在堆栈中的的值直到匹配的找到匹配的标示符,和该标示符关联的紧缩值也被从堆栈中移出来成为新的紧缩值。如果没有找到匹配的标示符,将从命令行获取紧缩值并产生一个1级警告。默认的紧缩对齐是8。
pack编译指示的新的增强功能允许你编写头文件保证在使用头文件之前和其后的紧缩值是一样的:
/* File name: include1.h */
#pragma pack( push, enter_include1 )
/* Your include-file code ... */
#pragma pack( pop, enter_include1 )
/* End of include1.h */
在前面的例子中,进入头文件时将当前紧缩值和标示符enter_include1关联并推入,被记住。在头文件尾部的pack编译选项移去所有在头文件中可能遇到的紧缩值并移去和enter_include1关联的紧缩值。这样头文件保证了在使用头文件之前和其后的紧缩值是一样的。
新功能也允许你在你的代码内用pack编译指示为不同的代码,例如头文件设定不同的紧缩对齐。
#pragma pack( push, before_include1 )
#include "include1.h"
#pragma pack( pop, before_include1 )
在上一个例子中,你的代码受到保护,防止了在include.h中的任何紧缩值的改变。
- warning
#pragma warning( warning-specifier : warning-number-list [,warning-specifier : warning-number-list...] )
#pragma warning( push[ , n ] )
#pragma warning( pop )
允许有选择地修改编译程序警告信息的行为。
warning-specifier能够是下列值之一:
| warning-specifier | 含义 |
|---|---|
| once | 只显示指定信息一次。 |
| default | 对指定信息应用默认的编译程序选项。 |
| 1,2,3,4 | 对指定信息引用给定的警告等级。 |
| disable | 不显示指定信息。 |
| error | 对指定信息作为错误显示。 |
warning-number_list能够包含任何警告编号。如下,在一个编译指示中可以指定多个选项:
#pragma warning( disable : 4507 34; once : 4385; error : 164 )
这等价于:
#pragma warning( disable : 4507 34 ) // Disable warning messages
// 4507 and 34.
#pragma warning( once : 4385 ) // Issue warning 4385
// only once.
#pragma warning( error : 164 ) // Report warning 164
// as an error.
对于那些关于代码生成的,大于4699的警告标号,warning编译指示仅在函数定义外时有效。如果指定的警告编号大于4699并且用于函数内时被忽略。下面例子说明了用warning编译指示禁止、然后恢复有关代码生成警告信息的正确位置:
int a;
#pragma warning( disable : 4705 )
void func(){
a;
}
#pragma warning( default : 4705 )
warning编译指示也支持下面语法:
#pragma warning( push [ ,n ] )
#pragma warning( pop )
这里n表示警告等级(1到4)。
- warning(push)编译指示保存所有警告的当前警告状态。warning(push,n)保存所有警告的当前状态并将全局警告等级设置为n。
- warning(pop)弹出最后一次推入堆栈中的警告状态。任何在push和pop之间改变的警告状态将被取消。
考虑下面的例子:
#pragma warning( push )
#pragma warning( disable : 4705 )
#pragma warning( disable : 4706 )
#pragma warning( disable : 4707 )
// Some code
#pragma warning( pop )
在这些代码的结束,pop恢复了所有警告的状态(包括4705,4706和4707)到代码开始时候的样子。
当你编写头文件时,你能用push和pop来保证任何用户修改的警告状态不会影响正常编译你的头文件。在头文件开始的地方使用push,在结束地方使用pop。例如,假定你有一个不能顺利在4级警告下编译的头文件,下面的代码改变警告等级到3,然后在头文件的结束时恢复到原来的警告等级。
#pragma warning( push, 3 )
// Declarations/ definitions
#pragma warning( pop )
二、关键字
2.1 static
static有两种用法:面向过程程序设计中的static和面向对象程序设计中的static。前者应用于普通变量和函数,不涉及类;后者主要说明static在类中的作用。
- 面向过程设计中的static
静态全局变量
在全局变量前,加上关键字static,该变量就被定义成为一个静态全局变量。我们先举一个静态全局变量的例子,如下:
#include <iostream.h>
void fn();
static int n; //定义静态全局变量
void main() {
n=20;
cout<<n<<endl;
fn();
}
void fn() {
n++;
cout<<n<<endl;
}
静态全局变量有以下特点:
该变量在全局数据区分配内存;
未经初始化的静态全局变量会被程序自动初始化为0(自动变量的值是随机的,除非它被显式初始化);
静态全局变量在声明它的整个文件都是可见的,而在文件之外是不可见的;
静态变量都在全局数据区分配内存,包括后面将要提到的静态局部变量。对于一个完整的程序,在内存中的分布情况如下图:代码区,全局数据区,堆区和栈区。
一般程序的由new产生的动态数据存放在堆区,函数内部的自动变量存放在栈区。自动变量一般会随着函数的退出而释放空间,静态数据(即使是函数内部的静态局部变量)也存放在全局数据区。全局数据区的数据并不会因为函数的退出而释放空间。定义全局变量就可以实现变量在文件中的共享,但定义静态全局变量还有以下好处:
静态全局变量不能被其它文件所用;
其它文件中可以定义相同名字的变量,不会发生冲突;
静态局部变量
在局部变量前,加上关键字static,该变量就被定义成为一个静态局部变量。 我们先举一个静态局部变量的例子,如下:
#include <iostream.h>
void fn();
void main(){
fn();
fn();
fn();
}
void fn(){
static int n=10;
cout<<n<<endl;
n++;
}
通常,在函数体内定义了一个变量,每当程序运行到该语句时都会给该局部变量分配栈内存。但随着程序退出函数体,系统就会收回栈内存,局部变量也相应失效。但有时候我们需要在两次调用之间对变量的值进行保存。通常的想法是定义一个全局变量来实现。但这样一来,变量已经不再属于函数本身了,不再仅受函数的控制,给程序的维护带来不便。静态局部变量正好可以解决这个问题。静态局部变量保存在全局数据区,而不是保存在栈中,每次的值保持到下一次调用,直到下次赋新值。
静态局部变量有以下特点:
该变量在全局数据区分配内存;
静态局部变量在程序执行到该对象的声明处时被首次初始化,即以后的函数调用不再进行初始化;
静态局部变量一般在声明处初始化,如果没有显式初始化,会被程序自动初始化为0;
它始终驻留在全局数据区,直到程序运行结束。但其作用域为局部作用域,当定义它的函数或语句块结束时,其作用域随之结束;
静态函数
在函数的返回类型前加上static关键字,函数即被定义为静态函数。静态函数与普通函数不同,它只能在声明它的文件当中可见,不能被其它文件使用。
静态函数的例子:
#include <iostream.h>
static void fn();//声明静态函数
void main(){
fn();
}
void fn()//定义静态函数
{
int n=10;
cout<<n<<endl;
}
定义静态函数的好处:
静态函数不能被其它文件所用;
其它文件中可以定义相同名字的函数,不会发生冲突;
- 面向对象的static关键字(类中static关键字)
静态数据成员
在类内数据成员的声明前加上关键字static,该数据成员就是类内的静态数据成员。先举一个静态数据成员的例子。
#include <iostream.h>
class Myclass {
public:
Myclass(int a,int b,int c);
void GetSum();
private:
int a,b,c;
static int Sum;//声明静态数据成员
};
int Myclass::Sum=0;//定义并初始化静态数据成员
Myclass::Myclass(int a,int b,int c) {
this->a=a;
this->b=b;
this->c=c;
Sum+=a+b+c;
}
void Myclass::GetSum() {
cout<<"Sum="<<Sum<<endl;
}
void main() {
Myclass M(1,2,3);
M.GetSum();
Myclass N(4,5,6);
N.GetSum();
M.GetSum();
}
可以看出,静态数据成员有以下特点:
对于非静态数据成员,每个类对象都有自己的拷贝。而静态数据成员被当作是类的成员。无论这个类的对象被定义了多少个,静态数据成员在程序中也只有一份拷贝,由该类型的所有对象共享访问。也就是说,静态数据成员是该类的所有对象所共有的。对该类的多个对象来说,静态数据成员只分配一次内存,供所有对象共用。所以,静态数据成员的值对每个对象都是一样的,它的值可以更新;
静态数据成员存储在全局数据区。静态数据成员定义时要分配空间,所以不能在类声明中定义。在上面例子中,语句
int Myclass::Sum=0;是定义静态数据成员;静态数据成员和普通数据成员一样遵从public,protected,private访问规则;
因为静态数据成员在全局数据区分配内存,属于本类的所有对象共享,所以,它不属于特定的类对象,在没有产生类对象时其作用域就可见,即在没有产生类的实例时,我们就可以操作它;
静态数据成员初始化与一般数据成员初始化不同。静态数据成员初始化的格式为:
<数据类型><类名>::<静态数据成员名>=<值>类的静态数据成员有两种访问形式:
<类对象名>.<静态数据成员名>或<类类型名>::<静态数据成员名>, 如果静态数据成员的访问权限允许的话(即public的成员),可在程序中,按上述格式来引用静态数据成员;静态数据成员主要用在各个对象都有相同的某项属性的时候。比如对于一个存款类,每个实例的利息都是相同的。所以,应该把利息设为存款类的静态数据成员。这有两个好处,第一,不管定义多少个存款类对象,利息数据成员都共享分配在全局数据区的内存,所以节省存储空间。第二,一旦利息需要改变时,只要改变一次,则所有存款类对象的利息全改变过来了; •
同全局变量相比,使用静态数据成员有两个优势:
静态数据成员没有进入程序的全局名字空间,因此不存在与程序中其它全局名字冲突的可能性;
可以实现信息隐藏。静态数据成员可以是private成员,而全局变量不能;
静态成员函数
与静态数据成员一样,我们也可以创建一个静态成员函数,它为类的全部服务而不是为某一个类的具体对象服务。静态成员函数与静态数据成员一样,都是类的内部实现,属于类定义的一部分。普通的成员函数一般都隐含了一个this指针,this指针指向类的对象本身,因为普通成员函数总是具体的属于某个类的具体对象的。通常情况下,this是缺省的。如函数fn()实际上是this->fn()。但是与普通函数相比,静态成员函数由于不是与任何的对象相联系,因此它不具有this指针。从这个意义上讲,它无法访问属于类对象的非静态数据成员,也无法访问非静态成员函数,它只能调用其余的静态成员函数。下面举个静态成员函数的例子。
#include <iostream.h>
class Myclass
{
public:
Myclass(int a,int b,int c);
static void GetSum();/声明静态成员函数
private:
int a,b,c;
static int Sum;//声明静态数据成员
};
int Myclass::Sum=0;//定义并初始化静态数据成员
Myclass::Myclass(int a,int b,int c)
{
this->a=a;
this->b=b;
this->c=c;
Sum+=a+b+c; //非静态成员函数可以访问静态数据成员
}
void Myclass::GetSum() //静态成员函数的实现
{
// cout<<a<<endl; //错误代码,a是非静态数据成员
cout<<"Sum="<<Sum<<endl;
}
void main()
{
Myclass M(1,2,3);
M.GetSum();
Myclass N(4,5,6);
N.GetSum();
Myclass::GetSum();
}
2.2 const
const是constant的简写,是不变的意思。但并不是说它修饰常量,而是说它限定一个变量为只读。
- 修饰普通变量
例如:
const int NUM = 10; // 与int const NUM等价
NUM = 9; // 编译错误,不可再次修改
由于使用了const修饰NUM,使得NUM为只读,因此尝试对NUM再次赋值的操作是非法的,编译器将会报错。正因如此,如果需要使用const修饰一个变量,那么它只能在开始声明时就赋值,否则后面就没有机会了(后面会讲到一个特殊情况)。
- 修饰数组
例如使用const关键字修饰数组,使其元素不允许被改变:
const int arr[] = {0,0,2,3,4}; // 与int const arr[]等价
arr[2] = 1; // 编译错误
试图修改arr的内容的操作是非法的,编译器将会报错:error: assignment of read-only location ‘arr[2]’。
- 修饰指针
修饰指针的情况比较多,主要有以下几种情况:
const修饰*p,指向的对象只读,指针的指向可变:
int a = 9;
int b = 10;
const int *p = &a;//p是一个指向int类型的const值,与int const *p等价
*p = 11; //编译错误,指向的对象是只读的,不可通过p进行改变
p = &b; //合法,改变了p的指向
这里为了便于理解,可认为const修饰的是p,通常使用对指针进行解引用来访问对象,因而,该对象是只读的。
const修饰p,指向的对象可变,指针的指向不可变:
int a = 9;
int b = 10;
int * const p = &a;//p是一个const指针
*p = 11; //合法,
p = &b; //编译错误,p是一个const指针,只读,不可变
指针不可改变指向,指向的内容也不可变
int a = 9;
int b = 10;
const int * const p = &a;// p既是一个const指针,同时也指向了int类型的const值
*p = 11; // 编译错误,指向的对象是只读的,不可通过p进行改变
p = &b; // 编译错误,p是一个const指针,只读,不可变
一句话总结:const放在的左侧任意位置,限定了该指针指向的对象是只读的;const放在的右侧,限定了指针本身是只读的,即不可变的。
- 修饰函数形参
实际上,为我们可以经常发现const关键字的身影,例如很多库函数的声明:
char *strncpy(char *dest,const char *src,size_t n);//字符串拷贝函数
int *strncmp(const char *s1,const char *s2,size_t n);//字符串比较函数
通过看strncpy函数的原型可以知道,源字符串src是只读的,不可变的,而dest并没有该限制。我们通过一个小例子继续观察:
// test.c
#include<stdio.h>
void myPrint(const char *str);
void myPrint(const char *str) {
str[0] = 'H';
printf("my print:%s\n",str);
}
int main(void) {
char str[] = "hello world";
myPrint(str);
return 0;
}
在这个例子中,我们不希望myPrint函数修改传入的字符串内容,因此入参使用了const限定符,表明传入的字符串是只读的,因此,如果myPrint函数内部如果尝试对str进行修改,将会报错:
$ gcc -o test test.c
test.c:6:12: error: assignment of read-only location ‘*str’
str[0] = 'H';
因此,我们自己在编码过程中,如果确定传入的指针参数仅用于访问数据,那么应该将其声明为一个指向const限定类型的指针,避免函数内部对数据进行意外地修改。
- 修饰全局变量
我们知道,使用全局变量是一种不安全的做法,因为程序的任何部分都能够对全局数据进行修改。而如果对全局变量增加const限定符(假设该全局数据不希望被修改),就可以避免被程序其他部分修改。这里有两种使用方式。
第一种,在a文件中定义,其他文件中使用外部声明,例如:
// a.h
const int ARR[] = {0,1,2,3,4,5,6,7,8,9}; //定义int数组
// b.c
extern const int ARR[]; // 注意,这里不能再对ARR进行赋值
第二种,在a文件中定义,并使用static修饰,b文件包含a文件,例如:
// a.h
static const int ARR[] = {0,1,2,3,4,5,6,7,8,9}; //定义int数组
// b.c
#include<a.h>
//后面可以使用ARR
注意,这里必须使用static修饰,否则多个文件包含导致编译会出现重复定义的错误。有兴趣的可以尝试一下。
const修饰的变量是真正的只读吗?使用const修饰之后的变量真的是完全的只读吗?看下面这个例子:
#include <stdio.h>
int main(void){
const int a = 2018;
int *p = &a;
*p = 2019;
printf("%d\n",a);
return 0;
}
运行结果:2019。可以看到,我们通过另外定义一个指针变量,将被const修饰的a的值改变了。那么我们不禁要问,const到底做了什么呢?它修饰的变量是真正意义上的只读吗?为什么它修饰的变量的值仍然可以改变?
const关键字告诉了编译器,它修饰的变量不能被改变,如果代码中发现有类似改变该变量的操作,那么编译器就会捕捉这个错误。那么它在实际中的意义之一是什么呢?帮助程序员提前发现问题,避免不该修改的值被意外地修改,但是无法完全保证不被修改!例如我们可以通过对指针进行强转:
#include<stdio.h>
void myPrint(const char *str);
void myPrint(const char *str) {
char *b = (char *)str;
b[0] = 'H';
printf("my print:%s\n",b);
}
int main(void) {
char str[] = "hello world";
myPrint(str);
return 0;
}
运行结果:my print:Hello world。
三、openMP
Open Multi-Processing的缩写,是一个应用程序接口(API),可用于显式指导多线程、共享内存的并行性。由三个主要的API组件组成:编译器指令、运行时库函数和环境变量。
3.1 OpenMP编程模型
内存共享模型:OpenMP是专为多处理器/核,共享内存机器所设计的。底层架构可以是UMA和NUMA。即(Uniform Memory Access和Non-Uniform Memory Access)。

OpenMP仅通过线程来完成并行,一个线程的运行是可由操作系统调用的最小处理单线程们存在于单个进程的资源中,没有了这个进程,线程也不存在了。通常,线程数与机器的处理器/核数相匹配,然而,实际使用取决与应用程序。
OpenMP是一种显式(非自动)编程模型,为程序员提供对并行化的完全控制。一方面,并行化可像执行串行程序和插入编译指令那样简单,另一方面,像插入子程序来设置多级并行、锁、甚至嵌套锁一样复杂。
OpenMP就是采用Fork-Join模型,所有的OpenML程序都以一个单个进程——master thread开始,master threads按顺序执行知道遇到第一个并行区域。
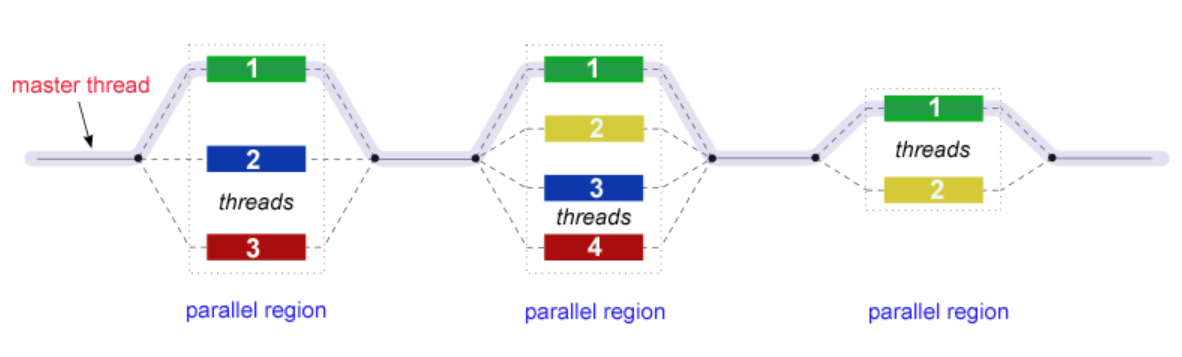
Fork:主线程创造一个并行线程组
Join:当线程组完成并行区域的语句时,它们同步、终止,仅留下主线程
由于OpenMP时是共享内存模型,默认情况下,在共享区域的大部分数据是被共享的,并行区域中的所有线程可以同时访问这个共享的数据,如果不需要默认的共享作用域,OpenMP为程序员提供一种"显示"指定数据作用域的方法。
嵌套并行:API提供在其它并行区域放置并行区域,实际实现也可能不支持。
动态线程:API为运行环境提供动态的改变用于执行并行区域的线程数,实际实现也可能不支持。
- 简单使用
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
int main() {
int nthreads, tid;
/* Fork a team of threads giving them their own copies of variables */
#pragma omp parallel private(nthreads, tid)
{
/* Obtain thread number */
tid = omp_get_thread_num();
printf("Hello World from thread = %d\n", tid);
/* Only master thread does this */
if (tid == 0) {
nthreads = omp_get_num_threads();
printf("Number of threads = %d\n", nthreads);
}
} /* All threads join master thread and disband */
return 0;
}
编译和运行代码:g++ test.cpp -o test -fopenmp -lstdc++ && ./test。
运行结果如下:
Hello World from thread = 3
Hello World from thread = 7
Hello World from thread = 0
Number of threads = 8
Hello World from thread = 1
Hello World from thread = 6
Hello World from thread = 5
Hello World from thread = 4
Hello World from thread = 2
3.2 OpenMP API介绍
OpenMP由三部分组成:编译指令,运行时库程序和环境变量。
- 编译器指令
OpenMP编译器指令用于各种目的:产生平行区域,在线程之间划分代码块,在线程之间分配循环迭代,序列化代码段和线程之间的工作同步。
格式如下:#pragma omp <directive> [clause[[,] clause] ...]。通用规则:
区分大小写
指令遵循编译指令的
C/C++规则每个指令只能指定一个指令名
每个指令最多使用一个后续语句,该语句必须是结构化块
通过在指令行末尾用反斜杠("
\")转义换行符,可以在后续行上“继续”长指令行
并行区域构造:并行区域是将由多个线程执行的代码块。这是基本的OpenMP并行构造。
#pragma omp parallel [clause ...] newline
if (scalar_expression)
private (list)
shared (list)
default(shared | none)
firstprivate (list)
reduction (operator:list)
copyin (list)
num_threads (integer-expression)
structured_block
决定线程数的因素有多个,它们的优先级如下:
if语句的值设置
num_threads语句使用的
omp_set_num_threads()库函数设置的
OMP_NUM_THREADS环境变量
注意:生成的线程编号为0~N,其中0是主线程(master thread)的编号
指令(directive)
| 指令 | 说明 |
|---|---|
atomic |
内存位置将会原子更新(Specifies that a memory location that will be updated atomically.) |
barrier |
线程在此等待,直到所有的线程都运行到此barrier。用来同步所有线程。 |
critical |
其后的代码块为临界区,任意时刻只能被一个线程运行。 |
flush |
所有线程对所有共享对象具有相同的内存视图(view of memory) |
for |
用在for循环之前,把for循环并行化由多个线程执行。循环变量只能是整型 |
master |
指定由主线程来运行接下来的程序。 |
ordered |
指定在接下来的代码块中,被并行化的for循环将依序运行(sequential loop) |
parallel |
代表接下来的代码块将被多个线程并行各执行一遍。 |
sections |
将接下来的代码块包含将被并行执行的section块。 |
single |
之后的程序将只会在一个线程(未必是主线程)中被执行,不会被并行执行。 |
threadprivate |
指定一个变量是线程局部存储(thread local storage) |
从句(clause)
| 从句 | 说明 |
|---|---|
copyin |
让threadprivate的变量的值和主线程的值相同。 |
copyprivate |
不同线程中的变量在所有线程中共享。 |
default |
Specifies the behavior of unscoped variables in a parallel region. |
firstprivate |
对于线程局部存储的变量,其初值是进入并行区之前的值。 |
if |
判断条件,可用来决定是否要并行化。 |
lastprivate |
在一个循环并行执行结束后,指定变量的值为循环体在顺序最后一次执行时获取的值,或者#pragma sections在中,按文本顺序最后一个section中执行获取的值。 |
nowait |
忽略barrier的同步等待。 |
num_threads |
设置线程数量的数量,默认值为当前计算机硬件支持的最大并发数。一般就是CPU的内核数目,超线程被操作系统视为独立的CPU内核。 |
ordered |
使用于for,可以在将循环并行化的时候,将程序中有标记directive ordered的部分依序运行。 |
private |
指定变量为线程局部存储。 |
reduction |
Specifies that one or more variables that are private to each thread are the subject of a reduction operation at the end of the parallel region. |
schedule |
设置for循环的并行化方法;有dynamic、guided、runtime、static四种方法。schedule(static, chunk_size):把chunk_size数目的循环体的执行,静态依序指定给各线程。schedule(dynamic,chunk_size):把循环体的执行按照chunk_size(缺省值为1)分为若干组(即chunk),每个等待的线程获得当前一组去执行,执行完后重新等待分配新的组。schedule(guided,chunk_size):把循环体的执行分组,分配给等待执行的线程。最初的组中的循环体执行数目较大,然后逐渐按指数方式下降到chunk_size。schedule(runtime):循环的并行化方式不在编译时静态确定,而是推迟到程序执行时动态地根据环境变量OMP_SCHEDULE来决定要使用的方法。 |
shared |
指定变量为所有线程共享。 |
OpenmMP的库函数(Run-Time Library Routines)
void omp_set_num_threads(int _Num_threads);在后续并行区域设置线程数,此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域.说明:此函数只能在串行代码部分调用.
int omp_get_num_threads(void);返回当前线程数目.说明:如果在串行代码中调用此函数,返回值为1.
int omp_get_max_threads(void);如果在程序中此处遇到未使用num_threads()子句指定的活动并行区域,则返回程序的最大可用线程数量.说明:可以在串行或并行区域调用,通常这个最大数量由omp_set_num_threads()或OMP_NUM_THREADS环境变量决定。
int omp_get_thread_num(void);返回当前线程id.id从1开始顺序编号,主线程id是0.
int omp_get_num_procs(void);返回程序可用的处理器数.
void omp_set_dynamic(int _Dynamic_threads);启用或禁用可用线程数的动态调整.(缺省情况下启用动态调整.)此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域.如果_Dynamic_threads的值为非零值,启用动态调整;否则,禁用动态调整.
int omp_get_dynamic(void);:确定在程序中此处是否启用了动态线程调整.启用了动态线程调整时返回非零值;否则,返回零值.
int omp_in_parallel(void);确定线程是否在并行区域的动态范围内执行.如果在活动并行区域的动态范围内调用,则返回非零值;否则,返回零值.活动并行区域是指IF子句求值为TRUE的并行区域.
void omp_set_nested(int _Nested);启用或禁用嵌套并行操作.此调用只影响调用线程所遇到的同一级或内部嵌套级别的后续并行区域._Nested的值为非零值时启用嵌套并行操作;否则,禁用嵌套并行操作.缺省情况下,禁用嵌套并行操作.
int omp_get_nested(void);确定在程序中此处是否启用了嵌套并行操作.启用嵌套并行操作时返回非零值;否则,返回零值.
void omp_init_lock(omp_lock_t * _Lock);,void omp_init_nest_lock(omp_nest_lock_t * _Lock);初始化一个(嵌套)互斥锁.
void omp_destroy_lock(omp_lock_t * _Lock);,void omp_destroy_nest_lock(omp_nest_lock_t * _Lock);结束一个(嵌套)互斥锁的使用并释放内存.
void omp_set_lock(omp_lock_t * _Lock);,void omp_set_nest_lock(omp_nest_lock_t * _Lock);获得一个(嵌套)互斥锁.
void omp_unset_lock(omp_lock_t * _Lock);,void omp_unset_nest_lock(omp_nest_lock_t * _Lock);释放一个(嵌套)互斥锁.
int omp_test_lock(omp_lock_t * _Lock);,int omp_test_nest_lock(omp_nest_lock_t * _Lock);试图获得一个(嵌套)互斥锁,并在成功时放回真(true),失败是返回假(false).
double omp_get_wtime(void);,获取wall clock time,返回一个double的数,表示从过去的某一时刻经历的时间,一般用于成对出现,进行时间比较.此函数得到的时间是相对于线程的,也就是每一个线程都有自己的时间.
double omp_get_wtick(void);,得到clock ticks的秒数.
- 环境变量(Environment Variables)
OMP_SCHEDULE:仅适用于DO,PARALLEL DO(Fortran)和(C/C++)指令并行,它们的schedule子句设置为RUNTIME。此变量的值确定如何在处理器上调度循环的迭代。例如:export OMP_SCHEDULE="guided, 4"。
OMP_NUM_THREADS:设置执行期间要使用的最大线程数。例如:export OMP_NUM_THREADS=8。
OMP_DYNAMIC:启用或禁用动态调整可用于执行并行区域的线程数。有效值为TRUE或FALSE。例如:export OMP_DYNAMIC=TRUE
OMP_PROC_BIND:启用或禁用绑定到处理器的线程。有效值为TRUE或FALSE。例如:export OMP_PROC_BIND=TRUE。
OMP_NESTED:启用或禁用嵌套并行性,有效值为TRUE或FALSE。例如:export OMP_NESTED=TRUE。
OMP_STACKSIZE:控制创建(非主)线程的堆栈大小。例如:export OMP_STACKSIZE=2000500B,export OMP_STACKSIZE="3000 k "。
OMP_WAIT_POLICY:提供有关等待线程的所需行为的OpenMP实现的提示。兼容的OpenMP实现可能会也可能不会遵守环境变量的设置。有效值为ACTIVE和PASSIVE。ACTIVE指定等待线程应该主动处于活动状态,即在等待时消耗处理器周期。PASSIVE指定等待线程应该主要是被动的,即在等待时不消耗处理器周期。ACTIVE和PASSIVE行为的细节是实现定义的。例子:export OMP_WAIT_POLICY=ACTIVE。
OMP_MAX_ACTIVE_LEVELS:控制嵌套活动并行区域的最大数量。此环境变量的值必须是非负整数。如果请求的OMP_MAX_ACTIVE_LEVELS值大于实现可以支持的嵌套活动并行级别的最大数量,或者该值不是非负整数,则程序的行为是实现定义的。例:export OMP_MAX_ACTIVE_LEVELS=2。
OMP_THREAD_LIMIT:设置要用于整个OpenMP程序的OpenMP线程数。此环境变量的值必须是正整数。如果请求的OMP_THREAD_LIMIT值大于实现可以支持的线程数,或者该值不是正整数,则程序的行为是实现定义的。例:export OMP_THREAD_LIMIT=8。
3.3 示例
test_v1.cpp
#include <iostream>
#include <omp.h> // NEW ADD
using namespace std;
int main(){
#pragma omp parallel for num_threads(4) // NEW ADD
for(int i=0; i<10; i++) {
cout << "数字为:"<<i << endl;
}
return 0;
}
test_reduce.cpp
#include <iostream>
#include <omp.h> // NEW ADD
using namespace std;
int main(){
int sum = 0;
#pragma omp parallel for num_threads(32) reduction(+:sum)
for(int i=0; i<100; i++) {
sum += i;
}
cout << sum << endl;
return 0;
}
test_primes_num.cpp
#include <iostream>
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <math.h>
#include <omp.h>
#include <sys/time.h>
int main(int argc, char** argv) {
struct timeval start, end;
gettimeofday(&start, NULL);
if (argc != 3) {
std::cout << "USAGE: num_primer <num_of_thread> <integer>" << std::endl;
return -1;
}
int num_thread = atoi(argv[1]);
int n = atoi(argv[2]);
std::cout << "num of thread: " << num_thread << std::endl;
std::cout << " n: " << n << std::endl;
int* num_primer = new int[num_thread];
for (int i = 0; i < num_thread; ++i) {
num_primer[i] = 0;
}
omp_set_num_threads(num_thread);
#pragma omp parallel shared(n, num_primer)
{
int id = omp_get_thread_num();
for (int i = id + 2; i < n + 1; i = i + num_thread) {
bool has_factor = false;
#pragma omp parallel shared(n, i, num_primer, has_factor)
{
for (int j = 2; j < int(sqrt(i)) + 1; ++j) {
if (i % j == 0) {
has_factor = true;
break;
}
}
if (!has_factor) {
++num_primer[id];
std::cout << "id: "<< id << ", primer:" << i << std::endl;
}
} // pragma
}
} // pragma
// add all primers
int sum_num_primer = 0;
for (int i = 0; i < num_thread; ++i) {
sum_num_primer += num_primer[i];
}
std::cout << "The number of primers between 0 and " << n << " is: " << sum_num_primer << std::endl;
gettimeofday(&end, NULL);
double time_gap = (end.tv_sec - start.tv_sec) * 1000000u + end.tv_usec - start.tv_usec;
printf("Time cost: %.2lf s.\n", time_gap / 100000);
return 0;
}
四、标准库
4.1 cstdio库
参考地址: http://www.cplusplus.com/reference/cstdio/
Operations on files
| 函数 | 说明 | 用法 |
|---|---|---|
remove |
Remove file | int remove ( const char * filename ); |
rename |
Rename file | int rename ( const char * oldname, const char * newname ); |
tmpfile |
Open a temporary file | FILE * tmpfile ( void ); |
tmpnam |
Generate temporary filename | char * tmpnam ( char * str ); |
File access
| 函数 | 说明 | 用法 |
|---|---|---|
fclose |
Close file | int fclose ( FILE * stream ); |
fflush |
Flush stream | int fflush ( FILE * stream ); |
fopen |
Open file | FILE * fopen ( const char * filename, const char * mode ); |
freopen |
Reopen stream with different file or mode | FILE * freopen ( const char * filename, const char * mode, FILE * stream ); |
setbuf |
Set stream buffer | void setbuf ( FILE * stream, char * buffer ); |
setvbuf |
Change stream buffering | int setvbuf ( FILE * stream, char * buffer, int mode, size_t size ); |
Formatted input/output
| 函数 | 说明 | 用法 |
|---|---|---|
fprintf |
Write formatted data to stream | int fprintf ( FILE * stream, const char * format, ... ); |
fscanf |
Read formatted data from stream | |
printf |
Print formatted data to stdout | int printf ( const char * format, ... ); |
scanf |
Read formatted data from stdin (function ) | |
snprintf |
Write formatted output to sized buffer (function ) | |
sprintf |
Write formatted data to string (function ) | |
sscanf |
Read formatted data from string (function ) | |
vfprintf |
Write formatted data from variable argument list to stream (function ) | |
vfscanf |
Read formatted data from stream into variable argument list (function ) | |
vprintf |
Print formatted data from variable argument list to stdout (function ) | |
vscanf |
Read formatted data into variable argument list (function ) | |
vsnprintf |
Write formatted data from variable argument list to sized buffer (function ) | |
vsprintf |
Write formatted data from variable argument list to string (function ) | |
vsscanf |
Read formatted data from string into variable argument list (function ) |
Character input/output: fgetc Get character from stream (function ) fgets Get string from stream (function ) fputc Write character to stream (function ) fputs Write string to stream (function ) getc Get character from stream (function ) getchar Get character from stdin (function ) gets Get string from stdin (function ) putc Write character to stream (function ) putchar Write character to stdout (function ) puts Write string to stdout (function ) ungetc Unget character from stream (function )
Direct input/output: fread Read block of data from stream (function ) fwrite Write block of data to stream (function )
File positioning: fgetpos Get current position in stream (function ) fseek Reposition stream position indicator (function ) fsetpos Set position indicator of stream (function ) ftell Get current position in stream (function ) rewind Set position of stream to the beginning (function )
Error-handling: clearerr Clear error indicators (function ) feof Check end-of-file indicator (function ) ferror Check error indicator (function ) perror Print error message (function )
Macros BUFSIZ Buffer size (constant ) EOF End-of-File (constant ) FILENAME_MAX Maximum length of file names (constant ) FOPEN_MAX Potential limit of simultaneous open streams (constant ) L_tmpnam Minimum length for temporary file name (constant ) NULL Null pointer (macro ) TMP_MAX Number of temporary files (constant ) Additionally: _IOFBF, _IOLBF, _IONBF (used with setvbuf) and SEEK_CUR, SEEK_END and SEEK_SET (used with fseek).
Types FILE Object containing information to control a stream (type ) fpos_t Object containing information to specify a position within a file (type ) size_t Unsigned integral type (type )
A format specifier follows this prototype: %[flags][width][.precision][length]specifier
| specifier | Output | Example |
|---|---|---|
d or i |
Signed decimal integer | 392 |
u |
Unsigned decimal integer | 7235 |
o |
Unsigned octal | 610 |
x |
Unsigned hexadecimal integer | 7fa |
X |
Unsigned hexadecimal integer (uppercase) | 7FA |
f |
Decimal floating point, lowercase | 392.65 |
F |
Decimal floating point, uppercase | 392.65 |
e |
Scientific notation (mantissa/exponent), lowercase | 3.9265e+2 |
E |
Scientific notation (mantissa/exponent), uppercase | 3.9265E+2 |
g |
Use the shortest representation: %e or %f | 392.65 |
G |
Use the shortest representation: %E or %F | 392.65 |
a |
Hexadecimal floating point, lowercase | -0xc.90fep-2 |
A |
Hexadecimal floating point, uppercase | -0XC.90FEP-2 |
c |
Character | a |
s |
String of characters | sample |
p |
Pointer address | b8000000 |
n |
Nothing printed. |
| flags | description |
|---|---|
- |
Left-justify within the given field width; Right justification is the default (see width sub-specifier). |
+ |
Forces to preceed the result with a plus or minus sign (+ or -) even for positive numbers. By default, only negative numbers are preceded with a - sign. |
| (space) | If no sign is going to be written, a blank space is inserted before the value. |
Used with o, x or X specifiers the value is preceeded with 0, 0x or 0X respectively for values different than zero.
Used with a, A, e, E, f, F, g or G it forces the written output to contain a decimal point even if no more digits follow. By default, if no digits follow, no decimal point is written. 0 Left-pads the number with zeroes (0) instead of spaces when padding is specified (see width sub-specifier).
width description (number) Minimum number of characters to be printed. If the value to be printed is shorter than this number, the result is padded with blank spaces. The value is not truncated even if the result is larger. * The width is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted.
.precision description .number For integer specifiers (d, i, o, u, x, X): precision specifies the minimum number of digits to be written. If the value to be written is shorter than this number, the result is padded with leading zeros. The value is not truncated even if the result is longer. A precision of 0 means that no character is written for the value 0. For a, A, e, E, f and F specifiers: this is the number of digits to be printed after the decimal point (by default, this is 6). For g and G specifiers: This is the maximum number of significant digits to be printed. For s: this is the maximum number of characters to be printed. By default all characters are printed until the ending null character is encountered. If the period is specified without an explicit value for precision, 0 is assumed. .* The precision is not specified in the format string, but as an additional integer value argument preceding the argument that has to be formatted.
The length sub-specifier modifies the length of the data type. This is a chart showing the types used to interpret the corresponding arguments with and without length specifier (if a different type is used, the proper type promotion or conversion is performed, if allowed): specifiers length d i u o x X f F e E g G a A c s p n (none) int unsigned int double int char void int hh signed char unsigned char signed char h short int unsigned short int short int l long int unsigned long int wint_t wchar_t long int ll long long int unsigned long long int long long int j intmax_t uintmax_t intmax_t z size_t size_t size_t t ptrdiff_t ptrdiff_t ptrdiff_t* L long double
4.2 thread库
- thread类
数据
| 数据 | 说明 |
|---|---|
id |
表示线程的id |
native_handle_type |
返回底层实现定义的线程句柄 |
函数
| 函数 | 说明 | 用法 |
|---|---|---|
(constructor) |
构造新的thread对象 | explicit thread (Fn&& fn, Args&&... args);,thread() noexcept; |
(destructor) |
析构thread对象,必须合并或分离底层线程 | |
operator= |
移动thread对象 | thread& operator= (thread&& rhs) noexcept; |
get_id |
返回线程的id | id get_id() const noexcept; |
joinable |
检查线程是否可合并,即潜在地运行于平行环境中 | bool joinable() const noexcept; |
join |
等待线程完成其执行 | void join(); |
detach |
容许线程从线程句柄独立开来执行 | void detach(); |
swap |
交换二个thread对象 | void swap (thread& x) noexcept; |
native_handle |
返回底层实现定义的线程句柄 | native_handle_type native_handle(); |
hardware_concurrency |
返回实现支持的并发线程数 | static unsigned hardware_concurrency() noexcept; |
非成员函数
| 函数 | 说明 | 用法 |
|---|---|---|
swap |
特化std::swap算法 | void swap (thread& x, thread& y) noexcept; |
// thread example
#include <iostream> // std::cout
#include <thread> // std::thread
void foo() {
// do stuff...
}
void bar(int x) {
// do stuff...
}
int main() {
std::thread first (foo); // spawn new thread that calls foo()
std::thread second (bar,0); // spawn new thread that calls bar(0)
std::cout << "main, foo and bar now execute concurrently...\n";
// synchronize threads:
first.join(); // pauses until first finishes
second.join(); // pauses until second finishes
std::cout << "foo and bar completed.\n";
return 0;
}
- this_thread命名空间
| 函数 | 说明 | 用法 |
|---|---|---|
get_id |
返回当前线程的线程id | thread::id get_id() noexcept; |
yield |
建议实现重新调度各执行线程 | void yield() noexcept; |
sleep_until |
使当前线程的执行停止直到指定的时间点 | void sleep_until (const chrono::time_point<Clock,Duration>& abs_time); |
| Sleep until time point (function ) | ||
sleep_for |
使当前线程的执行停止指定的时间段 | void sleep_for (const chrono::duration<Rep,Period>& rel_time); |
// this_thread::sleep_for example
#include <iostream> // std::cout, std::endl
#include <thread> // std::this_thread::sleep_for
#include <chrono> // std::chrono::seconds
int main() {
std::cout << "countdown:\n";
for (int i=10; i>0; --i) {
std::cout << i << std::endl;
std::this_thread::sleep_for (std::chrono::seconds(1));
}
std::cout << "Lift off!\n";
return 0;
}
https://zh.cppreference.com/w/c/header
五、Cblas库
CBLAS是BLAS的C语言接口。BLAS的全称是Basic Linear Algebra Subprograms,中文大概可以叫做基础线性代数子程序。主要是用于向量和矩阵计算的高性能数学库。本身BLAS是用Fortran写的,为了方便C/C++程序的使用,就有了BLAS的C接口库CBLAS。BLAS的主页是http://www.netlib.org/blas/,CBLAS的下载地址也可以在这个页面上找到。
CBLAS/BLAS分为3个level:
Level1:处理单一向量的线性运算以及两个向量的二元运算,接口函数名称由前缀+操作简称组成。(如:SROTG中S标明矩阵或向量中元素数据类型的前缀,ROTG表明向量运算简称)
Level2:处理矩阵与向量的运算,同时也包含线性方程求解计算,
Level3:包含矩阵与矩阵运算。Level2和Level3接口函数由前缀+矩阵类型+操作简称组成。(如:SGEMV中S标明矩阵或向量中元素数据类型的前缀,GE为矩阵类型,MV为向量或矩阵运算简称。

数据精度有如下几种:
| 标识 | 说明 |
|---|---|
| S | single real |
| D | double real |
| C | single complex |
| Z | double complex |
操作类型有下面常见的几种:
| 标识 | 说明 |
|---|---|
| DOT | scalar product, x^T y |
| AXPY | vector sum, /alpha x + y |
| MV | matrix-vector product, A x |
| SV | matrix-vector solve, inv(A) x |
| MM | matrix-matrix product, A B |
| SM | matrix-matrix solve, inv(A) B |
| 矩阵的类型有下面常见的几种: |
| 标识 | 说明 |
|---|---|
| GE | Genearl,稠密矩阵 |
| GB | General Band,带状矩阵 |
| SY | SYmmetric,对称矩阵 |
| SB | Symmetric Band,对称带状矩阵 |
| SP | Symmetric Packed,压缩存储对称矩阵 |
| HE | HEmmitian,Hemmitian矩阵,自共轭矩阵 |
| HB | Hemmitian Band,带状Hemmitian矩阵 |
| HP | Hemmitian Packed,压缩存储Hemmitian矩阵 |
| TR | TRiangular,三角矩阵 |
| TB | Triangular Band,三角带状矩阵 |
| TP | Triangular Packed,压缩存储三角矩阵 |
六、指令集
6.1 AVX编程基础
- 数据类型
| 数据类型 | 描述 |
|---|---|
| __m128 | 包含4个float类型数字的向量 |
| __m128d | 包含2个double类型数字的向量 |
| __m128i | 包含若干个整型数字的向量 |
| __m256 | 包含8个float类型数字的向量 |
| __m256d | 包含4个double类型数字的向量 |
| __m256i | 包含若干个整型数字的向量 |
每一种类型,从2个下划线开头,接一个m,然后是vector的位长度。如果向量类型是以d结束的,那么向量里面是double类型的数字。如果没有后缀,就代表向量只包含float类型的数字。整形的向量可以包含各种类型的整形数,例如char,short,unsigned long long。也就是说,__m256i可以包含32个char,16个short类型,8个int类型,4个long类型。这些整形数可以是有符号类型也可以是无符号类型。
函数命名约定:_mm<bit_width>_<name>_<data_type>
<bit_width>:表明了向量的位长度,对于128位的向量,这个参数为空,对于256位的向量,这个参数为256。
<name>:描述了内联函数的算术操作。
<data_type>:标识函数主参数的数据类型。ps:包含float类型的向量
pd:包含double类型的向量
epi8/epi16/epi32/epi64:包含8位/16位/32位/64位的有符号整数
epu8/epu16/epu32/epu64:包含8位/16位/32位/64位的无符号整数
si128/si256:未指定的128位或者256位向量
m128/m128i/m128d/m256/m256i/m256d:当输入向量类型与返回向量的类型不同时,标识输入向量类型
immintrin.h为AVX头文件,此头文件里包含AES头文件,其中__m256、__m256d、__m256i的定义为:
typedef union __declspec(intrin_type) _CRT_ALIGN(32) __m256 {
float m256_f32[8];
} __m256;
typedef struct __declspec(intrin_type) _CRT_ALIGN(32) {
double m256d_f64[4];
} __m256d;
typedef union __declspec(intrin_type) _CRT_ALIGN(32) __m256i {
__int8 m256i_i8[32];
__int16 m256i_i16[16];
__int32 m256i_i32[8];
__int64 m256i_i64[4];
unsigned __int8 m256i_u8[32];
unsigned __int16 m256i_u16[16];
unsigned __int32 m256i_u32[8];
unsigned __int64 m256i_u64[4];
} __m256i;
| 头文件 | 指令集 | 数据结构 | 字节对齐 |
|---|---|---|---|
| mmintrin.h | MMX | __m64 | 8字节对齐 |
| xmmintrin.h | SSE | __m128 | 16字节对齐 |
| emmintrin.h | SSE2 | __m128i __m128d | 16字节对齐 |
| immintrin.h | AVX | __m256 __m256i __m256d | 32字节对齐 |
immintrin.h文件中各函数的介绍:
/*
* Add Packed Double Precision Floating-Point Values
* **** VADDPD ymm1, ymm2, ymm3/m256
* Performs an SIMD add of the four packed double-precision floating-point
* values from the first source operand to the second source operand, and
* stores the packed double-precision floating-point results in the
* destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10+m20, r1=m11+m21, r2=m12+m22, r3=m13+m23
extern __m256d __cdecl _mm256_add_pd(__m256d m1, __m256d m2);
/*
* Add Packed Single Precision Floating-Point Values
* **** VADDPS ymm1, ymm2, ymm3/m256
* Performs an SIMD add of the eight packed single-precision floating-point
* values from the first source operand to the second source operand, and
* stores the packed single-precision floating-point results in the
* destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=m10+m20, r1=m11+m21, ..., r7=m17+m27
extern __m256 __cdecl _mm256_add_ps(__m256 m1, __m256 m2);
/*
* Add/Subtract Double Precision Floating-Point Values
* **** VADDSUBPD ymm1, ymm2, ymm3/m256
* Adds odd-numbered double-precision floating-point values of the first
* source operand with the corresponding double-precision floating-point
* values from the second source operand; stores the result in the odd-numbered
* values of the destination. Subtracts the even-numbered double-precision
* floating-point values from the second source operand from the corresponding
* double-precision floating values in the first source operand; stores the
* result into the even-numbered values of the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10-m20, r1=m11+m21, r2=m12-m22, r3=m13-m23
extern __m256d __cdecl _mm256_addsub_pd(__m256d m1, __m256d m2);
/*
* Add/Subtract Packed Single Precision Floating-Point Values
* **** VADDSUBPS ymm1, ymm2, ymm3/m256
* Adds odd-numbered single-precision floating-point values of the first source
* operand with the corresponding single-precision floating-point values from
* the second source operand; stores the result in the odd-numbered values of
* the destination. Subtracts the even-numbered single-precision floating-point
* values from the second source operand from the corresponding
* single-precision floating values in the first source operand; stores the
* result into the even-numbered values of the destination
*/
//m1=(m10, m11, m12, m13, ..., m17), m2=(m20, m21, m22, m23, ..., m27)
//则r0=m10-m20, r1=m11+m21, ... , r6=m16-m26, r7=m17+m27
extern __m256 __cdecl _mm256_addsub_ps(__m256 m1, __m256 m2);
/*
* Bitwise Logical AND of Packed Double Precision Floating-Point Values
* **** VANDPD ymm1, ymm2, ymm3/m256
* Performs a bitwise logical AND of the four packed double-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=(m10 & m20), r1=(m11 & m21), r2=(m12 & m22), r3=(m13 & m23)
extern __m256d __cdecl _mm256_and_pd(__m256d m1, __m256d m2);
/*
* Bitwise Logical AND of Packed Single Precision Floating-Point Values
* **** VANDPS ymm1, ymm2, ymm3/m256
* Performs a bitwise logical AND of the eight packed single-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//m1=(m10, m11, m12, m13, ..., m17), m2=(m20, m21, m22, m23, ..., m27)
//则r0=(m10 & m20), r1=(m11 & m21), ..., r6=(m16 & m26), r7=(m17 & m27)
extern __m256 __cdecl _mm256_and_ps(__m256 m1, __m256 m2);
/*
* Bitwise Logical AND NOT of Packed Double Precision Floating-Point Values
* **** VANDNPD ymm1, ymm2, ymm3/m256
* Performs a bitwise logical AND NOT of the four packed double-precision
* floating-point values from the first source operand and the second source
* operand, and stores the result in the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=(~m10) & m20, r1=(~m11) & m21, r2=(~m12) & m22, r3=(~m13) & m23
extern __m256d __cdecl _mm256_andnot_pd(__m256d m1, __m256d m2);
/*
* Bitwise Logical AND NOT of Packed Single Precision Floating-Point Values
* **** VANDNPS ymm1, ymm2, ymm3/m256
* Performs a bitwise logical AND NOT of the eight packed single-precision
* floating-point values from the first source operand and the second source
* operand, and stores the result in the destination
*/
//m1=(m10, m11, m12, m13, ..., m17), m2=(m20, m21, m22, m23, ..., m27)
//则r0=(~m10) & m20, r1=(~m11) & m21), ..., r6=(~m16) & m26, r7=(~m17) & m27
extern __m256 __cdecl _mm256_andnot_ps(__m256 m1, __m256 m2);
/*
* Blend Packed Double Precision Floating-Point Values
* **** VBLENDPD ymm1, ymm2, ymm3/m256, imm8
* Double-Precision Floating-Point values from the second source operand are
* conditionally merged with values from the first source operand and written
* to the destination. The immediate bits [3:0] determine whether the
* corresponding Double-Precision Floating Point value in the destination is
* copied from the second source or first source. If a bit in the mask,
* orresponding to a word, is "1", then the Double-Precision Floating-Point
* value in the second source operand is copied, else the value in the first
* source operand is copied
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23), mask=[b3 b2 b1 b0]
//如果bn=1,则rn=m2n,如果bn=0, 则rn=m1n, 其中n为0,1,2,3
extern __m256d __cdecl _mm256_blend_pd(__m256d m1, __m256d m2, const int mask);
/*
* Blend Packed Single Precision Floating-Point Values
* **** VBLENDPS ymm1, ymm2, ymm3/m256, imm8
* Single precision floating point values from the second source operand are
* conditionally merged with values from the first source operand and written
* to the destination. The immediate bits [7:0] determine whether the
* corresponding single precision floating-point value in the destination is
* copied from the second source or first source. If a bit in the mask,
* corresponding to a word, is "1", then the single-precision floating-point
* value in the second source operand is copied, else the value in the first
* source operand is copied
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27),mask=[b7 b6...b1 b0]
//如果bn=1,则rn=m2n,如果bn=0, 则rn=m1n, 其中n为0,1,2,3,4,5,6,7
extern __m256 __cdecl _mm256_blend_ps(__m256 m1, __m256 m2, const int mask);
/*
* Blend Packed Double Precision Floating-Point Values
* **** VBLENDVPD ymm1, ymm2, ymm3/m256, ymm4
* Conditionally copy each quadword data element of double-precision
* floating-point value from the second source operand (third operand) and the
* first source operand (second operand) depending on mask bits defined in the
* mask register operand (fourth operand).
*/
extern __m256d __cdecl _mm256_blendv_pd(__m256d m1, __m256d m2, __m256d m3);
/*
* Blend Packed Single Precision Floating-Point Values
* **** VBLENDVPS ymm1, ymm2, ymm3/m256, ymm4
* Conditionally copy each dword data element of single-precision
* floating-point value from the second source operand (third operand) and the
* first source operand (second operand) depending on mask bits defined in the
* mask register operand (fourth operand).
*/
extern __m256 __cdecl _mm256_blendv_ps(__m256 m1, __m256 m2, __m256 mask);
/*
* Divide Packed Double-Precision Floating-Point Values
* **** VDIVPD ymm1, ymm2, ymm3/m256
* Performs an SIMD divide of the four packed double-precision floating-point
* values in the first source operand by the four packed double-precision
* floating-point values in the second source operand
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10/m20, r1=m11/m21, r2=m12/m22, r3=m13/m23
extern __m256d __cdecl _mm256_div_pd(__m256d m1, __m256d m2);
/*
* Divide Packed Single-Precision Floating-Point Values
* **** VDIVPS ymm1, ymm2, ymm3/m256
* Performs an SIMD divide of the eight packed single-precision
* floating-point values in the first source operand by the eight packed
* single-precision floating-point values in the second source operand
*/
//m1=(m10, m11, m12, m13, ..., m17), m2=(m20, m21, m22, m23, ..., m27)
//则r0=m10/m20, r1=m11/m21, ..., r6=m16/m26, r7=m17/m27
extern __m256 __cdecl _mm256_div_ps(__m256 m1, __m256 m2);
/*
* Dot Product of Packed Single-Precision Floating-Point Values
* **** VDPPS ymm1, ymm2, ymm3/m256, imm8
* Multiplies the packed single precision floating point values in the
* first source operand with the packed single-precision floats in the
* second source. Each of the four resulting single-precision values is
* conditionally summed depending on a mask extracted from the high 4 bits
* of the immediate operand. This sum is broadcast to each of 4 positions
* in the destination if the corresponding bit of the mask selected from
* the low 4 bits of the immediate operand is "1". If the corresponding
* low bit 0-3 of the mask is zero, the destination is set to zero.
* The process is replicated for the high elements of the destination.
*/
//m1=(m10, m11, m12, m13, ..., m17), m2=(m20, m21, m22, m23, ..., m27)
//mask=[b7 b6 ... b0], mask的低四位决定结果值是0,还是m1和m2相应位相乘后再求和
//若b0b1b2b3为0001,则r0=r1=r2=0,m4=m5=m6=0,此时如果b4b5b6b7为1001,
//则r3=m10*m20+m13*m23, r7=m14*m24+m17*m27,其它依次类推
extern __m256 __cdecl _mm256_dp_ps(__m256 m1, __m256 m2, const int mask);
/*
* Add Horizontal Double Precision Floating-Point Values
* **** VHADDPD ymm1, ymm2, ymm3/m256
* Adds pairs of adjacent double-precision floating-point values in the
* first source operand and second source operand and stores results in
* the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10+m11, r1=m20+m21, r2=m12+m13, r3=m22+m23
extern __m256d __cdecl _mm256_hadd_pd(__m256d m1, __m256d m2);
/*
* Add Horizontal Single Precision Floating-Point Values
* **** VHADDPS ymm1, ymm2, ymm3/m256
* Adds pairs of adjacent single-precision floating-point values in the
* first source operand and second source operand and stores results in
* the destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=m10+m11, r1=m12+m13, r2=m20+m21, r3=m22+m23,
//r4=m14+m15, r5=m16+m17, r6=m24+m25, r7=m26+m27
extern __m256 __cdecl _mm256_hadd_ps(__m256 m1, __m256 m2);
/*
* Subtract Horizontal Double Precision Floating-Point Values
* **** VHSUBPD ymm1, ymm2, ymm3/m256
* Subtract pairs of adjacent double-precision floating-point values in
* the first source operand and second source operand and stores results
* in the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10-m11, r1=m20-m21, r2=m12-m13, r3=m22-m23
extern __m256d __cdecl _mm256_hsub_pd(__m256d m1, __m256d m2);
/*
* Subtract Horizontal Single Precision Floating-Point Values
* **** VHSUBPS ymm1, ymm2, ymm3/m256
* Subtract pairs of adjacent single-precision floating-point values in
* the first source operand and second source operand and stores results
* in the destination.
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=m10-m11, r1=m12-m13, r2=m20-m21, r3=m22-m23,
//r4=m14-m15, r5=m16-m17, r6=m24-m25, r7=m26-m27
extern __m256 __cdecl _mm256_hsub_ps(__m256 m1, __m256 m2);
/*
* Maximum of Packed Double Precision Floating-Point Values
* **** VMAXPD ymm1, ymm2, ymm3/m256
* Performs an SIMD compare of the packed double-precision floating-point
* values in the first source operand and the second source operand and
* returns the maximum value for each pair of values to the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=max(m10,m20), r1=max(m11,m21), r2=max(m12,m22), r3=max(m13,m23)
extern __m256d __cdecl _mm256_max_pd(__m256d m1, __m256d m2);
/*
* Maximum of Packed Single Precision Floating-Point Values
* **** VMAXPS ymm1, ymm2, ymm3/m256
* Performs an SIMD compare of the packed single-precision floating-point
* values in the first source operand and the second source operand and
* returns the maximum value for each pair of values to the destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=max(m10,m20), r1=max(m11,m21), ..., r6=max(m16,m26), r7=max(m17,m27)
extern __m256 __cdecl _mm256_max_ps(__m256 m1, __m256 m2);
/*
* Minimum of Packed Double Precision Floating-Point Values
* **** VMINPD ymm1, ymm2, ymm3/m256
* Performs an SIMD compare of the packed double-precision floating-point
* values in the first source operand and the second source operand and
* returns the minimum value for each pair of values to the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=min(m10,m20), r1=min(m11,m21), r2=min(m12,m22), r3=min(m13,m23)
extern __m256d __cdecl _mm256_min_pd(__m256d m1, __m256d m2);
/*
* Minimum of Packed Single Precision Floating-Point Values
* **** VMINPS ymm1, ymm2, ymm3/m256
* Performs an SIMD compare of the packed single-precision floating-point
* values in the first source operand and the second source operand and
* returns the minimum value for each pair of values to the destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=min(m10,m20), r1=min(m11,m21), ..., r6=min(m16,m26), r7=min(m17,m27)
extern __m256 __cdecl _mm256_min_ps(__m256 m1, __m256 m2);
/*
* Multiply Packed Double Precision Floating-Point Values
* **** VMULPD ymm1, ymm2, ymm3/m256
* Performs a SIMD multiply of the four packed double-precision floating-point
* values from the first Source operand to the Second Source operand, and
* stores the packed double-precision floating-point results in the
* destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10*m20, r1=m11*m21, r2=m12*m22, r3=m13*m23
extern __m256d __cdecl _mm256_mul_pd(__m256d m1, __m256d m2);
/*
* Multiply Packed Single Precision Floating-Point Values
* **** VMULPS ymm1, ymm2, ymm3/m256
* Performs an SIMD multiply of the eight packed single-precision
* floating-point values from the first source operand to the second source
* operand, and stores the packed double-precision floating-point results in
* the destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=m10*m20, r1=m11*m21, ..., r6=m16*m26, r7=m17*m27
extern __m256 __cdecl _mm256_mul_ps(__m256 m1, __m256 m2);
/*
* Bitwise Logical OR of Packed Double Precision Floating-Point Values
* **** VORPD ymm1, ymm2, ymm3/m256
* Performs a bitwise logical OR of the four packed double-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//注意:有时得到的结果并不是m1和m2按位或的结果?
extern __m256d __cdecl _mm256_or_pd(__m256d m1, __m256d m2);
/*
* Bitwise Logical OR of Packed Single Precision Floating-Point Values
* **** VORPS ymm1, ymm2, ymm3/m256
* Performs a bitwise logical OR of the eight packed single-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//注意:有时得到的结果并不是m1和m2按位或的结果?
extern __m256 __cdecl _mm256_or_ps(__m256 m1, __m256 m2);
/*
* Shuffle Packed Double Precision Floating-Point Values
* **** VSHUFPD ymm1, ymm2, ymm3/m256, imm8
* Moves either of the two packed double-precision floating-point values from
* each double quadword in the first source operand into the low quadword
* of each double quadword of the destination; moves either of the two packed
* double-precision floating-point values from the second source operand into
* the high quadword of each double quadword of the destination operand.
* The selector operand determines which values are moved to the destination
*/
extern __m256d __cdecl _mm256_shuffle_pd(__m256d m1, __m256d m2, const int select);
/*
* Shuffle Packed Single Precision Floating-Point Values
* **** VSHUFPS ymm1, ymm2, ymm3/m256, imm8
* Moves two of the four packed single-precision floating-point values
* from each double qword of the first source operand into the low
* quadword of each double qword of the destination; moves two of the four
* packed single-precision floating-point values from each double qword of
* the second source operand into to the high quadword of each double qword
* of the destination. The selector operand determines which values are moved
* to the destination.
*/
extern __m256 __cdecl _mm256_shuffle_ps(__m256 m1, __m256 m2, const int select);
/*
* Subtract Packed Double Precision Floating-Point Values
* **** VSUBPD ymm1, ymm2, ymm3/m256
* Performs an SIMD subtract of the four packed double-precision floating-point
* values of the second Source operand from the first Source operand, and
* stores the packed double-precision floating-point results in the destination
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r0=m10-m20, r1=m11-m21, r2=m12-m22, r3=m13-m23
extern __m256d __cdecl _mm256_sub_pd(__m256d m1, __m256d m2);
/*
* Subtract Packed Single Precision Floating-Point Values
* **** VSUBPS ymm1, ymm2, ymm3/m256
* Performs an SIMD subtract of the eight packed single-precision
* floating-point values in the second Source operand from the First Source
* operand, and stores the packed single-precision floating-point results in
* the destination
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r0=m10-m20, r1=m11-m21, ..., r6=m16-m26, r7=m17-m27
extern __m256 __cdecl _mm256_sub_ps(__m256 m1, __m256 m2);
/*
* Bitwise Logical XOR of Packed Double Precision Floating-Point Values
* **** VXORPD ymm1, ymm2, ymm3/m256
* Performs a bitwise logical XOR of the four packed double-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//注意:有时得到的结果并不是m1和m2按位异或的结果?
extern __m256d __cdecl _mm256_xor_pd(__m256d m1, __m256d m2);
/*
* Bitwise Logical XOR of Packed Single Precision Floating-Point Values
* **** VXORPS ymm1, ymm2, ymm3/m256
* Performs a bitwise logical XOR of the eight packed single-precision
* floating-point values from the first source operand and the second
* source operand, and stores the result in the destination
*/
//注意:有时得到的结果并不是m1和m2按位异或的结果?
extern __m256 __cdecl _mm256_xor_ps(__m256 m1, __m256 m2);
/*
* Compare Packed Double-Precision Floating-Point Values
* **** VCMPPD xmm1, xmm2, xmm3/m128, imm8
* **** VCMPPD ymm1, ymm2, ymm3/m256, imm8
* Performs an SIMD compare of the four packed double-precision floating-point
* values in the second source operand (third operand) and the first source
* operand (second operand) and returns the results of the comparison to the
* destination operand (first operand). The comparison predicate operand
* (immediate) specifies the type of comparison performed on each of the pairs
* of packed values.
* For 128-bit intrinsic with compare predicate values in range 0-7 compiler
* may generate SSE2 instructions if it is warranted for performance reasons.
*/
extern __m128d __cdecl _mm_cmp_pd(__m128d m1, __m128d m2, const int predicate);
extern __m256d __cdecl _mm256_cmp_pd(__m256d m1, __m256d m2, const int predicate);
/*
* Compare Packed Single-Precision Floating-Point Values
* **** VCMPPS xmm1, xmm2, xmm3/m256, imm8
* **** VCMPPS ymm1, ymm2, ymm3/m256, imm8
* Performs a SIMD compare of the packed single-precision floating-point values
* in the second source operand (third operand) and the first source operand
* (second operand) and returns the results of the comparison to the destination
* operand (first operand). The comparison predicate operand (immediate)
* specifies the type of comparison performed on each of the pairs of packed
* values.
* For 128-bit intrinsic with compare predicate values in range 0-7 compiler
* may generate SSE2 instructions if it is warranted for performance reasons.
*/
extern __m128 __cdecl _mm_cmp_ps(__m128 m1, __m128 m2, const int predicate);
extern __m256 __cdecl _mm256_cmp_ps(__m256 m1, __m256 m2, const int predicate);
/*
* Compare Scalar Double-Precision Floating-Point Values
* **** VCMPSD xmm1, xmm2, xmm3/m64, imm8
* Compares the low double-precision floating-point values in the second source
* operand (third operand) and the first source operand (second operand) and
* returns the results in of the comparison to the destination operand (first
* operand). The comparison predicate operand (immediate operand) specifies the
* type of comparison performed.
* For compare predicate values in range 0-7 compiler may generate SSE2
* instructions if it is warranted for performance reasons.
*/
extern __m128d __cdecl _mm_cmp_sd(__m128d m1, __m128d m2, const int predicate);
/*
* Compare Scalar Single-Precision Floating-Point Values
* **** VCMPSS xmm1, xmm2, xmm3/m64, imm8
* Compares the low single-precision floating-point values in the second source
* operand (third operand) and the first source operand (second operand) and
* returns the results of the comparison to the destination operand (first
* operand). The comparison predicate operand (immediate operand) specifies
* the type of comparison performed.
* For compare predicate values in range 0-7 compiler may generate SSE2
* instructions if it is warranted for performance reasons.
*/
extern __m128 __cdecl _mm_cmp_ss(__m128 m1, __m128 m2, const int predicate);
/*
* Convert Packed Doubleword Integers to
* Packed Double-Precision Floating-Point Values
* **** VCVTDQ2PD ymm1, xmm2/m128
* Converts four packed signed doubleword integers in the source operand to
* four packed double-precision floating-point values in the destination
*/
//从__int32类型转换到double类型
extern __m256d __cdecl _mm256_cvtepi32_pd(__m128i m1);
/*
* Convert Packed Doubleword Integers to
* Packed Single-Precision Floating-Point Values
* **** VCVTDQ2PS ymm1, ymm2/m256
* Converts eight packed signed doubleword integers in the source operand to
* eight packed double-precision floating-point values in the destination
*/
//从__int32类型转换到float类型
extern __m256 __cdecl _mm256_cvtepi32_ps(__m256i m1);
/*
* Convert Packed Double-Precision Floating-point values to
* Packed Single-Precision Floating-Point Values
* **** VCVTPD2PS xmm1, ymm2/m256
* Converts four packed double-precision floating-point values in the source
* operand to four packed single-precision floating-point values in the
* destination
*/
//从double类型转换到float类型
extern __m128 __cdecl _mm256_cvtpd_ps(__m256d m1);
/*
* Convert Packed Single Precision Floating-Point Values to
* Packed Singed Doubleword Integer Values
* **** VCVTPS2DQ ymm1, ymm2/m256
* Converts eight packed single-precision floating-point values in the source
* operand to eight signed doubleword integers in the destination
*/
//从float类型转换到__int32类型
extern __m256i __cdecl _mm256_cvtps_epi32(__m256 m1);
/*
* Convert Packed Single Precision Floating-point values to
* Packed Double Precision Floating-Point Values
* **** VCVTPS2PD ymm1, xmm2/m128
* Converts four packed single-precision floating-point values in the source
* operand to four packed double-precision floating-point values in the
* destination
*/
//从float类型转换到double类型
extern __m256d __cdecl _mm256_cvtps_pd(__m128 m1);
/*
* Convert with Truncation Packed Double-Precision Floating-Point values to
* Packed Doubleword Integers
* **** VCVTTPD2DQ xmm1, ymm2/m256
* Converts four packed double-precision floating-point values in the source
* operand to four packed signed doubleword integers in the destination.
* When a conversion is inexact, a truncated (round toward zero) value is
* returned. If a converted result is larger than the maximum signed doubleword
* integer, the floating-point invalid exception is raised, and if this
* exception is masked, the indefinite integer value (80000000H) is returned
*/
//从double类型转换到__int32类型,truncated
extern __m128i __cdecl _mm256_cvttpd_epi32(__m256d m1);
/*
* Convert Packed Double-Precision Floating-point values to
* Packed Doubleword Integers
* **** VCVTPD2DQ xmm1, ymm2/m256
* Converts four packed double-precision floating-point values in the source
* operand to four packed signed doubleword integers in the destination
*/
//从double类型转换到__int32类型
extern __m128i __cdecl _mm256_cvtpd_epi32(__m256d m1);
/*
* Convert with Truncation Packed Single Precision Floating-Point Values to
* Packed Singed Doubleword Integer Values
* **** VCVTTPS2DQ ymm1, ymm2/m256
* Converts eight packed single-precision floating-point values in the source
* operand to eight signed doubleword integers in the destination.
* When a conversion is inexact, a truncated (round toward zero) value is
* returned. If a converted result is larger than the maximum signed doubleword
* integer, the floating-point invalid exception is raised, and if this
* exception is masked, the indefinite integer value (80000000H) is returned
*/
//从float类型转换到__int32类型,truncated
extern __m256i __cdecl _mm256_cvttps_epi32(__m256 m1);
/*
* Extract packed floating-point values
* **** VEXTRACTF128 xmm1/m128, ymm2, imm8
* Extracts 128-bits of packed floating-point values from the source operand
* at an 128-bit offset from imm8[0] into the destination
*/
//offset:a constant integer value that represents the 128-bit offset from
//where extraction must start
//从256位中提取128位,offset决定提取的起始位置
extern __m128 __cdecl _mm256_extractf128_ps(__m256 m1, const int offset);
extern __m128d __cdecl _mm256_extractf128_pd(__m256d m1, const int offset);
extern __m128i __cdecl _mm256_extractf128_si256(__m256i m1, const int offset);
/*
* Zero All YMM registers
* **** VZEROALL
* Zeros contents of all YMM registers
*/
extern void __cdecl _mm256_zeroall(void);
/*
* Zero Upper bits of YMM registers
* **** VZEROUPPER
* Zeros the upper 128 bits of all YMM registers. The lower 128-bits of the
* registers (the corresponding XMM registers) are unmodified
*/
extern void __cdecl _mm256_zeroupper(void);
/*
* Permute Single-Precision Floating-Point Values
* **** VPERMILPS ymm1, ymm2, ymm3/m256
* **** VPERMILPS xmm1, xmm2, xmm3/m128
* Permute Single-Precision Floating-Point values in the first source operand
* using 8-bit control fields in the low bytes of corresponding elements the
* shuffle control and store results in the destination
*/
//control:a vector with 2-bit control fields, one for each corresponding element
//of the source vector, for the 256-bit m1 source vector this control vector
//contains eight 2-bit control fields,for the 128-bit m1 source vector this
//control vector contains four 2-bit control fields
extern __m256 __cdecl _mm256_permutevar_ps(__m256 m1, __m256i control);
extern __m128 __cdecl _mm_permutevar_ps(__m128 a, __m128i control);
/*
* Permute Single-Precision Floating-Point Values
* **** VPERMILPS ymm1, ymm2/m256, imm8
* **** VPERMILPS xmm1, xmm2/m128, imm8
* Permute Single-Precision Floating-Point values in the first source operand
* using four 2-bit control fields in the 8-bit immediate and store results
* in the destination
*/
//control:an integer specified as an 8-bit immediate;for the 256-bit m1 vector
//this integer contains four 2-bit control fields in the low 8 bits of
//the immediate, for the 128-bit m1 vector this integer contains two 2-bit
//control fields in the low 4 bits of the immediate
extern __m256 __cdecl _mm256_permute_ps(__m256 m1, int control);
extern __m128 __cdecl _mm_permute_ps(__m128 a, int control);
/*
* Permute Double-Precision Floating-Point Values
* **** VPERMILPD ymm1, ymm2, ymm3/m256
* **** VPERMILPD xmm1, xmm2, xmm3/m128
* Permute Double-Precision Floating-Point values in the first source operand
* using 8-bit control fields in the low bytes of the second source operand
* and store results in the destination
*/
//control:a vector with 1-bit control fields, one for each corresponding element
//of the source vector, for the 256-bit m1 source vector this control vector
//contains four 1-bit control fields in the low 4 bits of the immediate, for the
//128-bit m1 source vector this control vector contains two 1-bit control fields
//in the low 2 bits of the immediate
extern __m256d __cdecl _mm256_permutevar_pd(__m256d m1, __m256i control);
extern __m128d __cdecl _mm_permutevar_pd(__m128d a, __m128i control);
/*
* Permute Double-Precision Floating-Point Values
* **** VPERMILPD ymm1, ymm2/m256, imm8
* **** VPERMILPD xmm1, xmm2/m128, imm8
* Permute Double-Precision Floating-Point values in the first source operand
* using two, 1-bit control fields in the low 2 bits of the 8-bit immediate
* and store results in the destination
*/
//control:an integer specified as an 8-bit immediate; for the 256-bit m1 vector
//this integer contains four 1-bit control fields in the low 4 bits of the
//immediate, for the 128-bit m1 vector this integer contains two 1-bit
//control fields in the low 2 bits of the immediate
extern __m256d __cdecl _mm256_permute_pd(__m256d m1, int control);
extern __m128d __cdecl _mm_permute_pd(__m128d a, int control);
/*
* Permute Floating-Point Values
* **** VPERM2F128 ymm1, ymm2, ymm3/m256, imm8
* Permute 128 bit floating-point-containing fields from the first source
* operand and second source operand using bits in the 8-bit immediate and
* store results in the destination
*/
//control:an immediate byte that specifies two 2-bit control fields and two
//additional bits which specify zeroing behavior
extern __m256 __cdecl _mm256_permute2f128_ps(__m256 m1, __m256 m2, int control);
extern __m256d __cdecl _mm256_permute2f128_pd(__m256d m1, __m256d m2, int control);
extern __m256i __cdecl _mm256_permute2f128_si256(__m256i m1, __m256i m2, int control);
/*
* Load with Broadcast
* **** VBROADCASTSS ymm1, m32
* **** VBROADCASTSS xmm1, m32
* Load floating point values from the source operand and broadcast to all
* elements of the destination
*/
//*a:pointer to a memory location that can hold constant 256-bit or
//128-bit float32 values, 则r0=r1=...=rn=a[0]
extern __m256 __cdecl _mm256_broadcast_ss(float const *a);
extern __m128 __cdecl _mm_broadcast_ss(float const *a);
/*
* Load with Broadcast
* **** VBROADCASTSD ymm1, m64
* Load floating point values from the source operand and broadcast to all
* elements of the destination
*/
//则r0=r1=r2=r3=a[0]
extern __m256d __cdecl _mm256_broadcast_sd(double const *a);
/*
* Load with Broadcast
* **** VBROADCASTF128 ymm1, m128
* Load floating point values from the source operand and broadcast to all
* elements of the destination
*/
//若*a为a[0],a[1],则r0=r2=a[0], r1=r3=a[1]
extern __m256 __cdecl _mm256_broadcast_ps(__m128 const *a);
extern __m256d __cdecl _mm256_broadcast_pd(__m128d const *a);
/*
* Insert packed floating-point values
* **** VINSERTF128 ymm1, ymm2, xmm3/m128, imm8
* Performs an insertion of 128-bits of packed floating-point values from the
* second source operand into an the destination at an 128-bit offset from
* imm8[0]. The remaining portions of the destination are written by the
* corresponding fields of the first source operand
*/
//offset:an integer value that represents the 128-bit offset
//where the insertion must start
//The remaining portions of the destination are written by the corresponding
//elements of the first source vector, a
extern __m256 __cdecl _mm256_insertf128_ps(__m256 a, __m128 b, int offset);
extern __m256d __cdecl _mm256_insertf128_pd(__m256d a, __m128d b, int offset);
extern __m256i __cdecl _mm256_insertf128_si256(__m256i a, __m128i b, int offset);
/*
* Move Aligned Packed Double-Precision Floating-Point Values
* **** VMOVAPD ymm1, m256
* **** VMOVAPD m256, ymm1
* Moves 4 double-precision floating-point values from the source operand to
* the destination
*/
//*a:the address must be 32-byte aligned
extern __m256d __cdecl _mm256_load_pd(double const *a);
extern void __cdecl _mm256_store_pd(double *a, __m256d b);
/*
* Move Aligned Packed Single-Precision Floating-Point Values
* **** VMOVAPS ymm1, m256
* **** VMOVAPS m256, ymm1
* Moves 8 single-precision floating-point values from the source operand to
* the destination
*/
//*a:the address must be 32-byte aligned
extern __m256 __cdecl _mm256_load_ps(float const *a);
extern void __cdecl _mm256_store_ps(float *a, __m256 b);
/*
* Move Unaligned Packed Double-Precision Floating-Point Values
* **** VMOVUPD ymm1, m256
* **** VMOVUPD m256, ymm1
* Moves 256 bits of packed double-precision floating-point values from the
* source operand to the destination
*/
//The address a does not need to be 32-byte aligned
extern __m256d __cdecl _mm256_loadu_pd(double const *a);
extern void __cdecl _mm256_storeu_pd(double *a, __m256d b);
/*
* Move Unaligned Packed Single-Precision Floating-Point Values
* **** VMOVUPS ymm1, m256
* **** VMOVUPS m256, ymm1
* Moves 256 bits of packed single-precision floating-point values from the
* source operand to the destination
*/
//The address a does not need to be 32-byte aligned
extern __m256 __cdecl _mm256_loadu_ps(float const *a);
extern void __cdecl _mm256_storeu_ps(float *a, __m256 b);
/*
* Move Aligned Packed Integer Values
* **** VMOVDQA ymm1, m256
* **** VMOVDQA m256, ymm1
* Moves 256 bits of packed integer values from the source operand to the
* destination
*/
//The address a does not need to be 32-byte aligned
extern __m256i __cdecl _mm256_load_si256(__m256i const *a);
extern void __cdecl _mm256_store_si256(__m256i *a, __m256i b);
/*
* Move Unaligned Packed Integer Values
* **** VMOVDQU ymm1, m256
* **** VMOVDQU m256, ymm1
* Moves 256 bits of packed integer values from the source operand to the
* destination
*/
//The address a does not need to be 32-byte aligned
extern __m256i __cdecl _mm256_loadu_si256(__m256i const *a);
extern void __cdecl _mm256_storeu_si256(__m256i *a, __m256i b);
/*
* Conditional SIMD Packed Loads and Stores
* **** VMASKMOVPD xmm1, xmm2, m128
* **** VMASKMOVPD ymm1, ymm2, m256
* **** VMASKMOVPD m128, xmm1, xmm2
* **** VMASKMOVPD m256, ymm1, ymm2
*
* Load forms:
* Load packed values from the 128-bit (XMM forms) or 256-bit (YMM forms)
* memory location (third operand) into the destination XMM or YMM register
* (first operand) using a mask in the first source operand (second operand).
*
* Store forms:
* Stores packed values from the XMM or YMM register in the second source
* operand (third operand) into the 128-bit (XMM forms) or 256-bit (YMM forms)
* memory location using a mask in first source operand (second operand).
* Stores are atomic.
*/
//The mask is calculated from the most significant bit of each qword of the mask
//register. If any of the bits of the mask is set to zero, the corresponding value
//from the memory location is not loaded, and the corresponding field of the
//destination vector is set to zero.
extern __m256d __cdecl _mm256_maskload_pd(double const *a, __m256i mask);
extern void __cdecl _mm256_maskstore_pd(double *a, __m256i mask, __m256d b);
extern __m128d __cdecl _mm_maskload_pd(double const *a, __m128i mask);
extern void __cdecl _mm_maskstore_pd(double *a, __m128i mask, __m128d b);
/*
* Conditional SIMD Packed Loads and Stores
* **** VMASKMOVPS xmm1, xmm2, m128
* **** VMASKMOVPS ymm1, ymm2, m256
* **** VMASKMOVPS m128, xmm1, xmm2
* **** VMASKMOVPS m256, ymm1, ymm2
*
* Load forms:
* Load packed values from the 128-bit (XMM forms) or 256-bit (YMM forms)
* memory location (third operand) into the destination XMM or YMM register
* (first operand) using a mask in the first source operand (second operand).
*
* Store forms:
* Stores packed values from the XMM or YMM register in the second source
* operand (third operand) into the 128-bit (XMM forms) or 256-bit (YMM forms)
* memory location using a mask in first source operand (second operand).
* Stores are atomic.
*/
//The mask is calculated from the most significant bit of each dword of the mask
//register. If any of the bits of the mask is set to zero, the corresponding
//value from the memory location is not loaded, and the corresponding field of
//the destination vector is set to zero.
extern __m256 __cdecl _mm256_maskload_ps(float const *a, __m256i mask);
extern void __cdecl _mm256_maskstore_ps(float *a, __m256i mask, __m256 b);
extern __m128 __cdecl _mm_maskload_ps(float const *a, __m128i mask);
extern void __cdecl _mm_maskstore_ps(float *a, __m128i mask, __m128 b);
/*
* Replicate Single-Precision Floating-Point Values
* **** VMOVSHDUP ymm1, ymm2/m256
* Duplicates odd-indexed single-precision floating-point values from the
* source operand
*/
//a=(a0, a1, a2, a3, a4, a5, a6, a7);则r=(a1, a1, a3, a3, a5, a5, a7, a7)
extern __m256 __cdecl _mm256_movehdup_ps(__m256 a);
/*
* Replicate Single-Precision Floating-Point Values
* **** VMOVSLDUP ymm1, ymm2/m256
* Duplicates even-indexed single-precision floating-point values from the
* source operand
*/
//a=(a0, a1, a2, a3, a4, a5, a6, a7);则r=(a0, a0, a2, a2, a4, a4, a6, a6)
extern __m256 __cdecl _mm256_moveldup_ps(__m256 a);
/*
* Replicate Double-Precision Floating-Point Values
* **** VMOVDDUP ymm1, ymm2/m256
* Duplicates even-indexed double-precision floating-point values from the
* source operand
*/
//a=(a0, a1, a2, a3), 则r=(a0, a0, a2, a2)
extern __m256d __cdecl _mm256_movedup_pd(__m256d a);
/*
* Move Unaligned Integer
* **** VLDDQU ymm1, m256
* The instruction is functionally similar to VMOVDQU YMM, m256 for loading
* from memory. That is: 32 bytes of data starting at an address specified by
* the source memory operand are fetched from memory and placed in a
* destination
*/
//*a:points to a memory location from where unaligned integer value must be moved
extern __m256i __cdecl _mm256_lddqu_si256(__m256i const *a);
/*
* Store Packed Integers Using Non-Temporal Hint
* **** VMOVNTDQ m256, ymm1
* Moves the packed integers in the source operand to the destination using a
* non-temporal hint to prevent caching of the data during the write to memory
*/
//the address must be 32-byte aligned
extern void __cdecl _mm256_stream_si256(__m256i *p, __m256i a);
/*
* Store Packed Double-Precision Floating-Point Values Using Non-Temporal Hint
* **** VMOVNTPD m256, ymm1
* Moves the packed double-precision floating-point values in the source
* operand to the destination operand using a non-temporal hint to prevent
* caching of the data during the write to memory
*/
//the address must be 32-byte aligned
extern void __cdecl _mm256_stream_pd(double *p, __m256d a);
/*
* Store Packed Single-Precision Floating-Point Values Using Non-Temporal Hint
* **** VMOVNTPS m256, ymm1
* Moves the packed single-precision floating-point values in the source
* operand to the destination operand using a non-temporal hint to prevent
* caching of the data during the write to memory
*/
//the address must be 32-byte aligned
extern void __cdecl _mm256_stream_ps(float *p, __m256 a);
/*
* Compute Approximate Reciprocals of Packed Single-Precision Floating-Point Values
* **** VRCPPS ymm1, ymm2/m256
* Performs an SIMD computation of the approximate reciprocals of the eight
* packed single precision floating-point values in the source operand and
* stores the packed single-precision floating-point results in the destination
*/
//a=(a0, a1, a2, ..., a6, a7);
//则r=(1/a0, 1/a1, ..., 1/a6, 1/a7), 求倒数
extern __m256 __cdecl _mm256_rcp_ps(__m256 a);
/*
* Compute Approximate Reciprocals of Square Roots of
* Packed Single-Precision Floating-point Values
* **** VRSQRTPS ymm1, ymm2/m256
* Performs an SIMD computation of the approximate reciprocals of the square
* roots of the eight packed single precision floating-point values in the
* source operand and stores the packed single-precision floating-point results
* in the destination
*/
//a=(a0, a1, a2, ..., a6, a7);
//则r=(1/sqrt(a0), 1/sqrt(a1), ..., 1/sqrt(a6), 1/sqrt(a7)), 先开方再求倒数
extern __m256 __cdecl _mm256_rsqrt_ps(__m256 a);
/*
* Square Root of Double-Precision Floating-Point Values
* **** VSQRTPD ymm1, ymm2/m256
* Performs an SIMD computation of the square roots of the two or four packed
* double-precision floating-point values in the source operand and stores
* the packed double-precision floating-point results in the destination
*/
//a=(a0, a1, a2, a3, a4);则r=(sqrt(a0),sqrt(a1), sqrt(a2), sqrt(a3)), 求开方
extern __m256d __cdecl _mm256_sqrt_pd(__m256d a);
/*
* Square Root of Single-Precision Floating-Point Values
* **** VSQRTPS ymm1, ymm2/m256
* Performs an SIMD computation of the square roots of the eight packed
* single-precision floating-point values in the source operand stores the
* packed double-precision floating-point results in the destination
*/
//a=(a0, a1, a2, ..., a3, a4);则r=(sqrt(a0),sqrt(a1), ..., sqrt(a2), sqrt(a3)), 求开方
extern __m256 __cdecl _mm256_sqrt_ps(__m256 a);
/*
* Round Packed Double-Precision Floating-Point Values
* **** VROUNDPD ymm1,ymm2/m256,imm8
* Round the four Double-Precision Floating-Point Values values in the source
* operand by the rounding mode specified in the immediate operand and place
* the result in the destination. The rounding process rounds the input to an
* integral value and returns the result as a double-precision floating-point
* value. The Precision Floating Point Exception is signaled according to the
* immediate operand. If any source operand is an SNaN then it will be
* converted to a QNaN.
*/
//a=(22.8, -11.3, -33.8, 4.3),
//若iRoundMode=0x0A, 则r=(23, -11, -33, 5)
//若iRoundMode=0x09, 则r=(22, -12, -34, 4)
extern __m256d __cdecl _mm256_round_pd(__m256d a, int iRoundMode);
#define _mm256_ceil_pd(val) _mm256_round_pd((val), 0x0A);
#define _mm256_floor_pd(val) _mm256_round_pd((val), 0x09);
/*
* Round Packed Single-Precision Floating-Point Values
* **** VROUNDPS ymm1,ymm2/m256,imm8
* Round the four single-precision floating-point values values in the source
* operand by the rounding mode specified in the immediate operand and place
* the result in the destination. The rounding process rounds the input to an
* integral value and returns the result as a double-precision floating-point
* value. The Precision Floating Point Exception is signaled according to the
* immediate operand. If any source operand is an SNaN then it will be
* converted to a QNaN.
*/
//用法与_mm256_round_pd相同
extern __m256 __cdecl _mm256_round_ps(__m256 a, int iRoundMode);
#define _mm256_ceil_ps(val) _mm256_round_ps((val), 0x0A);
#define _mm256_floor_ps(val) _mm256_round_ps((val), 0x09);
/*
* Unpack and Interleave High Packed Double-Precision Floating-Point Values
* **** VUNPCKHPD ymm1,ymm2,ymm3/m256
* Performs an interleaved unpack of the high double-precision floating-point
* values from the first source operand and the second source operand.
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r=(m11, m21, m13, m23)
extern __m256d __cdecl _mm256_unpackhi_pd(__m256d m1, __m256d m2);
/*
* Unpack and Interleave High Packed Single-Precision Floating-Point Values
* **** VUNPCKHPS ymm1,ymm2,ymm3
* Performs an interleaved unpack of the high single-precision floating-point
* values from the first source operand and the second source operand
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r=(m12, m22, m13, m23, m16, m26, m17, m27)
extern __m256 __cdecl _mm256_unpackhi_ps(__m256 m1, __m256 m2);
/*
* Unpack and Interleave Low Packed Double-Precision Floating-Point Values
* **** VUNPCKLPD ymm1,ymm2,ymm3/m256
* Performs an interleaved unpack of the low double-precision floating-point
* values from the first source operand and the second source operand
*/
//m1=(m10, m11, m12, m13), m2=(m20, m21, m22, m23)
//则r=(m10, m20, m12, m22)
extern __m256d __cdecl _mm256_unpacklo_pd(__m256d m1, __m256d m2);
/*
* Unpack and Interleave Low Packed Single-Precision Floating-Point Values
* **** VUNPCKLPS ymm1,ymm2,ymm3
* Performs an interleaved unpack of the low single-precision floating-point
* values from the first source operand and the second source operand
*/
//m1=(m10, m11, ..., m17), m2=(m20, m21, ..., m27)
//则r=(m10, m20, m11, m21, m14, m24, m15, m25)
extern __m256 __cdecl _mm256_unpacklo_ps(__m256 m1, __m256 m2);
/*
* Packed Bit Test
* **** VPTEST ymm1, ymm2/m256
* VPTEST set the ZF flag if all bits in the result are 0 of the bitwise AND
* of the first source operand and the second source operand. VPTEST sets the
* CF flag if all bits in the result are 0 of the bitwise AND of the second
* source operand and the logical NOT of the destination.
*/
extern int __cdecl _mm256_testz_si256(__m256i s1, __m256i s2);
extern int __cdecl _mm256_testc_si256(__m256i s1, __m256i s2);
extern int __cdecl _mm256_testnzc_si256(__m256i s1, __m256i s2);
/*
* Packed Bit Test
* **** VTESTPD ymm1, ymm2/m256
* **** VTESTPD xmm1, xmm2/m128
* VTESTPD performs a bitwise comparison of all the sign bits of the
* double-precision elements in the first source operation and corresponding
* sign bits in the second source operand. If the AND of the two sets of bits
* produces all zeros, the ZF is set else the ZF is clear. If the AND NOT of
* the source sign bits with the dest sign bits produces all zeros the CF is
* set else the CF is clear
*/
extern int __cdecl _mm256_testz_pd(__m256d s1, __m256d s2);
extern int __cdecl _mm256_testc_pd(__m256d s1, __m256d s2);
extern int __cdecl _mm256_testnzc_pd(__m256d s1, __m256d s2);
extern int __cdecl _mm_testz_pd(__m128d s1, __m128d s2);
extern int __cdecl _mm_testc_pd(__m128d s1, __m128d s2);
extern int __cdecl _mm_testnzc_pd(__m128d s1, __m128d s2);
/*
* Packed Bit Test
* **** VTESTPS ymm1, ymm2/m256
* **** VTESTPS xmm1, xmm2/m128
* VTESTPS performs a bitwise comparison of all the sign bits of the packed
* single-precision elements in the first source operation and corresponding
* sign bits in the second source operand. If the AND of the two sets of bits
* produces all zeros, the ZF is set else the ZF is clear. If the AND NOT of
* the source sign bits with the dest sign bits produces all zeros the CF is
* set else the CF is clear
*/
extern int __cdecl _mm256_testz_ps(__m256 s1, __m256 s2);
extern int __cdecl _mm256_testc_ps(__m256 s1, __m256 s2);
extern int __cdecl _mm256_testnzc_ps(__m256 s1, __m256 s2);
extern int __cdecl _mm_testz_ps(__m128 s1, __m128 s2);
extern int __cdecl _mm_testc_ps(__m128 s1, __m128 s2);
extern int __cdecl _mm_testnzc_ps(__m128 s1, __m128 s2);
/*
* Extract Double-Precision Floating-Point Sign mask
* **** VMOVMSKPD r32, ymm2
* Extracts the sign bits from the packed double-precision floating-point
* values in the source operand, formats them into a 4-bit mask, and stores
* the mask in the destination
*/
extern int __cdecl _mm256_movemask_pd(__m256d a);
/*
* Extract Single-Precision Floating-Point Sign mask
* **** VMOVMSKPS r32, ymm2
* Extracts the sign bits from the packed single-precision floating-point
* values in the source operand, formats them into a 8-bit mask, and stores
* the mask in the destination
*/
extern int __cdecl _mm256_movemask_ps(__m256 a);
/*
* Return 256-bit vector with all elements set to 0
*/
//则r0=r1=...=rn=0
extern __m256d __cdecl _mm256_setzero_pd(void);
extern __m256 __cdecl _mm256_setzero_ps(void);
extern __m256i __cdecl _mm256_setzero_si256(void);
/*
* Return 256-bit vector intialized to specified arguments
*/
//则r = (d, c, b, a)
extern __m256d __cdecl _mm256_set_pd(double a, double b, double c, double d);
extern __m256 __cdecl _mm256_set_ps(float, float, float, float, float, float, float, float);
extern __m256i __cdecl _mm256_set_epi8(char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char);
extern __m256i __cdecl _mm256_set_epi16(short, short, short, short, short, short, short, short,
short, short, short, short, short, short, short, short);
extern __m256i __cdecl _mm256_set_epi32(int, int, int, int, int, int, int, int);
extern __m256i __cdecl _mm256_set_epi64x(long long, long long, long long, long long);
//则r = (a, b, c, d)
extern __m256d __cdecl _mm256_setr_pd(double a, double b, double c, double d);
extern __m256 __cdecl _mm256_setr_ps(float, float, float, float, float, float, float, float);
extern __m256i __cdecl _mm256_setr_epi8(char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char,
char, char, char, char, char, char, char, char);
extern __m256i __cdecl _mm256_setr_epi16(short, short, short, short, short, short, short, short,
short, short, short, short, short, short, short, short);
extern __m256i __cdecl _mm256_setr_epi32(int, int, int, int, int, int, int, int);
extern __m256i __cdecl _mm256_setr_epi64x(long long, long long, long long, long long);
/*
* Return 256-bit vector with all elements intialized to specified scalar
*/
//则r0 = ... = rn = a
extern __m256d __cdecl _mm256_set1_pd(double a);
extern __m256 __cdecl _mm256_set1_ps(float);
extern __m256i __cdecl _mm256_set1_epi8(char);
extern __m256i __cdecl _mm256_set1_epi16(short);
extern __m256i __cdecl _mm256_set1_epi32(int);
extern __m256i __cdecl _mm256_set1_epi64x(long long);
/*
* Support intrinsics to do vector type casts. These intrinsics do not introduce
* extra moves to generated code. When cast is done from a 128 to 256-bit type
* the low 128 bits of the 256-bit result contain source parameter value; the
* upper 128 bits of the result are undefined
*/
//类型转换
extern __m256 __cdecl _mm256_castpd_ps(__m256d a);
extern __m256d __cdecl _mm256_castps_pd(__m256 a);
extern __m256i __cdecl _mm256_castps_si256(__m256 a);
extern __m256i __cdecl _mm256_castpd_si256(__m256d a);
extern __m256 __cdecl _mm256_castsi256_ps(__m256i a);
extern __m256d __cdecl _mm256_castsi256_pd(__m256i a);
extern __m128 __cdecl _mm256_castps256_ps128(__m256 a);
extern __m128d __cdecl _mm256_castpd256_pd128(__m256d a);
extern __m128i __cdecl _mm256_castsi256_si128(__m256i a);
extern __m256 __cdecl _mm256_castps128_ps256(__m128 a);
extern __m256d __cdecl _mm256_castpd128_pd256(__m128d a);
extern __m256i __cdecl _mm256_castsi128_si256(__m128i a);
/* Start of new intrinsics for Dev10 SP1
*
* The list of extended control registers.
* Currently, the list includes only one register.
*/
#define _XCR_XFEATURE_ENABLED_MASK 0
/* Returns the content of the specified extended control register */
extern unsigned __int64 __cdecl _xgetbv(unsigned int ext_ctrl_reg);
/* Writes the value to the specified extended control register */
extern void __cdecl _xsetbv(unsigned int ext_ctrl_reg, unsigned __int64 val);
/*
* Performs a full or partial save of the enabled processor state components
* using the the specified memory address location and a mask.
*/
extern void __cdecl _xsave(void *mem, unsigned __int64 save_mask);
extern void __cdecl _xsave64(void *mem, unsigned __int64 save_mask);
/*
* Performs a full or partial save of the enabled processor state components
* using the the specified memory address location and a mask.
* Optimize the state save operation if possible.
*/
extern void __cdecl _xsaveopt(void *mem, unsigned __int64 save_mask);
extern void __cdecl _xsaveopt64(void *mem, unsigned __int64 save_mask);
/*
* Performs a full or partial restore of the enabled processor states
* using the state information stored in the specified memory address location
* and a mask.
*/
extern void __cdecl _xrstor(void *mem, unsigned __int64 restore_mask);
extern void __cdecl _xrstor64(void *mem, unsigned __int64 restore_mask);
/*
* Saves the current state of the x87 FPU, MMX technology, XMM,
* and MXCSR registers to the specified 512-byte memory location.
*/
extern void __cdecl _fxsave(void *mem);
extern void __cdecl _fxsave64(void *mem);
/*
* Restore the current state of the x87 FPU, MMX technology, XMM,
* and MXCSR registers from the specified 512-byte memory location.
*/
extern void __cdecl _fxrstor(void *mem);
extern void __cdecl _fxrstor64(void *mem);