计算机概论
一、计算机设备
1.1 CPU
CPU的全称是Central Processing Unit,它是你的电脑中最硬核的组件。CPU是能够让你的计算机叫计算机的核心组件,但是它却不能代表你的电脑,CPU与计算机的关系就相当于大脑和人的关系。它是一种小型的计算机芯片,它嵌入在台式机、笔记本电脑或者平板电脑的主板上。通过在单个计算机芯片上放置数十亿个微型晶体管来构建CPU。这些晶体管使它能够执行运行存储在系统内存中的程序所需的计算,也就是说CPU决定了你电脑的计算能力。

CPU的核心是从程序或应用程序获取指令并执行计算。此过程可以分为三个关键阶段:提取、解码和执行。CPU从系统的RAM中提取指令,然后解码该指令的实际内容,然后再由CPU的相关部分执行该指令。
RAM,随机存取存储器(英语:Random Access Memory,缩写RAM),也叫主存,是与CPU直接交换数据的内部存储器。它可以随时读写(刷新时除外),而且速度很快,通常作为操作系统或其他正在运行中的程序的临时数据存储介质。
下图展示了一般程序的运行流程(以C语言为例),可以说了解程序的运行流程是掌握程序运行机制的基础和前提。
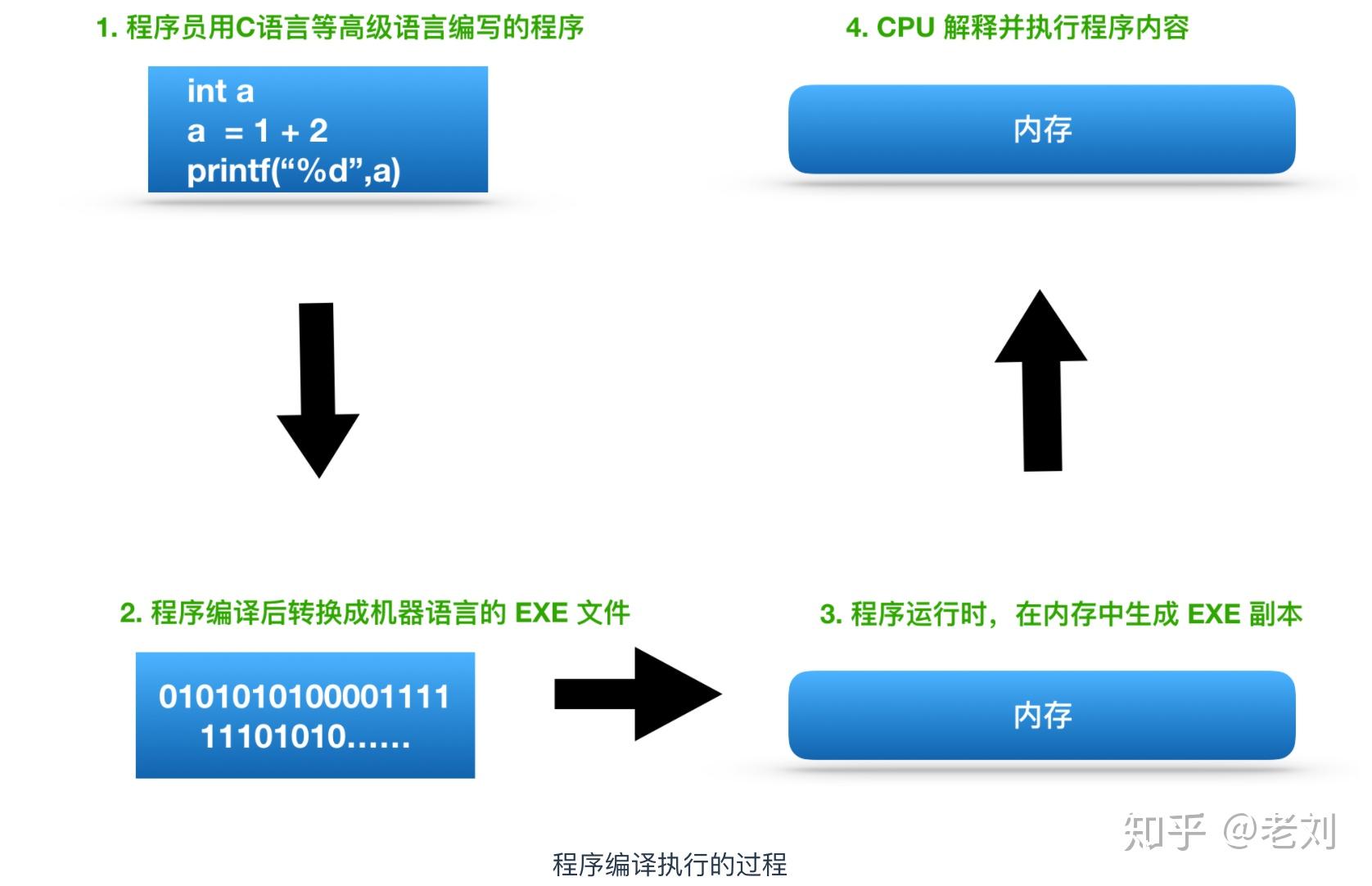
在这个流程中,CPU负责的就是解释和运行最终转换成机器语言的内容。CPU主要由两部分构成:控制单元和算术逻辑单元(ALU)。
控制单元:从内存中提取指令并解码执行
算数逻辑单元(ALU):处理算数和逻辑运算
CPU是计算机的心脏和大脑,它和内存都是由许多晶体管组成的电子部件。它接收数据输入,执行指令并处理信息。它与输入/输出(I/O)设备进行通信,这些设备向CPU发送数据和从CPU接收数据。
从功能来看,CPU的内部由寄存器、控制器、运算器和时钟四部分组成,各部分之间通过电信号连通。

寄存器 是中央处理器内的组成部分,它们可以用来暂存指令、数据和地址。可以将其看作是内存的一种。根据种类的不同,一个CPU内部会有20-100个寄存器
控制器 负责把内存上的指令、数据读入寄存器,并根据指令的结果控制计算机
运算器 负责运算从内存中读入寄存器的数据
时钟 负责发出CPU开始计时的时钟信号
接下来简单解释一下内存,为什么说CPU需要讲一下内存呢,因为内存是与CPU进行沟通的桥梁。计算机所有程序的运行都是在内存中运行的,内存又被称为主存,其作用是存放CPU中的运算数据,以及与硬盘等外部存储设备交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到主存中进行运算,当运算完成后CPU再将结果传送出来,主存的运行也决定了计算机的稳定运行。
主存通过控制芯片与CPU进行相连,由可读写的元素构成,每个字节(1 byte=8 bits)都带有一个地址编号,注意是一个字节,而不是一个位。CPU通过地址从主存中读取数据和指令,也可以根据地址写入数据。注意一点:当计算机关机时,内存中的指令和数据也会被清除。
- CPU是寄存器的集合体
在CPU的四个结构中,我们程序员只需要了解寄存器就可以了,其余三个不用过多关注,为什么这么说?因为程序是把寄存器作为对象来描述的。
说到寄存器,就不得不说到汇编语言,说到汇编语言,就不得不说到高级语言,说到高级语言就不得不牵扯出语言这个概念。
- 计算机语言
我们生而为人最明显的一个特征是我们能通过讲话来实现彼此的交流,但是计算机听不懂你说的话,你要想和他交流必须按照计算机指令来交换,这就涉及到语言的问题,计算机是由二进制构成的,它只能听的懂二进制也就是机器语言,但是普通人是无法看懂机器语言的,这个时候就需要一种电脑既能识别,人又能理解的语言,最先出现的就是汇编语言。但是汇编语言晦涩难懂,所以又出现了像是C,C++,Java的这种高级语言。
所以计算机语言一般分为两种:低级语言(机器语言,汇编语言)和高级语言。使用高级语言编写的程序,经过编译转换成机器语言后才能运行,而汇编语言经过汇编器才能转换为机器语言。
- 汇编语言
首先来看一段用汇编语言表示的代码清单
mov eax, dword ptr [ebp-8] /* 把数值从内存复制到eax */
add eax, dword ptr [ebp-0Ch] /* 把eax的数值和内存的数值相加 */
mov dword ptr [ebp-4], eax /* 把eax的数值(上一步的结果)存储在内存中 */
这是采用汇编语言(assembly)编写程序的一部分。汇编语言采用助记符(memonic)来编写程序,每一个原本是电信号的机器语言指令会有一个与其对应的助记符,例如mov,add分别是数据的存储(move)和相加(addition)的简写。汇编语言和机器语言是一一对应的,这一点和高级语言有很大的不同,通常我们将汇编语言编写的程序转换为机器语言的过程称为汇编;反之,机器语言转化为汇编语言的过程称为反汇编。
汇编语言能够帮助你理解计算机做了什么工作,机器语言级别的程序是通过寄存器来处理的,上面代码中的eax,ebp都是表示的寄存器,是CPU内部寄存器的名称,所以可以说CPU是一系列寄存器的集合体。在内存中的存储通过地址编号来表示,而寄存器的种类则通过名字来区分。
不同类型的CPU,其内部寄存器的种类,数量以及寄存器存储的数值范围都是不同的。不过,根据功能的不同,可以将寄存器划分为下面这几类:
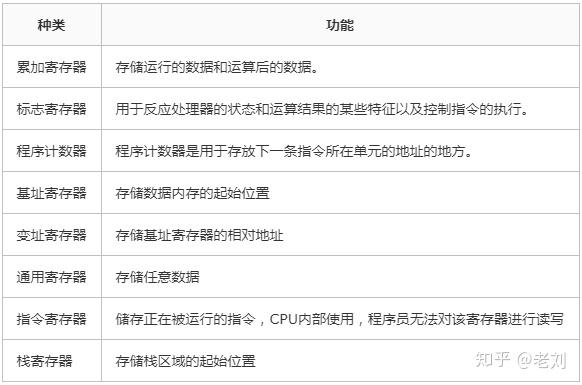
其中程序计数器、累加寄存器、标志寄存器、指令寄存器和栈寄存器都只有一个,其他寄存器一般有多个。
- 程序计数器
程序计数器(Program Counter)是用来存储下一条指令所在单元的地址。程序执行时,PC的初值为程序第一条指令的地址,在顺序执行程序时,控制器首先按程序计数器所指出的指令地址从内存中取出一条指令,然后分析和执行该指令,同时将PC的值加1指向下一条要执行的指令。
我们还是以一个事例为准来详细的看一下程序计数器的执行过程
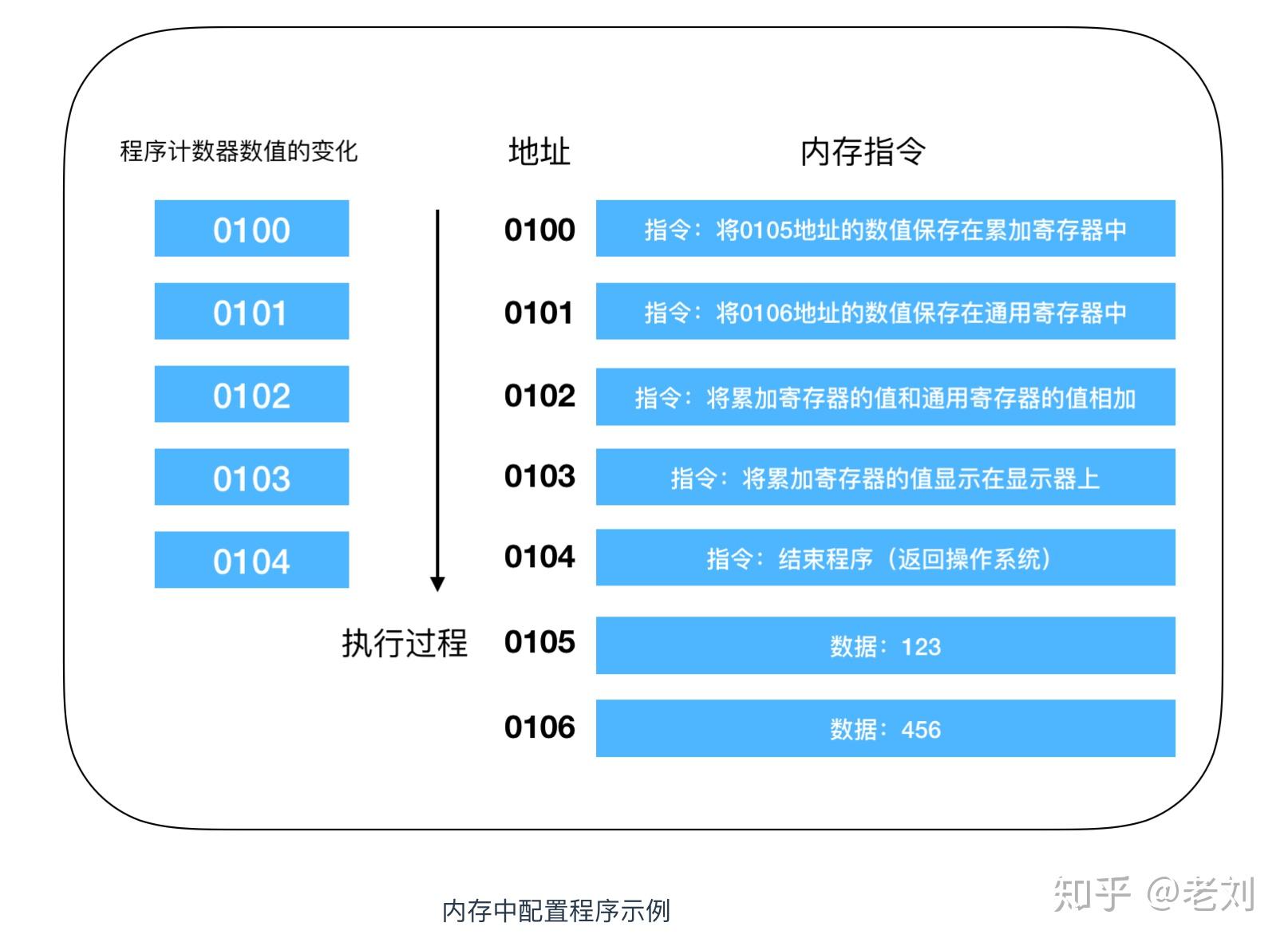
这是一段进行相加的操作,程序启动,在经过编译解析后会由操作系统把硬盘中的程序复制到内存中,示例中的程序是将123和456执行相加操作,并将结果输出到显示器上。由于使用机器语言难以描述,所以这是经过翻译后的结果,实际上每个指令和数据都可能分布在不同的地址上,但为了方便说明,把组成一条指令的内存和数据放在了一个内存地址上。
地址0100是程序运行的起始位置。Windows等操作系统把程序从硬盘复制到内存后,会将程序计数器作为设定为起始位置0100,然后执行程序,每执行一条指令后,程序计数器的数值会增加1(或者直接指向下一条指令的地址),然后CPU就会根据程序计数器的数值,从内存中读取命令并执行,也就是说,程序计数器控制着程序的流程。
- 条件分支和循环机制
我们都学过高级语言,高级语言中的条件控制流程主要分为三种:顺序执行、条件分支、循环判断三种,顺序执行是按照地址的内容顺序的执行指令。条件分支是根据条件执行任意地址的指令,循环是重复执行同一地址的指令。
顺序执行的情况比较简单,每执行一条指令程序计数器的值就是+1,条件和循环分支会使程序计数器的值指向任意的地址,这样一来,程序便可以返回到上一个地址来重复执行同一个指令,或者跳转到任意指令。
下面以条件分支为例来说明程序的执行过程(循环也很相似)
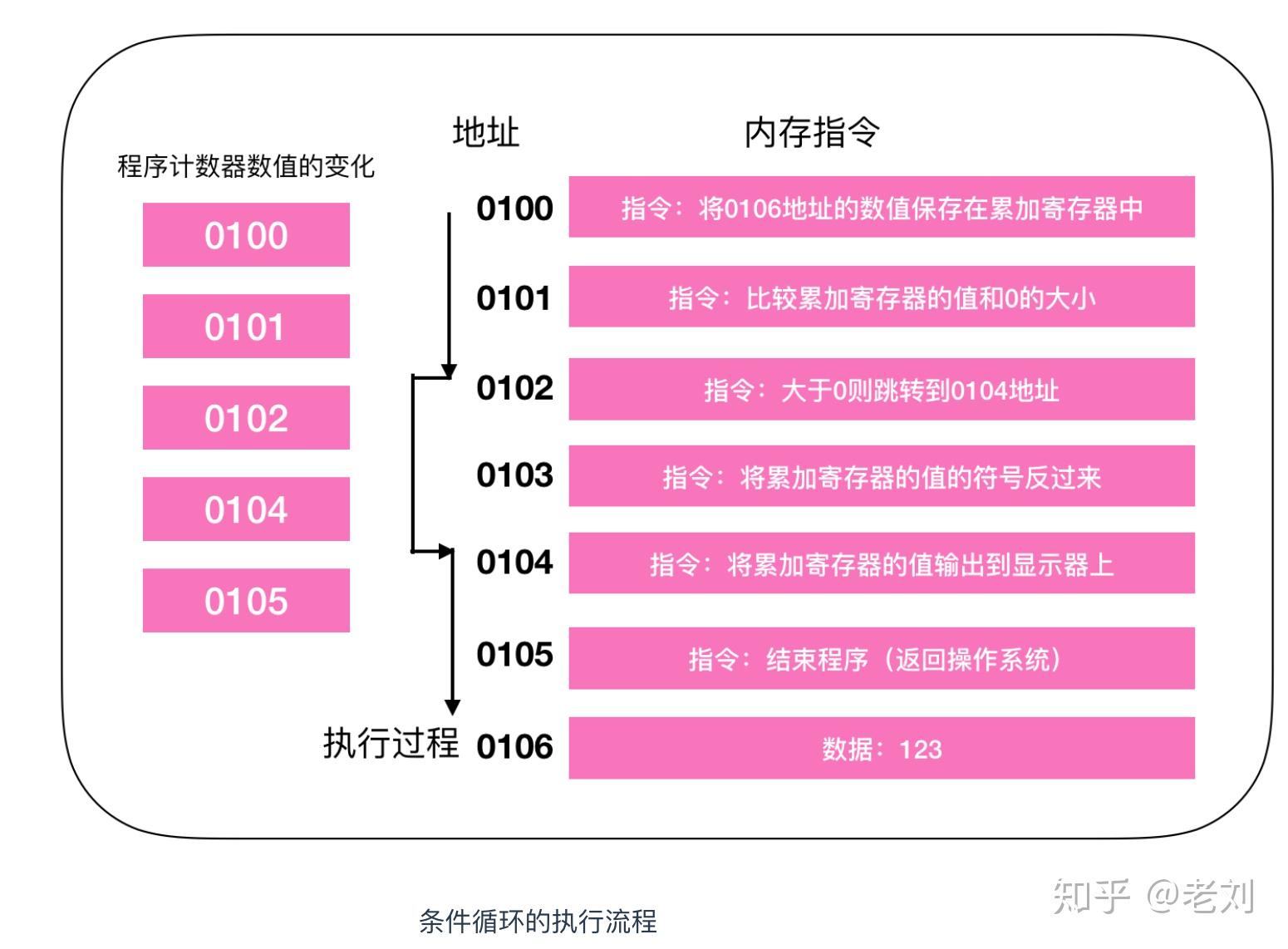
程序的开始过程和顺序流程是一样的,CPU从0100处开始执行命令,在0100和0101都是顺序执行,PC的值顺序+1,执行到0102地址的指令时,判断0106寄存器的数值大于0,跳转(jump)到0104地址的指令,将数值输出到显示器中,然后结束程序,0103的指令被跳过了,这就和我们程序中的if()判断是一样的,在不满足条件的情况下,指令会直接跳过。所以PC的执行过程也就没有直接+1,而是下一条指令的地址。
- 标志寄存器
条件和循环分支会使用到jump(跳转指令),会根据当前的指令来判断是否跳转,上面我们提到了标志寄存器,无论当前累加寄存器的运算结果是正数、负数还是零,标志寄存器都会将其保存(也负责溢出和奇偶校验)。
溢出(overflow) :是指运算的结果超过了寄存器的长度范围
奇偶校验(parity check) :是指检查运算结果的值是偶数还是奇数
CPU在进行运算时,标志寄存器的数值会根据当前运算的结果自动设定,运算结果的正、负和零三种状态由标志寄存器的三个位表示。标志寄存器的第一个字节位、第二个字节位、第三个字节位各自的结果都为1时,分别代表着正数、零和负数。
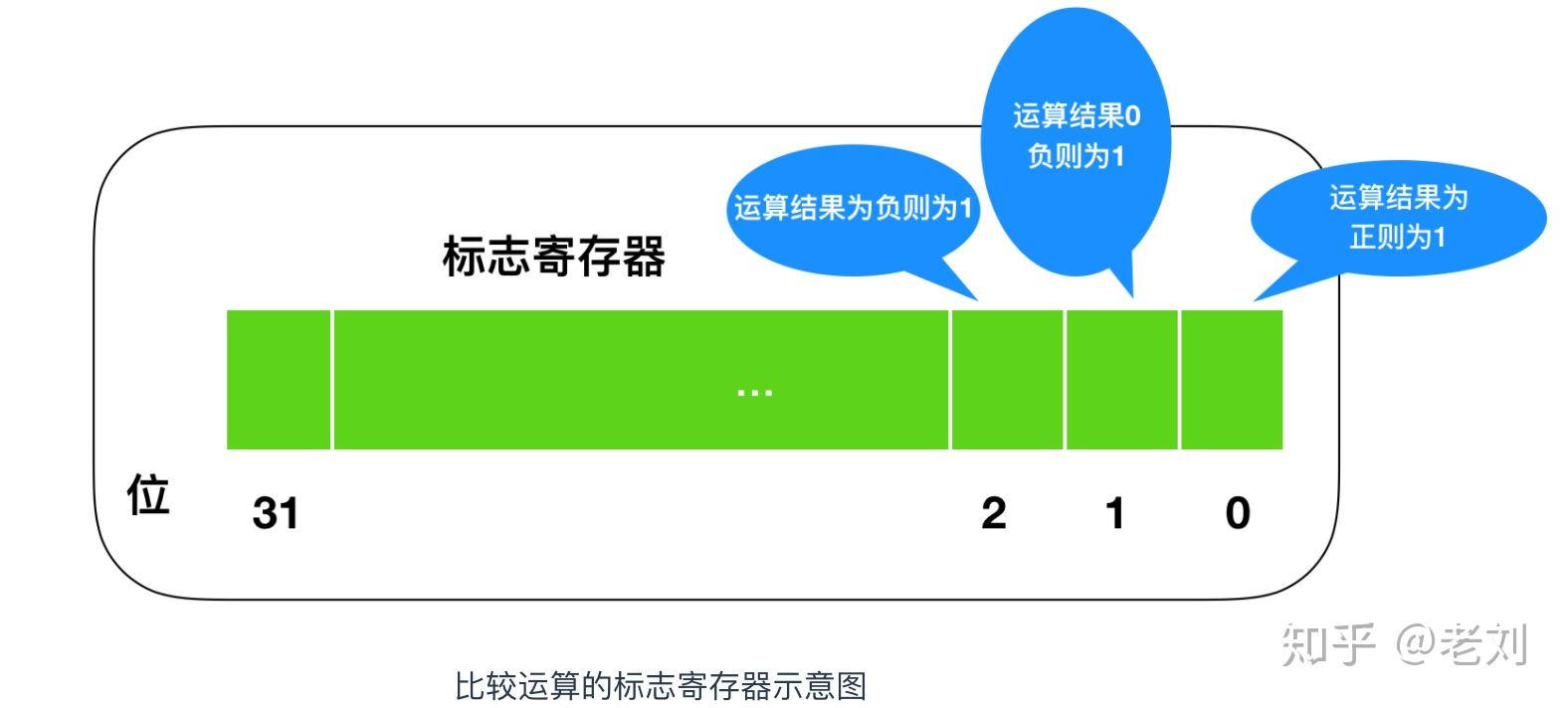
CPU的执行机制比较有意思,假设累加寄存器中存储的XXX和通用寄存器中存储的YYY做比较,执行比较的背后,CPU的运算机制就会做减法运算。而无论减法运算的结果是正数、零还是负数,都会保存到标志寄存器中。结果为正表示XXX比YYY大,结果为零表示XXX和YYY相等,结果为负表示XXX比YYY小。程序比较的指令,实际上是在CPU内部做减法运算。
- 函数调用机制
接下来,我们继续介绍函数调用机制,哪怕是高级语言编写的程序,函数调用处理也是通过把程序计数器的值设定成函数的存储地址来实现的。函数执行跳转指令后,必须进行返回处理,单纯的指令跳转没有意义,下面是一个实现函数跳转的例子
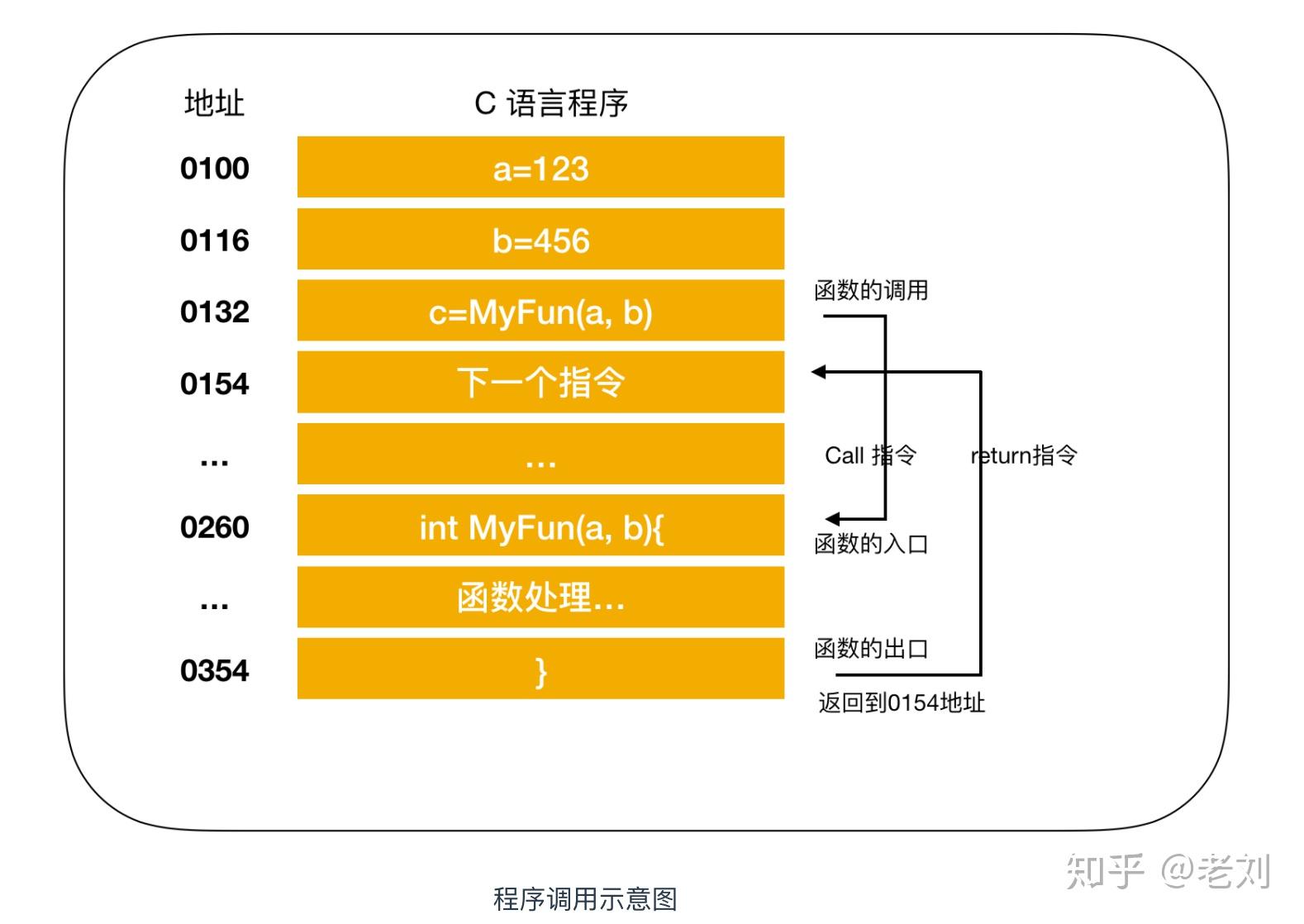
图中将变量a和b分别赋值为123和456,调用MyFun(a,b)方法,进行指令跳转。图中的地址是将C语言编译成机器语言后运行时的地址,由于1行C程序在编译后通常会变为多行机器语言,所以图中的地址是分散的。在执行完MyFun(a,b)指令后,程序会返回到MyFun(a,b)的下一条指令,CPU继续执行下面的指令。
函数的调用和返回很重要的两个指令是call和return指令,再将函数的入口地址设定到程序计数器之前,call指令会把调用函数后要执行的指令地址存储在名为栈的主存内。函数处理完毕后,再通过函数的出口来执行return指令。return指令的功能是把保存在栈中的地址设定到程序计数器。MyFun函数在被调用之前,0154地址保存在栈中,MyFun函数处理完成后,会把0154的地址保存在程序计数器中。这个调用过程如下
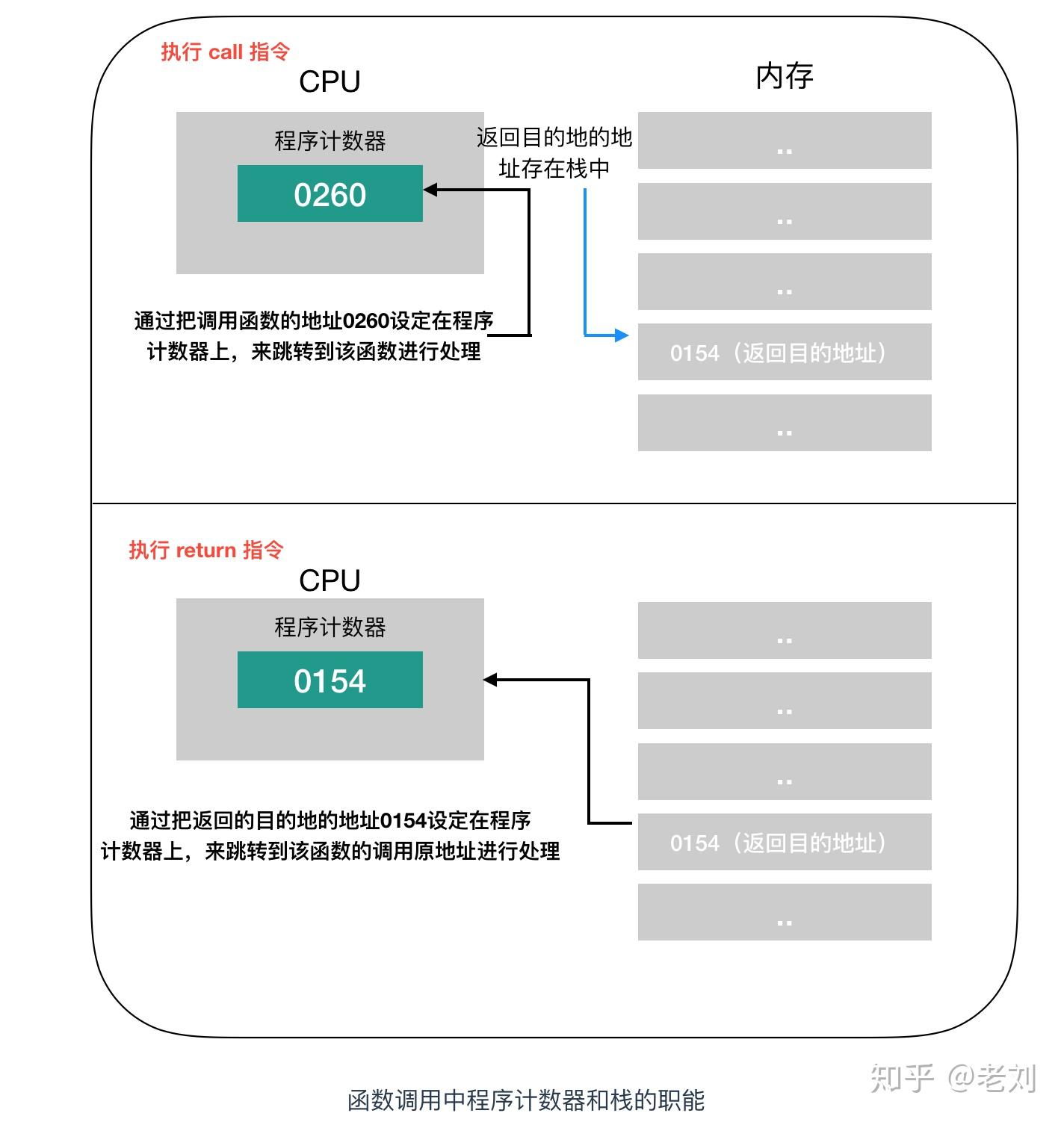
在一些高级语言的条件或者循环语句中,函数调用的处理会转换成call指令,函数结束后的处理则会转换成return指令。
- 通过地址和索引实现数组
接下来我们看一下基址寄存器和变址寄存器,通过这两个寄存器,我们可以对主存上的特定区域进行划分,来实现类似数组的操作,首先,我们用十六进制数将计算机内存上的00000000-FFFFFFFF的地址划分出来。那么,凡是该范围的内存地址,只要有一个32位的寄存器,便可查看全部地址。但如果想要想数组那样分割特定的内存区域以达到连续查看的目的的话,使用两个寄存器会更加方便。
例如我们用两个寄存器(基址寄存器和变址寄存器)来表示内存的值

这种表示方式很类似数组的构造,数组是指同样长度的数据在内存中进行连续排列的数据构造。用数组名表示数组全部的值,通过索引来区分数组的各个数据元素,例如:a[0]-a[4],[]内的0-4就是数组的下标。
- CPU指令执行过程
那么CPU是如何执行一条条的指令的呢?几乎所有的冯·诺伊曼型计算机的CPU,其工作都可以分为5个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
取指令阶段 是将内存中的指令读取到CPU中寄存器的过程,程序寄存器用于存储下一条指令所在的地址
指令译码阶段 在取指令完成后,立马进入指令译码阶段,在指令译码阶段,指令译码器按照预定的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别以及各种获取操作数的方法。
执行指令阶段 译码完成后,就需要执行这一条指令了,此阶段的任务是完成指令所规定的各种操作,具体实现指令的功能
访问取数阶段 根据指令的需要,有可能需要从内存中提取数据,此阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算 结果写回阶段 作为最后一个阶段,结果写回(Write Back,WB)阶段把执行指令阶段的运行结果数据"写回"到某种存储形式:结果数据经常被写到CPU的内部寄存器中,以便被后续的指令快速地存取;
二、互联网知识
2.1 统一资源标识符
在计算机术语中,统一资源标识符(Uniform Resource Identifier,缩写URI)是一个用于标识某一互联网资源名称的字符串。该种标识允许用户对网络中(一般指万维网)的资源通过特定的协议进行交互操作。URI的最常见的形式是统一资源定位符(Uniform Resource Locator,缩写为URL),经常指定为非正式的网址。更罕见的用法是统一资源名称(URN),其目的是通过提供一种途径,用于在特定的名字空间资源的标识,以补充网址。
与URL和URN的关系:

URI可被视为定位符(URL),名称(URN)或两者兼备。统一资源名(URN)如同一个人的名称,而统一资源定位符(URL)代表一个人的住址。换言之,URN定义某事物的身份,而URL提供查找该事物的方法。
用于标识唯一书目的ISBN系统是一个典型的URN使用范例。例如,ISBN 0-486-27557-4无二义性地标识出莎士比亚的戏剧《罗密欧与朱丽叶》的某一特定版本。为获得该资源并阅读该书,人们需要它的位置,也就是一个URL地址。在类Unix操作系统中,一个典型的URL地址可能是一个文件目录,例如file:///home/username/RomeoAndJuliet.pdf。该URL标识出存储于本地硬盘中的电子书文件。因此,URL和URN有着互补的作用。
技术观点: URL是一种URI,它标识一个互联网资源,并指定对其进行操作或获取该资源的方法。可能通过对主要访问手段的描述,也可能通过网络“位置”进行标识。例如,http://www.wikipedia.org/这个URL,标识一个特定资源(首页)并表示该资源的某种形式(例如以编码字符表示的,首页的HTML代码)是可以通过HTTP协议从www.wikipedia.org这个网络主机获得的。URN是基于某名字空间通过名称指定资源的URI。人们可以通过URN来指出某个资源,而无需指出其位置和获得方式。资源无需是基于互联网的。例如,URN urn:ISBN 0-395-36341-1指定标识系统(即国际标准书号ISBN)和某资源在该系统中的唯一表示的URI。它可以允许人们在不指出其位置和获得方式的情况下谈论这本书。
文法: URI文法由URI协议名(例如"http","ftp","mailto"或"file"),一个冒号,和协议对应的内容所构成。特定的协议定义了协议内容的语法和语义,而所有的协议都必须遵循一定的URI文法通用规则,亦即为某些专门目的保留部分特殊字符。URI文法同时也就各种原因对协议内容加以其他的限制,例如,保证各种分层协议之间的协同性。百分号编码也为URI提供附加信息。
通用URI的格式如下:
scheme:[//[user[:password]@]host[:port]][/path][?query][#fragment]
URL被冒号分成了两部分,前面是scheme(方案),后面是scheme的描述部分。
scheme只能由以下元素组成:a-z(不区分大小写),数字,字符(加号+,句号.,连字符-)。shceme目前有这些类型:
| 类型 | 说明 |
|---|---|
| ftp | File Transfer protocol(文件传输协议) |
| http | Hypertext Transfer Protocol(超文本传输协议) |
| gopher | The Gopher protocol(Gopher协议) |
| mailto | Electronic mail address(电子邮件地址) |
| news | USENET news(USENET新闻) |
| nntp | USENET news using NNTP access(使用NNTP访问的USENET新闻) |
| telnet | Reference to interactive sessions(交互式会话访问) |
| wais | Wide Area Information Servers(广域信息服务系统) |
| file | Host-specific file names(特殊主机文件名) |
| prospero | Prospero Directory Service(prospero目录服务) |
当然,上述的scheme大部分是应用非常广泛的,我们可以自定义scheme,只要解析器支持即可,比如我们公司就根据URL设计了一条App跳转专用的URL,方便服务器分发跳转路径。
scheme的描述部分也可以拆解成以下的结构:
<user>:<password>@<host>:<port>/<url-path>
根据方案的不同,这些部分是可以部分省略的,比如http通常不需要user和password。我们来依次看这些组成部分:
| 字段 | 说明 |
|---|---|
| user | 这个比较好理解,就是用户名,没有则省略 |
| password | 用户密码 |
| host | host(主机)是一个IP地址,由四组十进制数字以.分割组合而成。现在很多对客的地址都是用了域名,然后再通过DNS解析.DNS可以理解为将难以记住的ip地址和单词等组成的域名做映射,从而方便用户的使用。记住https://www.baidu.com可比记住192.292.22.22容易多了。很多的公司在使用的时候也会做DNS优化,即客户端等发出请求的时候,直接向对应的ip发送,从而节省DNS解析的时间,加快用户访问速度,有兴趣的可以网络搜索下 |
| port | port(端口)是用来区分不同的网络服务的,从而实现在一个IP的基础上,提供多个网络服务 |
| url-path | url路径提供了如何对特定资源访问的详细信息,一般都是文件夹的路径 |
例子:下图展示了两个URI例子及它们的组成部分。

URI引用:
另一种类型的字符串——"URI引用"——代表一个URI并(相应地)代表被该URI所标识的资源。非正式使用中,URI和URI引用的区别少有被提及,但协议文档自然不应允许歧义的存在。
URI引用可取用的格式包括完整URI,URI中协议特定的部分,或其后附部分——甚至是空字符串。一个可选的片段标识符以#开头,可出现在URI引用的结尾。引用中,#之前的部分间接标识一个资源,而片段标识符则标识资源的某个部分。
为从URI引用获得URI,软件将URI引用与一个绝对"基址"基于一个固定算法合并,并转换为"绝对"形式。系统将URI引用视作相对于基址URI,虽然在绝对引用的情况下基址并无意义。基址URI一般标识包含URI引用的文档,但仍可被文档内包含的声明,或外部数据传输协议所包括的声明改写。若基址URI包括一个片段标识符,则该标识符在合并过程中被忽略。如果在URI引用中出现片段标识符,则在合并过程中被保留。
网络文档标记语言时常使用URI引用指向其它资源,如外部文档或同一逻辑文档的其他部分等。在HTML中,img元素的src属性值是URI引用,a或link元素的href属性值亦如是。在XML中,在一个DTD中的SYSTEM关键字之后出现的系统描述符是一个无片段的URI引用。在XSLT中,xsl:import元素/指令的href属性值是一个URI引用,document()函数的第一个参数与之相仿。
# 绝对URI
http://example.org/absolute/URI/with/absolute/path/to/resource.txt
ftp://example.org/resource.txt
urn:issn:1535-3613
# URI引用
http://en.wikipedia.org/wiki/URI#Examples_of_URI_references ("http" 指定协议名, "en.wikipedia.org"是“典据”, "/wiki/URI"是指向英文维基页面的“路径”,而"#Examples_of_URI_references"是指向英文维基页面相应片段的“片段”。)
http://example.org/absolute/URI/with/absolute/path/to/resource.txt
//example.org/scheme-relative/URI/with/absolute/path/to/resource.txt
/relative/URI/with/absolute/path/to/resource.txt
relative/path/to/resource.txt
../../../resource.txt
./resource.txt#frag01
resource.txt
#frag01
(空字符串)
URI解析: "解析"一个URI意味着将一个相对URI引用转换为绝对形式,或者通过尝试获取一个可解引URI或一个URI引用所代表的资源来解引用这个URI。文档处理软件的"解析"部分通常同时提供这两种功能。
一个URI引用可以是一个同文档引用:一个指向包含URI引用自身的文档的引用。文档处理软件可有效地使用其当前的文档资源来完成对于同文档引用的解析而不需要重新获取一份资源。这只是一个建议——文档处理软件自然可以选用另外的方法来决定是否获取新资源。
2.2 TCP/IP模型
TCP/IP协议模型(Transmission Control Protocol/Internet Protocol),包含了一系列构成互联网基础的网络协议,是Internet的核心协议。
基于TCP/IP的参考模型将协议分成四个层次,它们分别是链路层、网络层、传输层和应用层。下图表示TCP/IP模型与OSI模型各层的对照关系。

TCP/IP协议族按照层次由上到下,层层包装。最上面的是应用层,这里面有http,ftp等等我们熟悉的协议。而第二层则是传输层,著名的TCP和UDP协议就在这个层次。第三层是网络层,IP协议就在这里,它负责对数据加上IP地址和其他的数据以确定传输的目标。第四层是数据链路层,这个层次为待传送的数据加入一个以太网协议头,并进行CRC编码,为最后的数据传输做准备。

上图清楚地表示了TCP/IP协议中每个层的作用,而TCP/IP协议通信的过程其实就对应着数据入栈与出栈的过程。入栈的过程,数据发送方每层不断地封装首部与尾部,添加一些传输的信息,确保能传输到目的地。出栈的过程,数据接收方每层不断地拆除首部与尾部,得到最终传输的数据。
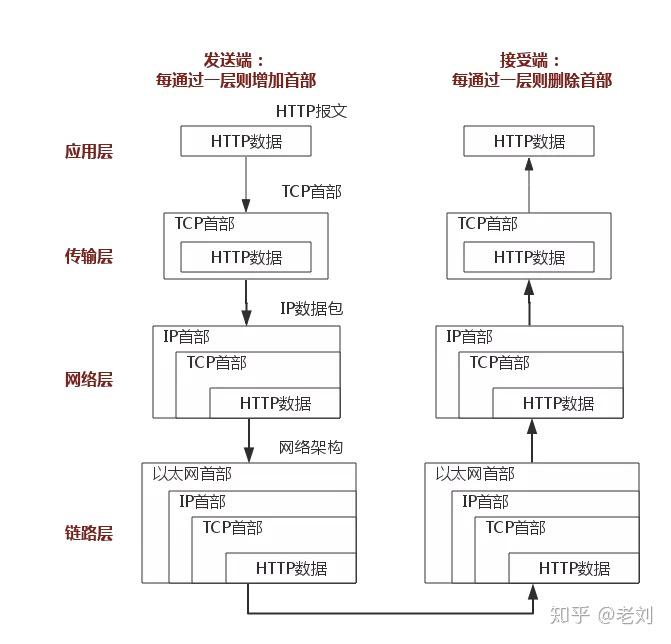
上图以HTTP协议为例,具体说明。
- 数据链路层
物理层负责0、1比特流与物理设备电压高低、光的闪灭之间的互换。数据链路层负责将0、1序列划分为数据帧从一个节点传输到临近的另一个节点,这些节点是通过MAC来唯一标识的(MAC,物理地址,一个主机会有一个MAC地址)。
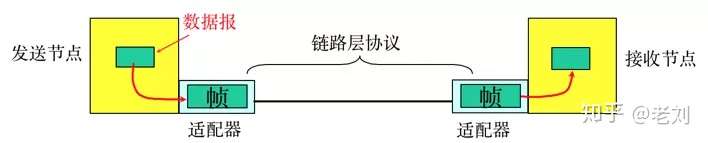
封装成帧:把网络层数据报加头和尾,封装成帧,帧头中包括源
MAC地址和目的MAC地址。透明传输:零比特填充、转义字符。
可靠传输: 在出错率很低的链路上很少用,但是无线链路WLAN会保证可靠传输。
差错检测(CRC):接收者检测错误,如果发现差错,丢弃该帧。
- 网络层
IP协议
在数据链路层中我们一般通过MAC地址来识别不同的节点,而在IP层我们也要有一个类似的地址标识,这就是IP地址。32位IP地址分为网络位和地址位,这样做可以减少路由器中路由表记录的数目,有了网络地址,就可以限定拥有相同网络地址的终端都在同一个范围内,那么路由表只需要维护一条这个网络地址的方向,就可以找到相应的这些终端了。
A类IP地址:0.0.0.0~127.0.0.0
B类IP地址:128.0.0.1~191.255.0.0
C类IP地址:192.168.0.0~239.255.255.0

八位的TTL字段,这个字段规定该数据包在穿过多少个路由之后才会被抛弃。某个IP数据包每穿过一个路由器,该数据包的TTL数值就会减少1,当该数据包的TTL成为零,它就会被自动抛弃。
这个字段的最大值也就是255,也就是说一个协议包也就在路由器里面穿行255次就会被抛弃了,根据系统的不同,这个数字也不一样,一般是32或者是64。
ARP及RARP协议
ARP是根据IP地址获取MAC地址的一种协议。ARP(地址解析)协议是一种解析协议,本来主机是完全不知道这个IP对应的是哪个主机的哪个接口,当主机要发送一个IP包的时候,会首先查一下自己的ARP高速缓存(就是一个IP-MAC地址对应表缓存)。
如果查询的IP-MAC值对不存在,那么主机就向网络发送一个ARP协议广播包,这个广播包里面就有待查询的IP地址,而直接收到这份广播的包的所有主机都会查询自己的IP地址,如果收到广播包的某一个主机发现自己符合条件,那么就准备好一个包含自己的MAC地址的ARP包传送给发送ARP广播的主机。
而广播主机拿到ARP包后会更新自己的ARP缓存(就是存放IP-MAC对应表的地方)。发送广播的主机就会用新的ARP缓存数据准备好数据链路层的的数据包发送工作。
RARP协议的工作与此相反,不做赘述。
ICMP协议
IP协议并不是一个可靠的协议,它不保证数据被送达,那么,自然的,保证数据送达的工作应该由其他的模块来完成。其中一个重要的模块就是ICMP(网络控制报文)协议。ICMP不是高层协议,而是IP层的协议。
当传送IP数据包发生错误。比如主机不可达,路由不可达等等,ICMP协议将会把错误信息封包,然后传送回给主机。给主机一个处理错误的机会,这 也就是为什么说建立在IP层以上的协议是可能做到安全的原因。
检测工具
ping可以说是ICMP的最著名的应用,是TCP/IP协议的一部分。利用"ping"命令可以检查网络是否连通,可以很好地帮助我们分析和判定网络故障。
例如:当我们某一个网站上不去的时候。通常会ping一下这个网站。ping会回显出一些有用的信息。一般的信息如下:

ping这个单词源自声纳定位,而这个程序的作用也确实如此,它利用ICMP协议包来侦测另一个主机是否可达。原理是用类型码为0的ICMP发请 求,受到请求的主机则用类型码为8的ICMP回应。ping程序来计算间隔时间,并计算有多少个包被送达。用户就可以判断网络大致的情况。我们可以看到, ping给出来了传送的时间和TTL的数据。
Traceroute是用来侦测主机到目的主机之间所经路由情况的重要工具,也是最便利的工具。
Traceroute的原理是非常非常的有意思,它收到到目的主机的IP后,首先给目的主机发送一个TTL=1的UDP数据包,而经过的第一个路由器收到这个数据包以后,就自动把TTL减1,而TTL变为0以后,路由器就把这个包给抛弃了,并同时产生一个主机不可达的ICMP数据报给主机。主机收到这个数据报以后再发一个TTL=2的UDP数据报给目的主机,然后刺激第二个路由器给主机发ICMP数据报。如此往复直到到达目的主机。这样,traceroute就拿到了所有的路由器IP。
TCP/UDP
TCP/UDP都是是传输层协议,但是两者具有不同的特性,同时也具有不同的应用场景,下面以图表的形式对比分析。

面向报文:面向报文的传输方式是应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。因此,应用程序必须选择合适大小的报文。若报文太长,则IP层需要分片,降低效率。若太短,会是IP太小。
面向字节流:面向字节流的话,虽然应用程序和TCP的交互是一次一个数据块(大小不等),但TCP把应用程序看成是一连串的无结构的字节流。TCP有一个缓冲,当应用程序传送的数据块太长,TCP就可以把它划分短一些再传送。
TCP和UDP协议的一些应用
什么时候应该使用TCP:当对网络通讯质量有要求的时候,比如:整个数据要准确无误的传递给对方,这往往用于一些要求可靠的应用,比如HTTP、HTTPS、FTP等传输文件的协议,POP、SMTP等邮件传输的协议。
什么时候应该使用UDP:当对网络通讯质量要求不高的时候,要求网络通讯速度能尽量的快,这时就可以使用UDP。
- TCP连接的建立与终止
三次握手
TCP是面向连接的,无论哪一方向另一方发送数据之前,都必须先在双方之间建立一条连接。在TCP/IP协议中,TCP协议提供可靠的连接服务,连接是通过三次握手进行初始化的。三次握手的目的是同步连接双方的序列号和确认号并交换 TCP窗口大小信息。
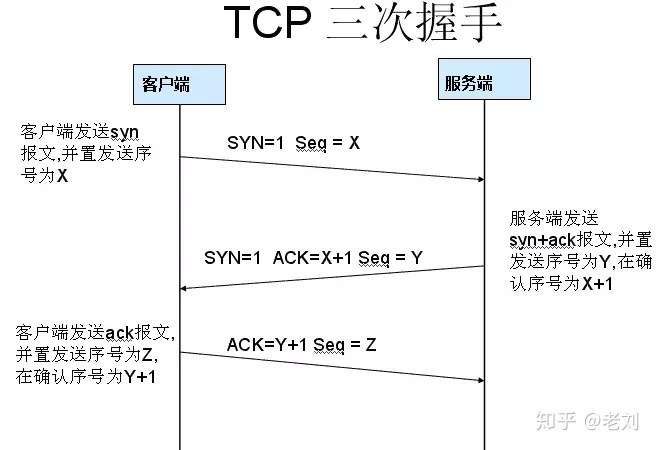
第一次握手: 建立连接。客户端发送连接请求报文段,将SYN位置为1,Sequence Number为x;然后,客户端进入
SYN_SEND状态,等待服务器的确认;第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置Acknowledgment Number为x+1(Sequence Number+1);同时,自己自己还要发送SYN请求信息,将SYN位置为1,Sequence Number为y;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入
SYN_RECV状态;第三次握手: 客户端收到服务器的SYN+ACK报文段。然后将Acknowledgment Number设置为y+1,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手。
为什么要三次握手:为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
具体例子:"已失效的连接请求报文段"的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。”
四次挥手
当客户端和服务器通过三次握手建立了TCP连接以后,当数据传送完毕,肯定是要断开TCP连接的啊。那对于TCP的断开连接,这里就有了神秘的“四次分手”。
第一次分手: 主机1(可以使客户端,也可以是服务器端),设置Sequence Number,向主机2发送一个FIN报文段;此时,主机1进入
FIN_WAIT_1状态;这表示主机1没有数据要发送给主机2了;第二次分手: 主机2收到了主机1发送的FIN报文段,向主机1回一个ACK报文段,Acknowledgment Number为Sequence Number加1;主机1进入
FIN_WAIT_2状态;主机2告诉主机1,我“同意”你的关闭请求;第三次分手: 主机2向主机1发送FIN报文段,请求关闭连接,同时主机2进入
LAST_ACK状态;第四次分手: 主机1收到主机2发送的FIN报文段,向主机2发送ACK报文段,然后主机1进入
TIME_WAIT状态;主机2收到主机1的ACK报文段以后,就关闭连接;此时,主机1等待2MSL后依然没有收到回复,则证明Server端已正常关闭,那好,主机1也可以关闭连接了。
为什么要四次分手?TCP协议是一种面向连接的、可靠的、基于字节流的运输层通信协议。TCP是全双工模式,这就意味着,当主机1发出FIN报文段时,只是表示主机1已经没有数据要发送了,主机1告诉主机2,它的数据已经全部发送完毕了;但是,这个时候主机1还是可以接受来自主机2的数据;当主机2返回ACK报文段时,表示它已经知道主机1没有数据发送了,但是主机2还是可以发送数据到主机1的;当主机2也发送了FIN报文段时,这个时候就表示主机2也没有数据要发送了,就会告诉主机1,我也没有数据要发送了,之后彼此就会愉快的中断这次TCP连接。
- TCP流量控制
如果发送方把数据发送得过快,接收方可能会来不及接收,这就会造成数据的丢失。所谓流量控制就是让发送方的发送速率不要太快,要让接收方来得及接收。
利用滑动窗口机制可以很方便地在TCP连接上实现对发送方的流量控制。
设A向B发送数据。在连接建立时,B告诉了A:“我的接收窗口是rwnd = 400”(这里的rwnd表示receiver window) 。因此,发送方的发送窗口不能超过接收方给出的接收窗口的数值。请注意,TCP的窗口单位是字节,不是报文段。假设每一个报文段为100字节长,而数据报文段序号的初始值设为1。大写ACK表示首部中的确认位ACK,小写ack表示确认字段的值ack。

从图中可以看出,B进行了三次流量控制。第一次把窗口减少到rwnd=300,第二次又减到了rwnd=100,最后减到rwnd=0,即不允许发送方再发送数据了。这种使发送方暂停发送的状态将持续到主机B重新发出一个新的窗口值为止。B向A发送的三个报文段都设置了ACK=1,只有在ACK=1时确认号字段才有意义。
TCP为每一个连接设有一个持续计时器(persistence timer)。只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口控测报文段(携1字节的数据),那么收到这个报文段的一方就重新设置持续计时器。
- TCP拥塞控制
慢开始和拥塞避免
发送方维持一个拥塞窗口cwnd(congestion window)的状态变量。拥塞窗口的大小取决于网络的拥塞程度,并且动态地在变化。发送方让自己的发送窗口等于拥塞窗口。
发送方控制拥塞窗口的原则是:只要网络没有出现拥塞,拥塞窗口就再增大一些,以便把更多的分组发送出去。但只要网络出现拥塞,拥塞窗口就减小一些,以减少注入到网络中的分组数。
慢开始算法
当主机开始发送数据时,如果立即所大量数据字节注入到网络,那么就有可能引起网络拥塞,因为现在并不清楚网络的负荷情况。
因此,较好的方法是先探测一下,即由小到大逐渐增大发送窗口,也就是说,由小到大逐渐增大拥塞窗口数值。
通常在刚刚开始发送报文段时,先把拥塞窗口cwnd设置为一个最大报文段MSS的数值。而在每收到一个对新的报文段的确认后,把拥塞窗口增加至多一个MSS的数值。用这样的方法逐步增大发送方的拥塞窗口cwnd,可以使分组注入到网络的速率更加合理。
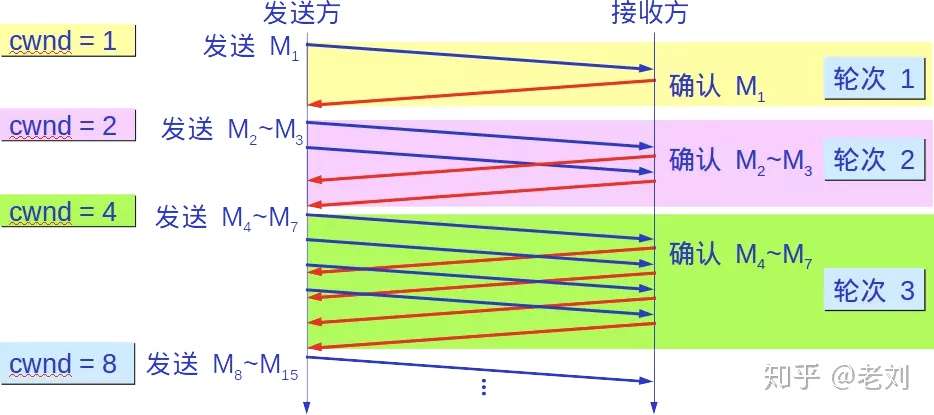
每经过一个传输轮次,拥塞窗口cwnd就加倍。一个传输轮次所经历的时间其实就是往返时间RTT。不过“传输轮次”更加强调:把拥塞窗口cwnd所允许发送的报文段都连续发送出去,并收到了对已发送的最后一个字节的确认。
另,慢开始的“慢”并不是指cwnd的增长速率慢,而是指在TCP开始发送报文段时先设置cwnd=1,使得发送方在开始时只发送一个报文段(目的是试探一下网络的拥塞情况),然后再逐渐增大cwnd。
为了防止拥塞窗口cwnd增长过大引起网络拥塞,还需要设置一个慢开始门限ssthresh状态变量。慢开始门限ssthresh的用法如下:
当
cwnd<ssthresh时,使用上述的慢开始算法。当
cwnd>ssthresh时,停止使用慢开始算法而改用拥塞避免算法。当
cwnd=ssthresh时,既可使用慢开始算法,也可使用拥塞控制避免算法。
拥塞避免
让拥塞窗口cwnd缓慢地增大,即每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,而不是加倍。这样拥塞窗口cwnd按线性规律缓慢增长,比慢开始算法的拥塞窗口增长速率缓慢得多。
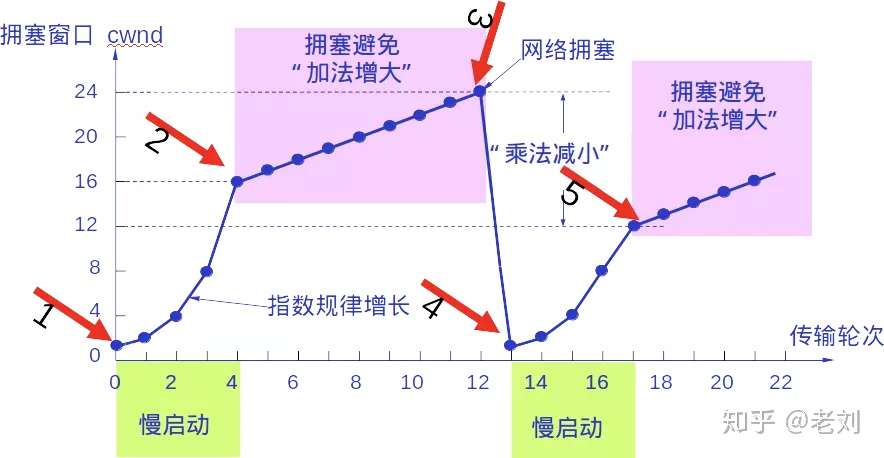
无论在慢开始阶段还是在拥塞避免阶段,只要发送方判断网络出现拥塞(其根据就是没有收到确认),就要把慢开始门限ssthresh设置为出现拥塞时的发送 方窗口值的一半(但不能小于2)。然后把拥塞窗口cwnd重新设置为1,执行慢开始算法。
这样做的目的就是要迅速减少主机发送到网络中的分组数,使得发生 拥塞的路由器有足够时间把队列中积压的分组处理完毕。
如下图,用具体数值说明了上述拥塞控制的过程。现在发送窗口的大小和拥塞窗口一样大。
- 快重传和快恢复
快重传
快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认(为的是使发送方及早知道有报文段没有到达对方)而不要等到自己发送数据时才进行捎带确认。

接收方收到了M1和M2后都分别发出了确认。现在假定接收方没有收到M3但接着收到了M4。
显然,接收方不能确认M4,因为M4是收到的失序报文段。根据 可靠传输原理,接收方可以什么都不做,也可以在适当时机发送一次对M2的确认。
但按照快重传算法的规定,接收方应及时发送对M2的重复确认,这样做可以让 发送方及早知道报文段M3没有到达接收方。发送方接着发送了M5和M6。接收方收到这两个报文后,也还要再次发出对M2的重复确认。这样,发送方共收到了 接收方的四个对M2的确认,其中后三个都是重复确认。
快重传算法还规定,发送方只要一连收到三个重复确认就应当立即重传对方尚未收到的报文段M3,而不必 继续等待M3设置的重传计时器到期。
由于发送方尽早重传未被确认的报文段,因此采用快重传后可以使整个网络吞吐量提高约20%。
快恢复
与快重传配合使用的还有快恢复算法,其过程有以下两个要点:
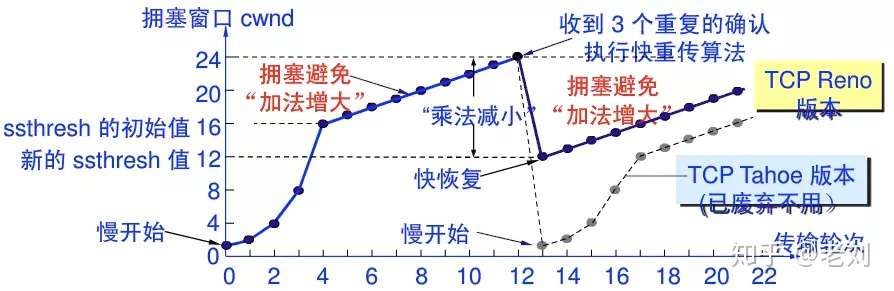
当发送方连续收到三个重复确认,就执行“乘法减小”算法,把慢开始门限ssthresh减半。
与慢开始不同之处是现在不执行慢开始算法(即拥塞窗口cwnd现在不设置为1),而是把cwnd值设置为 慢开始门限ssthresh减半后的数值,然后开始执行拥塞避免算法(“加法增大”),使拥塞窗口缓慢地线性增大。
三、时间协议
3.1 格式标示符
常见的时间格式标识符:
| 符号 | 说明 |
|---|---|
| %% | 显示一个百分号'%' |
| %a | 星期的简称,如:Sun/Mon/Tue/Wed/... |
| %A | 星期完整名字,如:Sunday/Monday/... |
| %b | 月份简称,如:Jan/Feb/... |
| %B | 月份全称,如:January/February/... |
| %c | 显示当前日期和时间,如:Thu Mar 3 23:05:25 2005 |
| %C | 世纪,如:现在是20世纪,输入date +"%C"显示20 |
| %d | 日期,如当前是8号,则显示:08 |
| %D | 完整日期,date +"%D"相当于date +"%m/%d/%y" |
| %e | 日期,用空格补全,而不是0,如当前日期:7号,则显示"7" |
| %F | 完整日期,相当于:date +"%Y-%m-%d" |
| %g | 年份后2位,如果是2017,则为:17 |
| %G | 年份全4位,如2017 |
| %h | 月份简称,如:Jan/Feb/Mar/...,跟%b相同 |
| %H | 小时(00/01/02/..23),24小时制 |
| %I | 小时(01/02/..12),12小时制 |
| %j | 一年的第几天(001/002/..366) |
| %k | 小时,填充空格,如(0/1/2/..23);相当于%_H |
| %l | 小时,填充空格(1/2/3/..12);相当于%_I |
| %m | 月份(01/02/03/..12) |
| %M | 分钟(00/01/02/..59) |
| %n | 换行,date +"%d%n%d",将会分成两行分别显示日期 |
| %N | 纳秒(000000000/000000001/..999999999) |
| %p | AM/PM,即上午或者下午 |
| %P | 跟%p意思一样,不过是小写字母,即am/pm |
| %r | 显示12小时制的当前时间,如:10:48:05 PM |
| %R | 24小时制的当前时间和分钟,相当于:%H:%M,22:49 |
| %s | 从1970-01-01 00:00:00UTC开始的秒数,相当于日期转时间戳 |
| %S | 秒(00/01/02/..60) |
| %t | 一个tab键,制表符 |
| %T | 当前时间,相当于:%H:%M:%S。如:22:52:07 |
| %u | 星期中的第几天(1/2/..7);1是星期一 |
| %U | 一年中的第几个星期(00..53),星期天作为一个星期的第一天 |
| %V | 一年中的第几个星期(ISO标准)(01..53),星期一作为一个星期的第一天 |
| %w | 星期中的第几天(0..6);0是星期天 |
| %W | 一年中的第几个星期(00..53),星期一作为一个星期的第一天 |
| %x | 当前日期(例如:03/07/17) |
| %X | 当前时间(例如:23:13:48) |
| %y | 年的后两位(00/02/..99) |
| %Y | 年,如:2017 |
| %z | +hhmm数字时区(例如:北京:+0800) |
| %:z | +hh:mm数字时区(例如:北京:+08:00) |
| %::z | +hh:mm:ss数字时区(例如:北京:+08:00:00) |
| %:::z | numerictime zone with:tonecessary precision(e.g.,-04,+05:30) |
| %Z | 字母时区缩写(如CST) |
3.2 date命令
- 显示当前时间和按指定格式显示时间
date +"%Y/%m/%d %H:%m:%S"
- 时间解析,将输入的字符串解析为时间
date -d "20170305" //解析日期, 输出:Sun Mar 5 00:00:00 CST 2017。
date -d "03/05/2017"
date -d "2017/03/05 11:12:13" // 解析日期和时间, 输出: Sun Mar 5 11:12:13 CST 2017。
date -d "2017-03-05 21:12:17" +"%s" // 将输入时间转为时间戳,输出:1488719537。
date -d "2017-03-05 21:12:17" +"%Y/%m/%d %H:%M:%S" // 时间格式转换,将输入日期转换为自定义格式。
- 时间数字、时间整数、时间戳转字符串和数字和字符串时间转换
date --date @1488899583 // 将从1970-01-01 00:00:00 UTC开始的秒数,转为字符串时间
date --date @"1488899583" // 同上,即时间戳转字符串,或者整数秒转字符串时间。
date +"%s" // 日期转时间戳,日期转整数。
- 设置当前时间
date -s "2017/05/08 23:28:13" // 设置日期和时间
date -s "2017/05/08" // 设置日期(注意,时间会同时被设置为00:00:00,慎用)。
date -s "23:28:13" // 设置时间。
- 时间运算
// 时间加减运算
// 直接用-d命令结合year/month/week/day/hour/minute/second, 单复数都行
date -d "+1 days" // 明天,当前时间加1天。
date -d "+2 days" // 后天,当前时间加2天。
date -d "+10 days" +"%Y%m%d %H:%M:%S" // 当前时间加10天,并按指定格式输出。
date -d "-1 days" // 昨天,当前时间减1天。
date -d "-2 days" // 前天,当前时间减2天。
date -d "2017/03/05 +1 days" // 指定日期加1天。
date -d "2017/03/05 -1 days" // 指定日期减1天。
date -d "2017/03/08 +600 seconds" // 指定日期加600秒。
date -d "2017/03/08 -600 seconds" // 指定日期减600秒。
date -d "2017/03/08 +600 minutes" // 指定日期加600分钟。
date -d "2017/03/08 -600 minutes" // 指定日期减600分钟。
date -d "2017/03/08 +10 year" // 指定日期加10年。
date -d "Tue Mar 10 14:12:13 CST 2015 +1 days" // 指定日期时间,加一天。
date -d "15:21:11 03/18/2017 -1 days" // 指定日期时间,减一天。注:时间放在日期的后面目前似乎不可用。
数字可以用next,last代替,明天,昨天也可以tomorrow,yesterday来制定
- 时间相关代码模版
# 根据时间运行程序
startdate=2018090314
enddate=2018083022
for i in `seq 1 300`; do
if [[ $startdate -lt $enddate ]]; then
break
fi
# 拼接成YYYYmmdd HH的格式,否则使用下个命令中+%s,会无法转换
startdate=${startdate:0:4}"-"${startdate:4:2}"-"${startdate:6:2}" "${startdate:8:2}
# 转换成时间戳,+%s为时间格式
startdate=$(date +%s -d "$startdate")
# 每次执行后,开始日期减一个小时
startdate=$(($startdate-1*60*60))
# 时间戳转正常格式时间
startdate=$(date +%Y%m%d%H -d "1970-01-01 UTC $startdate seconds")
# 执行程序
echo ${startdate}
done
3.3 python函数
3.3.1 time模块
time模块中时间表现的格式主要有三种:
- timestamp时间戳:时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量
struct_time时间元组 共有九个元素组。
struct_time元组元素结构
属性 值
tm_year(年) 比如2011
tm_mon(月) 1 - 12
tm_mday(日) 1 - 31
tm_hour(时) 0 - 23
tm_min(分) 0 - 59
tm_sec(秒) 0 - 61
tm_wday(weekday) 0 - 6(0表示周日)
tm_yday(一年中的第几天) 1 - 366
tm_isdst(是否是夏令时) 默认为-1
- format time格式化时间 已格式化的结构使时间更具可读性。包括自定义格式和固定格式。
- 时间格式转换图

# 代码转化示例
import time
time.time() # 生成timestamp : 1545018718.573361
time.localtime() # 生成struct_time : time.struct_time(tm_year=2018, tm_mon=12, tm_mday=17, tm_hour=11, tm_min=56, tm_sec=8, tm_wday=0, tm_yday=351, tm_isdst=0)
time.mktime(time.localtime()) # struct_time to timestamp
time.localtime(time.time()) # timestamp to struct_time 本地时间
# 格林威治时间
time.gmtime()
time.gmtime(time.time())
time.strptime('2011-05-05 16:37:06', '%Y-%m-%d %X') # format_time to struct_time
# 生成format_time 以及struct_time to format_time
time.strftime("%Y-%m-%d %X")
time.strftime("%Y-%m-%d %X",time.localtime())
# 生成固定格式的时间表示格式
time.asctime(time.localtime())
time.ctime(time.time())
# Wed Oct 26 16:45:08 2016
3.3.2 datetime模块
datatime模块重新封装了time模块,提供更多接口,提供的类有:date,time,datetime,timedelta,tzinfo。
- date类:datetime.date(year, month, day)
静态方法和字段:
date.max、date.min:date对象所能表示的最大、最小日期;
date.resolution:date对象表示日期的最小单位。这里是天。
date.today():返回一个表示当前本地日期的date对象;
date.fromtimestamp(timestamp):根据给定的时间戮,返回一个date对象;
方法和属性:
d1 = date(2011,06,03) # date对象
d1.year、date.month、date.day:年、月、日;
d1.replace(year, month, day):生成一个新的日期对象,用参数指定的年,月,日代替原有对象中的属性。(原有对象仍保持不变)
d1.timetuple():返回日期对应的time.struct_time对象;
d1.weekday():返回weekday,如果是星期一,返回0;如果是星期2,返回1,以此类推;
d1.isoweekday():返回weekday,如果是星期一,返回1;如果是星期2,返回2,以此类推;
d1.isocalendar():返回格式如(year,month,day)的元组;
d1.isoformat():返回格式如'YYYY-MM-DD’的字符串;
d1.strftime(fmt):和time模块format相同。
- time类:datetime.time(hour[,minute[,second[,microsecond[,tzinfo]]]])
静态方法和字段:
time.min、time.max:time类所能表示的最小、最大时间。其中,time.min = time(0, 0, 0, 0), time.max = time(23, 59, 59, 999999);
time.resolution:时间的最小单位,这里是1微秒;
方法和属性:
t1 = datetime.time(10,23,15)#time对象
t1.hour、t1.minute、t1.second、t1.microsecond:时、分、秒、微秒;
t1.tzinfo:时区信息;
t1.replace([ hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] ):创建一个新的时间对象,用参数指定的时、分、秒、微秒代替原有对象中的属性(原有对象仍保持不变);
t1.isoformat():返回型如"HH:MM:SS"格式的字符串表示;
t1.strftime(fmt):同time模块中的format;
- datetime类
datetime相当于date和time结合起来。
datetime.datetime(year,month,day[,hour[,minute[,second[,microsecond[,tzinfo]]]]])
静态方法和字段:
datetime.today():返回一个表示当前本地时间的datetime对象;
datetime.now([tz]):返回一个表示当前本地时间的datetime对象,如果提供了参数tz,则获取tz参数所指时区的本地时间;
datetime.utcnow():返回一个当前utc时间的datetime对象;#格林威治时间
datetime.fromtimestamp(timestamp[, tz]):根据时间戮创建一个datetime对象,参数tz指定时区信息;
datetime.utcfromtimestamp(timestamp):根据时间戮创建一个datetime对象;
datetime.combine(date, time):根据date和time,创建一个datetime对象;
datetime.strptime(date_string, format):将格式字符串转换为datetime对象;
方法和属性:
dt=datetime.now() # datetime对象
dt.year、month、day、hour、minute、second、microsecond、tzinfo:
dt.date():获取date对象;
dt.time():获取time对象;
dt.replace ([ year[ , month[ , day[ , hour[ , minute[ , second[ , microsecond[ , tzinfo] ] ] ] ] ] ] ]):
dt.timetuple ()
dt.utctimetuple ()
dt.toordinal ()
dt.weekday ()
dt.isocalendar ()
dt.isoformat ([ sep] )
dt.ctime ():返回一个日期时间的C格式字符串,等效于time.ctime(time.mktime(dt.timetuple()));
dt.strftime (format)
- timedelta类,时间加减
在模板和tuple之间,有一个%号分隔,它代表了格式化操作。使用timedelta可以很方便的在日期上做天days,小时hour,分钟,秒,毫秒,微妙的时间计算,如果要计算月份则需要另外的办法。
from datetime import *
dt = datetime.now()
#日期减一天
dt1 = dt + timedelta(days=-1)#昨天
dt2 = dt - timedelta(days=1)#昨天
dt3 = dt + timedelta(days=1)#明天
delta_obj = dt3-dt
print type(delta_obj),delta_obj # <type 'datetime.timedelta'> 1 day, 0:00:00
print delta_obj.days ,delta_obj.total_seconds() # 1 86400.0
- tzinfo时区类
from datetime import datetime, tzinfo,timedelta
"""
tzinfo是关于时区信息的类
tzinfo是一个抽象类,所以不能直接被实例化
"""
class UTC(tzinfo):
"""UTC"""
def __init__(self,offset = 0):
self._offset = offset
def utcoffset(self, dt):
return timedelta(hours=self._offset)
def tzname(self, dt):
return "UTC +%s" % self._offset
def dst(self, dt):
return timedelta(hours=self._offset)
# 北京时间
beijing = datetime(2011,11,11,0,0,0,tzinfo = UTC(8))
print("beijing time:",beijing)
# 曼谷时间
bangkok = datetime(2011,11,11,0,0,0,tzinfo = UTC(7))
print("bangkok time",bangkok)
# 北京时间转成曼谷时间
print("beijing-time to bangkok-time:",beijing.astimezone(UTC(7)))
# 计算时间差时也会考虑时区的问题
timespan = beijing - bangkok
print("时差:",timespan)
3.3.3 calendar模块
calendar模块定义了Calendar类,它封装了值的计算,比如计算给定月份或年份中周的日期。此外,TextCalendar和HTMLCalendar类可以生成预格式化的输出。
- 格式化示例
prmonth()方法是很简单,可以生成一个月的格式化文本输出。
import calendar
c = calendar.TextCalendar(calendar.SUNDAY)
c.prmonth(2017, 7)
# 输出
# July 2017
# Su Mo Tu We Th Fr Sa
# 1
# 2 3 4 5 6 7 8
# 9 10 11 12 13 14 15
# 16 17 18 19 20 21 22
# 23 24 25 26 27 28 29
# 30 31
根据TextCalendar美国惯例,该示例配置为在周日开始周。默认是使用星期一开始一周的欧洲惯例。可以使用HTMLCalendar和formatmonth()生成类似HTML的表格。呈现的输出看起来与纯文本大致相同,但是用HTML标记包装。每个表格单元格都有一个与星期几相对应的类属性,因此HTML可以通过CSS设置样式。
要以不同于其中一个可用默认值的格式生成输出,请使用calendar计算日期并将值组织为周和月范围,然后迭代结果。Calendar模块的weekheader(),monthcalendar()和yeardays2calendar()方法对此特别有用。
调用yeardays2calendar()会生成一系列“月份行”列表。每个列表包括月份作为另一个周列表。这几周是由日期编号(1-31)和工作日编号(0-6)组成的元组列表。超出月份的天数为0。
import calendar
import pprint
cal = calendar.Calendar(calendar.SUNDAY)
cal_data = cal.yeardays2calendar(2017, 3)
print('len(cal_data) :', len(cal_data))
top_months = cal_data[0]
print('len(top_months) :', len(top_months))
first_month = top_months[0]
print('len(first_month) :', len(first_month))
print('first_month:')
pprint.pprint(first_month, width=65)
# 输出
# len(cal_data) : 4
# len(top_months) : 3
# len(first_month) : 5
# first_month:
# [[(1, 6), (2, 0), (3, 1), (4, 2), (5, 3), (6, 4), (7, 5)],
# [(8, 6), (9, 0), (10, 1), (11, 2), (12, 3), (13, 4), (14, 5)],
# [(15, 6), (16, 0), (17, 1), (18, 2), (19, 3), (20, 4), (21, 5)],
# [(22, 6), (23, 0), (24, 1), (25, 2), (26, 3), (27, 4), (28, 5)],
# [(29, 6), (30, 0), (31, 1), (0, 2), (0, 3), (0, 4), (0, 5)]]
相当于使用formatyear()。
import calendar
cal = calendar.TextCalendar(calendar.SUNDAY)
print(cal.formatyear(2017, 2, 1, 1, 3))
# 输出
# 2017
#
# January February March
# Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
# 1 2 3 4 5 6 7 1 2 3 4 1 2 3 4
# 8 9 10 11 12 13 14 5 6 7 8 9 10 11 5 6 7 8 9 10 11
# 15 16 17 18 19 20 21 12 13 14 15 16 17 18 12 13 14 15 16 17 18
# 22 23 24 25 26 27 28 19 20 21 22 23 24 25 19 20 21 22 23 24 25
# 29 30 31 26 27 28 26 27 28 29 30 31
#
# April May June
# Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
# 1 1 2 3 4 5 6 1 2 3
# 2 3 4 5 6 7 8 7 8 9 10 11 12 13 4 5 6 7 8 9 10
# 9 10 11 12 13 14 15 14 15 16 17 18 19 20 11 12 13 14 15 16 17
# 16 17 18 19 20 21 22 21 22 23 24 25 26 27 18 19 20 21 22 23 24
# 23 24 25 26 27 28 29 28 29 30 31 25 26 27 28 29 30
# 30
#
# July August September
# Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
# 1 1 2 3 4 5 1 2
# 2 3 4 5 6 7 8 6 7 8 9 10 11 12 3 4 5 6 7 8 9
# 9 10 11 12 13 14 15 13 14 15 16 17 18 19 10 11 12 13 14 15 16
# 16 17 18 19 20 21 22 20 21 22 23 24 25 26 17 18 19 20 21 22 23
# 23 24 25 26 27 28 29 27 28 29 30 31 24 25 26 27 28 29 30
# 30 31
#
# October November December
# Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa Su Mo Tu We Th Fr Sa
# 1 2 3 4 5 6 7 1 2 3 4 1 2
# 8 9 10 11 12 13 14 5 6 7 8 9 10 11 3 4 5 6 7 8 9
# 15 16 17 18 19 20 21 12 13 14 15 16 17 18 10 11 12 13 14 15 16
# 22 23 24 25 26 27 28 19 20 21 22 23 24 25 17 18 19 20 21 22 23
# 29 30 31 26 27 28 29 30 24 25 26 27 28 29 30
# 31
day_name,day_abbr,month_name和month_abbr模块主要用于生产定制格式化输出(即包括在HTML输出链接)。它们会针对当前区域自动化配置。
- 区域设置
如果想生成非默认区域的格式化日历,可以使用LocaleTextCalendar或LocaleHTMLCalendar。
import calendar
c = calendar.LocaleTextCalendar(locale='en_US')
c.prmonth(2017, 7)
print()
c = calendar.LocaleTextCalendar(locale='fr_FR')
c.prmonth(2017, 7)
# 输出
# July 2017
# Mo Tu We Th Fr Sa Su
# 1 2
# 3 4 5 6 7 8 9
# 10 11 12 13 14 15 16
# 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30
# 31
#
# juillet 2017
# Lu Ma Me Je Ve Sa Di
# 1 2
# 3 4 5 6 7 8 9
# 10 11 12 13 14 15 16
# 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30
# 31
一周的第一天不是语言环境设置的一部分,而且这个值就是该类的一个参数,就像TextCalendar一样。
- 计算日期
虽然日历模块主要侧重于以各种格式打印完整日历,但它还提供了以其他方式处理日期的有用功能,例如计算重复事件的日期。例如,Python亚特兰大用户组在每个月的第二个星期四开会。要计算一年的会议日期,请使用monthcalendar()。
import calendar
import pprint
pprint.pprint(calendar.monthcalendar(2017, 7))
# 输出
# [[0, 0, 0, 0, 0, 1, 2],
# [3, 4, 5, 6, 7, 8, 9],
# [10, 11, 12, 13, 14, 15, 16],
# [17, 18, 19, 20, 21, 22, 23],
# [24, 25, 26, 27, 28, 29, 30],
# [31, 0, 0, 0, 0, 0, 0]]
0值是与给定月份重叠的一周中的时间,是另一个月的一部分。一周的第一天默认为星期一,可以通过调用setfirstweekday()来更改,但由于日历模块包含用于索引返回的日期范围的常量monthcalendar(),因此在这种情况下跳过该步骤更方便。要计算一年的小组会议日期,假设它们总是在每个月的第二个星期四,查看monthcalendar()输出来查找星期四。本月的第一周和最后一周填充0值作为前一个月或后一个月天数的占位符。例如,如果一个月在星期五开始,则星期四位置第一周的值将为0。
import calendar
import sys
year = int(sys.argv[1])
# Show every month
for month in range(1, 13):
# Compute the dates for each week that overlaps the month
c = calendar.monthcalendar(year, month)
first_week = c[0]
second_week = c[1]
third_week = c[2]
# If there is a Thursday in the first week, the second Thursday is # in the second week.
# Otherwise, the second Thursday must be in the third week.
if first_week[calendar.THURSDAY]:
meeting_date = second_week[calendar.THURSDAY]
else:
meeting_date = third_week[calendar.THURSDAY]
print('{:>3}: {:>2}'.format(calendar.month_abbr[month], meeting_date))
# 输出
# Jan: 12
# Feb: 9
# Mar: 9
# Apr: 13
# May: 11
# Jun: 8
# Jul: 13
# Aug: 10
# Sep: 14
# Oct: 12
# Nov: 9
# Dec: 14
- 其他可能有用的函数列表
| 序号 | 函数 | 描述 |
|---|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) | 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。每日宽度间隔为w字符,每行长度为21W+18+2C,l是每星期行数 |
| 2 | calendar.firstweekday() | 返回当前每周起始日期的设置。默认情况下,首次载入calendar模块时返回0,即星期一 |
| 3 | calendar.isleap(year) | 是闰年返回True,否则为false |
| 4 | calendar.leapdays(y1,y2) | 返回在Y1,Y2两年之间的闰年总数 |
| 5 | calendar.month(year,month,w=2,l=1) | 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符,每行的长度为7*w+6,l是每星期的行数 |
| 6 | calendar.monthcalendar(year,month) | 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数,Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始 |
| 7 | calendar.monthrange(year,month) | 返回两个整数,第一个是该月的星期几的日期码,第二个是该月的日期码。日从0(星期一)到6(星期日),月从1到12 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) | 相当于print calendar.calendar(year,w,l,c) |
| 9 | calendar.prmonth(year,month,w=2,l=1) | 相当于print calendar.calendar(year,w,l,c) |
| 10 | calendar.setfirstweekday(weekday) | 设置每周的起始日期码,0(星期一)到6(星期日) |
| 11 | calendar.timegm(tupletime),time.gmtime相反 | 接受一个时间元组形式,返回该时刻的时间辍(1970纪元后经过的浮点秒数) |
| 12 | calendar.weekday(year,month,day) | 返回给定日期的日期码,0(星期一)到6(星期日),月份为1(一月)到12(12月) |
四、邮件协议
4.1 POP3协议
POP3全称为Post Office Protocol version3,即邮局协议第3版。它被用户代理用来邮件服务器取得邮件。POP3采用的也是C/S通信模型,采用的是一问一答式的方式,你向服务器发送一个命令,服务器必然会回复一个信息对应的RFC文档为RFC1939。
- 通信过程
用户从邮件服务器上接收邮件的典型通信过程如下。
- 用户运行用户代理(如Foxmail, Outlook Express)。
- 用户代理(以下简称客户端)与邮件服务器(以下简称服务器端)的110端口建立TCP连接。
- 客户端向服务器端发出各种命令,来请求各种服务(如查询邮箱信息,下载某封邮件等)。
- 服务端解析用户的命令,做出相应动作并返回给客户端一个响应。
- 3和4交替进行,直到接收完所有邮件转到步骤6,或两者的连接被意外中断而直接退出。
- 用户代理解析从服务器端获得的邮件,以适当地形式(如可读)的形式呈现给用户。
其中2、3和4用POP3协议通信。可以看出命令和响应是POP3通信的重点
- 收取邮件过程
收取邮件的过程一般是:
- 连接pop3服务器(poplib.POP3.init)
- 发送用户名和密码进行验证(poplib.POP3.user poplib.POP3.pass_)
- 获取邮箱中信件信息(poplib.POP3.stat)
- 收取邮件(poplib.POP3.retr)
- 删除邮件(poplib.POP3.dele)
- 退出 (poplib.POP3.quit)
- 命令和响应
POP3的命令不多,它的一般形式是:COMMAND [Parameter] <CRLF>。其中COMMAND是ASCII形式的命令名,Parameter是相应的命令参数,<CRLF>是回车换行符(0xDH,0xAH)。
服务器响应是由一个单独的命令行组成,或多个命令行组成,响应第一行"+OK"或"-ERR"开头,然后再加上一些ASCII文本。"+OK"和"-ERR"分别指出相应的操作状态是成功的还是失败的。
POP3协议中有三种状态,认正状态,处理状态和更新状态。命令的执行可以改变协议的状态,而对于具体的某命令,它只能在具体的某状态下使用。客户机与服务器刚与服务器建立连接时,它的状态为认证状态;一旦客户机提供了自己身份并被成功地确认,即由认可状态转入处理状态;在完成相应的操作后客户机发出QUIT命令,则进入更新状态,更新之后又重返认可状态;当然在认可状态下执行QUIT命令,可释放连接。状态间的转移如图所示。

图1:POP状态转移图
- 常用命令和相应函数
| 命令 | poplib方法 | 参数 | 状态 | 描述 |
|---|---|---|---|---|
| USER | user | username | 认证 | 用户名,此命令与下面的pass命令若成功,将导致状态转换(明文) |
| PASS | pass_ |
password | 认证 | 用户密码,此命令若成功,状态转化为更新(授权码明文) |
| APOP | apop | Name,Digest | 认证 | Digest是MD5消息摘要 |
| STAT | stat | None | 处理 | 请求服务器发回关于邮箱的统计资料,如邮件总数和总字节数 |
| UIDL | uidl | [Msg#] | 处理 | 返回邮件的唯一标识符,POP3会话的每个标识符都将是唯一的 |
| LIST | list | [Msg#] | 处理 | 返回邮件数量和每个邮件的大小 |
| RETR | retr | [Msg#] | 处理 | 返回由参数标识的邮件的全部文本 |
| DELE | dele | [Msg#] | 处理 | 服务器将由参数标识的邮件标记为删除,由quit命令执行 |
| RSET | rset | None | 处理 | 服务器将重置所有标记为删除的邮件,用于撤消DELE命令 |
| TOP | top | [Msg#] | 处理 | 服务器将返回由参数标识的邮件的邮件头+前n行内容,n必须是正整数 |
| NOOP | noop | None | 处理 | 服务器返回一个肯定的响应 |
| QUIT | quit | None | 更新 | 1) 如果服务器处于“处理”状态,么将进入“更新”状态以删除任何标记为删除的邮件,并重返“认证”状态。 2) 如果服务器处于“认证”状态,则结束会话,退出连接 |
- shell样例
openssl s_client -crlf -connect mail.staff.sina.com.cn:995 # SSL连接(995端口)
telnet mail.staff.sina.com.cn 110 (非SSL加密)
- python代码
import poplib, getpass
popserver, user = 'mail.staff.sina.com.cn', 'jizhong1'
passwd = getpass.getpass("Email passwd for user %s: " % user)
server = poplib.POP3_SSL(popserver) # server = poplib.POP3(popserver)
print(server.user(user))
print(server.pass_(passwd))
try:
print(server.getwelcome())
msgCount, msgBytes = server.stat()
print('There are {} mail messages in {}MB.'.format(msgCount, msgBytes / 1024. / 1024.))
for i in range(1, 10):
hdr, messages, octes = server.retr(i)
print("Email {} has {} bytes.".format(hdr,octes))
finally:
server.quit()
4.2 MIME消息格式
MIME,英文全称为“MultipurposeInternetMailExtensions”,即多用途互联网邮件扩展,是目前互联网电子邮件普遍遵循的邮件技术规范。在MIME出现之前,互联网电子邮件主要遵循由RFC822所制定的标准,电子邮件一般只用来传递基本的ASCII码文本信息,MIME在RFC822的基础上对电子邮件规范做了大量的扩展,引入了新的格式规范和编码方式,在MIME的支持下,图像、声音、动画等二进制文件都可方便的通过电子邮件来进行传递,极大地丰富了电子邮件的功能,而且扩展了很多基于MIME的应用。目前互联网上使用的基本都是遵循MIME规范的电子邮件。从编码方式来说,MIME定义了两种编码方法Base64与QP(Quote-Printable)。
电子邮件的分析和读取一般都通过专用的邮件软件来实现,比如Outlook、Foxmail,但这种第三方软件无法和开发者自己的系统整合,通过对MIME邮件格式的分析,我们可以在自己的应用程序中实现对MIME邮件所含信息的读取。
总体来说,MIME消息由消息头和消息体两大部分组成。这里,分别称为邮件头、邮件体
4.2.1 MIME邮件头
邮件头包含了发件人、收件人、主题、时间、MIME版本、邮件内容的类型等重要信息。每条信息称为一个域,域的基本格式:{域名}:{内容},域由域名后面跟":"再加上域的信息内容构成,一条域在邮件中占一行或者多行,域的首行左侧不能有空白字符,比如空格或者制表符,占用多行的域其后续行则必须以空白字符开头。域的信息内容中还可以包含属性,属性之间以";"分隔,属性的格式如下:{属性名称}="{属性值}"。
一个消息头的例子:
Received: from SINA-HUB02 (10.210.97.52) by SINA-HUB02.staff.sina.com.cn
(10.210.97.52) with Microsoft SMTP Server id 14.3.123.3; Thu, 6 Jul 2017
00:00:54 +0800
From: <myhr@staff.sina.com.cn>
To: <jizhong1@staff.weibo.com>
Date: Thu, 6 Jul 2017 00:00:54 +0800
Subject: =?utf-8?B?5qyi6L+O5oKo5Yqg5YWl5b6u5Y2a77yM5Y+C5LiO5YWs5Y+45pyq5p2l55qE5Y+R5bGV77yB?=
Content-Type: text/html; charset="utf-8"
Content-Transfer-Encoding: base64
Message-ID: <dc9de56f-c7d8-439a-9cc7-8d75bb0f2996@SINA-HUB02.staff.sina.com.cn>
Return-Path: myhr@staff.sina.com.cn
X-MS-Exchange-Organization-AuthSource: SINA-HUB02.staff.sina.com.cn
X-MS-Exchange-Organization-AuthAs: Anonymous
MIME-Version: 1.0
常见的标准域名和含义如下:
| 域名 | 含义 | 添加者 |
|---|---|---|
| Received | 传输路径 | 各级邮件服务器 |
| Return-Path | 回复地址 | 目标邮件服务器 |
| Delivered-To | 发送地址 | 目标邮件服务器 |
| Reply-To | 回复地址 | 邮件的创建者 |
| From | 发件人地址 | 邮件的创建者 |
| To | 收件人地址 | 邮件的创建者 |
| Cc | 抄送地址 | 邮件的创建者 |
| Bcc | 暗送地址 | 邮件的创建者 |
| Date | 日期和时间 | 邮件的创建者 |
| Subject | 主题 | 邮件的创建者 |
| Message-ID | 消息ID | 邮件的创建者 |
| MIME-Version | MIME版本 | 邮件的创建者 |
| Content-Type | 内容的类型 | 邮件的创建者 |
| Content-Transfer-Encoding | 内容的传输编码方式 | 邮件的创建者 |
4.2.2 邮件体
- MIME段头信息
在段头中,大致有如下一些域:
| 域名 | 含义 |
|---|---|
| Content-Type | 段体的类型 |
| Content-Transfer-Encoding | 段体的传输编码方式 |
| Content-Disposition | 段体的安排方式 |
| Content-ID | 段体的ID |
| Content-Location | 段体的位置(路径) |
| Content-Base | 段体的基位置 |
有的域除了值之外,还带有参数。值与参数、参数与参数之间以“;”分隔。参数名与参数值之间以“=”分隔。
- multipart类型
multipart类型是MIME邮件的精髓。邮件体被分为多个段,每个段又包含段头和段体两部分,这两部分之间也以空行分隔。常见的multipart类型有三种:multipart/mixed, multipart/related和multipart/alternative。从它们的名称,不难推知这些类型各自的含义和用处。它们之间的层次关系可归纳为下图所示:
+------------------------- multipart/mixed -----------------------------+
| |
| +----------------- multipart/related -------------------+ |
| | | |
| | +----- multipart/alternative ------+ +----------+ | +------+ |
| | | | | 内嵌资源 | | | 附件 | |
| | | +------------+ +------------+ | +----------+ | +------+ |
| | | | 纯文本正文 | | 超文本正文 | | | |
| | | +------------+ +------------+ | +----------+ | +------+ |
| | | | | 内嵌资源 | | | 附件 | |
| | +----------------------------------+ +----------+ | +------+ |
| | | |
| +-------------------------------------------------------+ |
| |
+-----------------------------------------------------------------------+
可以看出,如果要在邮件中要添加附件就必须将整封邮件的MIME类型定义为multipart/mixed;如果要在HTML格式的正文中引用内嵌资源,那就要定义multipart/related类型的MIME消息;如果普通文本内容与HTML文本内容共存,那就要定义multipart/alternative类型的MIME消息。
注意:如果整封邮件中只有普通文本内容与HTML文本内容,那么整封邮件的MIME类型则应定义为multipart/alternative;如果整封邮件中包含有HTML文本内容和内嵌资源,但不包含附件,那么整封邮件的MIME类型则应定义为multipart/related。
- content-type域
对于表示某个具体资源的MIME消息,它的消息头中需要指定资源的数据类型,用于定义用户的浏览器或相关设备如何显示将要加载的数据,或者如何处理将要加载的数据,此属性的值可以查看MIME类型;对于MIME组合消息,它的消息头中需要指定组合关系。具体资源的数据类型和组合消息的组合关系,都是通过消息头中的Content-Type头字段来指定的。
content-type一般以下面的形式出现:Content-Type:[type]/[subtype]; parameter。Content-Type字段中的内容以“主类型/子类型”的形式出现,主类型有text、image、audio、video、application、multipart、message等,分别表示文本、图片、音频、视频、应用程序、组合结构、消息等。每个主类型下面都有多个子类型,例如text主类型包含plain、html、xml、css等子类型。multipart主类型用于表示MIME组合消息,它是MIME协议中最重要的一种类型。一封MIME邮件中的MIME消息可以有三种组合关系:混合、关联、选择,它们对应MIME类型如下:
multipart/mixed:表示消息体中的内容是混和组合类型,内容可以是文本、声音和附件等不同邮件内容的混和体。multipart/related:表示消息体中的内容是关联(依赖)组合类型,邮件正文要使用HTML代码引用内嵌的图片资源,它们组合成的MIME消息的MIME类型就应该定义为multipart/related,表示其中某些资源(HTML代码)要引用(依赖)另外的资源(图像数据),引用资源与被引用的资源必须组合成multipart/related类型的MIME组合消息。multipart/alternative:表示消息体中的内容是选择组合类型,例如一封邮件的邮件正文同时采用HTML格式和普通文本格式进行表达时,就可以将它们嵌套在一个 multipart/alternative类型的MIME组合消息中。这种做法的好处在于如果邮件阅读程序不支持HTML格式时,可以采用其中的文本格式进行替代。
type 有下面的形式:
Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的;Multipart:用于连接消息体的多个部分构成一个消息,这些部分可以是不同类型的数据;Application:用于传输应用程序数据或者二进制数据;Message:用于包装一个E-mail消息;Image:用于传输静态图片数据;Audio:用于传输音频或者音声数据;Video:用于传输动态影像数据,可以是与音频编辑在一起的视频数据格式。
subtype用于指定type的详细形式。"type/subtype"配对的集合和与此相关的参数。下面是最经常用到的一些MIME类型:
text/html(HTML 文档);
text/plain(纯文本);
text/css(CSS 样式表);
image/gif(GIF 图像);
image/jpeg(JPG 图像);
application/x-javascript(JavaScript 脚本);
application/x-shockwave-flash(Flash);
application/x- www-form-urlencoded(使用 HTTP 的 POST 方法提交的表单);
multipart/form-data(同上,但主要用于表单提交时伴随文件上传的场合)。
更详细的内容请查看:HTTP Content-type
一封最复杂的电子邮件的基本情况为:含有邮件正文和邮件附件,邮件正文可以同时使用HTML格式和普通文本格式表示,并且HTML格式的正文中又引用了其他的内嵌资源。对于这种最复杂的电子邮件,可以采用如图所示的MIME消息结构进行描述。
在Content-type头字段中除了可以定义消息体的MIME类型外,还可以在MIME类型后面包含相应的属性,属性以“属性名=属性值”的形式出现,属性与MIME类型之间采用分号(;)分隔,如下所示:
Content-Type:multipart/mixed;boundary="----=_NextPart_000_0050_01C"
常用的属性如表所示:
| 主类型 | 属性名 | 说明 |
|---|---|---|
| text | charset | 用于说明文本内容的字符集编码 |
| image | name | 用于说明图片文件的文件名 |
| application | name | 用于说明应用程序的文件名 |
| multipart | boundary | 用于定义MIME消息之间的分隔符 |
- Content-Transfer-Encoding字段
Content-Transfer-Encoding头字段用于指定MIME消息体中的内容所采用的邮件编码方式.
- Content-Disposition字段
Content-Disposition头字段用于指定邮件阅读程序处理数据内容的方式,有inline和attachment两种标准方式,inline表示直接处理,而attachment表示当做附件处理。如果将Content-Disposition设置为attachment,在其后还可以指定filename 属性,如下所示:
Content-Disposition: attachment; filename="1.bmp"
上面的MIME头字段表示MIME消息体的内容为邮件附件,附件名"1.bmp"。
- Content-ID字段
Content-ID头字段用于为"multipart/related"组合消息中的内嵌资源指定一个唯一标识号,在HTML格式的正文中可以使用这个唯一标识号来引用该内嵌资源。例如,假设将一个表示内嵌图片的MIME消息的Content-ID头字段设置为如下形式:Content-ID:it315logo_gif。
那么,在HTML正文中就需要使用如下HTML语句来引用该图片资源:<img src="cid:it315logo_gif">
注意,在引用Content-ID头字段标识的内嵌资源时,要在资源的唯一标识号前面加上“cid:”,以说明要采用唯一标识号对资源进行引用。
- Content-Location
Content-Location头字段用于为内嵌资源设置一个URI地址,这个URI地址可以是绝对或相对的。当使用Content-Location头字段为一个内嵌资源指定一个URI地址后,在HTML格式的正文中也可以使用这个URI来引用该内嵌资源。例如,假设将一个表示内嵌图片的MIME消息的Content-Location头字段设置为如下形式:Content-Location:http://www.it315.org/images/it315logo.gif
那么,在HTML正文中就可以使用如下HTML语句来引用该图片资源:<img src="http://www.it315.org/images/it315logo.gif">
- Content-Base
Content-Base头字段用于为内嵌资源设置一个基准路径,只有这样,Content-Location头字段中设置的URI才可以采用相对地址。例如,假设将一个表示内嵌图片的MIME消息的Content-Base和Content-Location头字段设置为如下形式:
Content-Base: http://www.it315.org/images/
Content-Location: it315logo.gif
那么,内嵌资源的完整路径就是Content-Base头字段设置的基准路径与Content-Location头字段设置的相对路径相加的结果,在HTML正文中就可以使用如下HTML语句来引用该图片资源:<img src="http://www.it315.org/images/it315logo.gif">
4.2.3 python代码
import os, sys
import poplib, email, getpass
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
# 邮件的Subject或者Email中包含的名字都是经过编码后的str,要正常显示,就必须decode
def decode_str(s):
value, charset = decode_header(s)[0]
if charset:
try:
value = value.decode(charset)
except:
pass
if type(value) == unicode:
value = value.encode("utf8")
return value
# 解析邮件内容
def parse_mail(msg_content, UIDL="0001"):
temp_download_path = os.path.join(DOWNLOAD_PATH,UIDL)
if not os.path.exists(temp_download_path):os.mkdir(temp_download_path)
msg = Parser().parsestr(b"\r\n".join(msg_content))
# 获取header 相关的信息
headers = msg.items()
for header in headers:
item, content = header
if item == "Subject" or item == "Thread-Index" or item == "Thread-Topic":
value = decode_str(content)
print("{} : {}\n".format(item, value))
elif item == "From" or item == "To" or item == "CC":
value = []
item_addr_list = content.split(",")
for item_addr in item_addr_list:
hdr, addr =parseaddr(item_addr)
name = decode_str(hdr)
value.append("{}<{}>".format(name, addr))
print("{} : {}\n".format(item, ",".join(value)))
else:
print("{} : {}\n".format(item, decode_str(content).replace("\r\n","")))
# 获取邮件内容
ct = 1
for par in msg.walk():
name = par.get_filename()
if name: # 是否为附件
name = decode_str(name)
data = par.get_payload(decode=True)
try:
# 注意一定要用wb来打开文件,因为附件一般都是二进制文件
with open(os.path.join(temp_download_path, name) , "w") as fp:
fp.write(data)
except Exception as e:
print('ERROR: {}'.format(str(e)))
else:
# 不是附件,是文本内容
body = par.get_payload(decode=True) # 解码出文本内容,直接输出来就可以了。
content_file = os.path.join(temp_download_path, "content_{}.txt".format(ct))
with open(content_file, "wb") as fp:
if body is not None:
fp.write(decode_str(body))
ct += 1
def get_mails(popserver, username, password):
try:
server = poplib.POP3_SSL(popserver)
server.user(username)
server.pass_(password)
print("{}".format(server.getwelcome().replace("+OK", "")))
# 获取邮件数量以及大小
msgCount, msgBytes = server.stat()
print('Get {} mails costing storage {} Mb.'.format(msgCount, msgBytes / 1024. / 1024.))
# 获取前十封邮件
for i in range(1, msgCount+1):
# 获取邮件的标识符和邮件大小
status, index, UIDL = server.uidl(i).split(" ")
status, index, SIZE = server.list(i).split(" ")
# 获取邮件的内容(状态, 内容, 大小)
hdr, messages, octes = server.retr(i)
print("Mail index({}):uidl ({}) and size ({})".format(i, UIDL, SIZE))
parse_mail(messages, str(UIDL))
finally:
server.quit()
if __name__ == "__main__":
popserver, user = 'mail.staff.sina.com.cn', 'jizhong1'
passwd = getpass.getpass("Email passwd for user %s: " % user)
get_mails(popserver, user, passwd)
官方的MIME信息是由Internet Engineering Task Force (IETF)在下面的文档中提供的:
- RFC-822 Standard for ARPA Internet text messages
- RFC-2045 MIME Part 1: Format of Internet Message Bodies
- RFC-2046 MIME Part 2: Media Types
- RFC-2047 MIME Part 3: Header Extensions for Non-ASCII Text
- RFC-2048 MIME Part 4: Registration Procedures
- RFC-2049 MIME Part 5: Conformance Criteria and Examples
4.3 SMTP格式
SMTP(Simple Mail Transfer Protocol,简单邮件传输协议)即简单邮件传输协议,它是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。它定义了邮件客户端与SMTP服务器之间,以及两台SMTP服务器之间发送邮件的通信规则。SMTP协议属于TCP/IP协议族,通信双方采用一问一答的命令/响应形式进行对话,且定了对话的规则和所有命令/响应的语法格式。
4.3.1 用户代理
用户代理UA(User Agent)是用户与电子邮件系统的交互接口,一般来说它就是我们PC机上的一个程序。Windows上常见的用户代理是Foxmail和Outlook Express。
用户代理提供一个好的用户界面,它提取用户在其界面填写的各项信息,生成一封符合SMTP等邮件标准的邮件,然后采用SMTP协议将邮件发送到发送端邮件服务器。
4.3.2 邮件服务器
邮件服务器是电子邮件系统的核心,它用来发送和接收邮件。邮件服务器不同于普通PC的是它几乎是全天工作的,所以它可以在任何时候为用户提供服务,很多ISP都提供免费的邮件服务器,如126提供smtp.126.com邮件服务器。邮件服务器向其它邮件服务器转发邮件也是采用SMTP协议。
一般情况下,一封邮件的发送和接收过程如下:
- 发信人在用户代理里编辑邮件,包括填写发信人邮箱、收信人邮箱和邮件标题等等。
- 用户代理提取发信人编辑的信息,生成一封符合邮件格式标准(RFC822)的邮件。
- 用户代理用SMTP将邮件发送到发送端邮件服务器(即发信人邮箱所对应的邮件服务器)。
- 发送端邮件服务器用SMTP将邮件发送到接收端邮件服务器(即收信人邮箱所对应的邮件服务器)。
- 用户代理解析收到的邮件,以适当的形式呈现在收信人面前。
一个具体的SMTP通信(如发送端邮件服务器与接收端服务器的通信)的过程如下:
- 发送端邮件服务器(以下简称客户端)与接收端邮件服务器(以下简称服务器)的25号端口建立TCP连接。
- 客户端向服务器发送各种命令,来请求各种服务(如认证、指定发送人和接收人)。
- 服务器解析用户的命令,做出相应动作并返回给客户端一个响应。
- 2和3交替进行,直到所有邮件都发送完或两者的 连接被意外中断。
SMTP连接和发送的过程
- 建立TCP连接
- 客户端发送HELO命令以标识发件人自己的身份,然后客户端发送MAIL命令;
- 客户端发送RCPT命令,以标识该电子邮件的计划接收人,可以有多个RCPT行;
- 协商结束,发送邮件,用命令DATA发送
- 以.表示结束输入内容一起发送出去
- 结束此次发送,用QUIT命令退出
4.3.3 SMTP常见命令和响应
- SMTP常见的命令
| 命令 | 说明 |
|---|---|
EHLO <domain> |
ehlo命令是SMTP邮件发送程序与SMTP邮件接收程序建立连接后必须发送的第一条SMTP命令,参数<domain>表示SMTP邮件发送者的主机名。ehlo命令用于替代传统SMTP协议中的helo命令。使服务器可以表明自己支持扩展简单邮件传输协议(ESMTP)命令 |
HELO <domain> |
客户端为标识自己的身份而发送的命令 |
AUTH <para> |
如果SMTP邮件接收程序需要SMTP邮件发送程序进行认证时,它会向SMTP邮件发送程序提示它所采用的认证方式,SMTP邮件发送程序接着应该使用这个命令回应SMTP邮件接收程序,参数<para>表示回应的认证方式,通常是SMTP邮件接收程序先前提示的认证方式。[PLAIN/LOGIN/]。其中数据都是base64加密的。 |
MAIL FROM <reverse-path> |
此命令用于指定邮件发送者的邮箱地址,参数<reverse-path>表示发件人的邮箱地址。[可以不是自己的邮箱地址,可以伪装] |
RCPT TO <forward-path> |
此命令用于指定邮件接收者的邮箱地址,参数<forward-path>表示接收者的邮箱地址。如果邮件要发送给多个接收者,那么应使用多条rcpt to命令来分别指定每一个接收者的邮箱地址。 |
DATA |
此命令用于表示SMTP邮件发送程序准备开始传送邮件内容,在这个命令后面发送的所有数据都将被当作邮件内容,直至遇到“<CRLF>.<CRLF>”标识符,则表示邮件内容结束。 |
REST |
重置会话,当前传输被取消 |
NOOP |
要求服务器返回OK应答,一般用作测试 |
VRFY <string> |
验证指定的邮箱是否存在,由于安全方面的原因,服务器大多禁止此命令 |
EXPN <string> |
验证给定的邮箱列表是否存在,由于安全方面的原因,服务器大多禁止此命令 |
HELP |
返回SMTP服务所支持的命令列表。 |
QUIT |
此命令表示要结束邮件发送过程,SMTP邮件接收程序接收到此命令后,将关闭与SMTP邮件发送程序的网络连接。 |
- SMTP常用的响应
| 响应码 | 说明 |
|---|---|
220<domain> |
服务器就绪 |
211<domain> |
系统状态或系统帮助响应 |
214<domain> |
帮助信息 |
| 221 | 服务关闭 |
| 250 | 要求的邮件操作完成 |
| 251 | 用户非本地,将转发向<forward-path> |
| 354 | 开始邮件输入,以“.”结束 |
| 421 | 服务器未就绪,关闭传输信道 |
| 450 | 要求的邮件操作未完成,邮箱不可用 |
| 451 | 放弃要求的操作,处理过程中出错 |
| 452 | 系统存储不足,要求的操作未执行 |
| 501 | 参数格式错误 |
| 502 | 命令不可实现 |
| 503 | 错误的命令序列 |
| 504 | 命令参数不可实现 |
| 550 | 要求的邮件操作未完成,邮箱不可用 |
| 551 | 用户非本地,请尝试<forward-path> |
| 552 | 过量的存储分配,要求的操作未执行 |
| 553 | 邮箱名不可用,要求的操作未执行 |
| 554 | 操作失败 |
4.3.4 python发送邮件
在Python程序中,经常使用SMTP来发送邮件。支持的库有:smtplib和email, smtplib负责发送邮件,email负责构造邮件。
- 简单的例子
# 首先构造邮件:
from email.mime.text import MIMEText
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')
msg["from"] = "hello@sina.cn" # 邮件的发件人
# 使用smtplib发送邮件
import smtplib
# smtpObject = smtplib.SMTP(host, port)
# smtpObject = smtplib.SMTP_SSL(host, port) # 有的服务器禁用25端口,此时用加密的SMTP
smtpObject = smtplib.SMTP("smtp.sina.cn", port=25) # 连接smtp服务器, port 是端口号,一般是25, SSL为465
# smtp.login(user, password) # 登陆账号: user 为账号, password为账号对应的密码
smtpObject.login("hello", "hello")
# smtpObject.sendmail(sender, receivers_list, msg)
smtpObject.sendmail("hello@sina.cn",["jzwang@whu.edu.cn",], msg.as_string())
smtpObject.quit()
- 邮件的头部信息
从发送的邮件可以看到:主题没有和收件人没有显示。这是因为邮件主题、如何显示发件人、收件人等信息并不是通过SMTP协议发给MTA(Mail Transport Agent),而是包含在发给MTA的文本中的,所以,必须把From、To和Subject添加到·MIMEText·中,才是一封完整的邮件:
from email.header import Header
from email.mime.text import MIMEText
from email.utils import parseaddr, formataddr
def _format_addr(s):
name, addr = parseaddr(s)
return formataddr(( \
Header(name, 'utf-8').encode(), \
addr.encode('utf-8') if isinstance(addr, unicode) else addr))
msg = MIMEText('hello, send by Python...', 'plain', 'utf-8')
msg['From'] = "18515546516@sina.cn"
# msg['To'] = _format_addr(u'纪中 <jizhong1@staff.weibo.com>') + ",jzwang@whu.edu.cn"
msg["to"]="jzwang@whu.edu.cn,jizhong1@staff.weibo.com"
msg['Subject'] = Header(u'来自SMTP的问候……', 'utf-8').encode()
我们编写了一个函数_format_addr()来格式化一个邮件地址。注意不能简单地传入name \<addr@example.com>,因为如果包含中文,需要通过Header对象进行编码。msg['To']接收的是字符串而不是list,如果有多个邮件地址,用,分隔即可。
有时候在发送邮件时候,我们希望某几个人是收的,其他有些人只是知道有这种情况而已,这时需要邮件的抄送功能,这也是在邮件头部信息中体现的:
cc = ['bb@bbb.com', 'cc@ccc.com']
message['Cc'] = Header(','.join(cc), 'utf-8') # 抄送
message['Bcc'] = Header(','.join(cc), 'utf-8') # 密送
- 带有附件
带附件的邮件可以看做包含若干部分的邮件:文本和各个附件本身,所以,可以构造一个MIMEMultipart对象代表邮件本身,然后往里面加上一个MIMEText作为邮件正文,再继续往里面加上表示附件的MIMEBase对象即可:
msg = email.mime.multipart.MIMEMultipart()
msg['from'] = sendAddr
msg['to'] = recipientAddrs
msg['subject'] = subject
msg.attach(email.mime.text.MIMEText(content, 'plain', 'utf-8'))
# 添加附件,添加rar文件
part = MIMEApplication(open('./test.rar','rb').read())
part.add_header('Content-Disposition', 'attachment', filename="test.rar")
part.add_header('Content-ID', '<0>') # 定义内容ID
part.add_header('X-Attachment-Id', '0')
msg.attach(part)
smtp.sendmail(sendAddr, recipientAddrs, msg.to_string())
smtp.quit()
在python中,MIME的这些对象的继承关系如下。
MIMEBase
|-- MIMENonMultipart
|-- MIMEApplication
|-- MIMEAudio
|-- MIMEImage
|-- MIMEMessage
|-- MIMEText
|-- MIMEMultipart
一般来说,不会用到MIMEBase,而是直接使用它的继承类。MIMEMultipart有attach方法,而MIMENonMultipart没有,只能被attach。MIME有很多种类型,这个略麻烦,如果附件是图片格式,我要用MIMEImage,如果是音频,要用MIMEAudio,如果是word、excel,我都不知道该用哪种MIME类型了,得上google去查。最懒的方法就是,不管什么类型的附件,都用MIMEApplication,MIMEApplication默认子类型是application/octet-stream。application/octet-stream表明“这是个二进制的文件,希望你们那边知道怎么处理”,然后客户端,比如qq邮箱,收到这个声明后,会根据文件扩展名来猜测。
- 显示图片的HTML邮件
如果我们要发送HTML邮件,而不是普通的纯文本文件怎么办?方法很简单,在构造MIMEText对象时,把HTML字符串传进去,再把第二个参数由plain变为html就可以了:
msg = MIMEText('<html><body><h1>Hello</h1>' +
'<p>send by <a href="http://www.python.org">Python</a>...</p>' +
'</body></html>', 'html', 'utf-8')
如果要把一个图片嵌入到邮件正文中怎么做?直接在HTML邮件中链接图片地址行不行?答案不行,大部分邮件服务商都会自动屏蔽带有外链的图片,因为不知道这些链接是否指向恶意网站。
要把图片嵌入到邮件正文中,我们只需按照发送附件的方式,先把邮件作为附件添加进去,然后,在HTML中通过引用src="cid:0"就可以把附件作为图片嵌入了。如果有多个图片,给它们依次编号,然后引用不同的cid:x即可。
把上面代码加入MIMEMultipart的MIMEText从plain改为html,然后在适当的位置引用图片:
msg.attach(MIMEText('<html><body><h1>Hello</h1>' +
'<p><img src="cid:0"></p>' +
'</body></html>', 'html', 'utf-8'))
如果我们发送HTML邮件,收件人通过浏览器或者Outlook之类的软件是可以正常浏览邮件内容的,但是,如果收件人使用的设备太古老,查看不了HTML邮件怎么办?办法是在发送HTML的同时再附加一个纯文本,如果收件人无法查看HTML格式的邮件,就可以自动降级查看纯文本邮件。
利用MIMEMultipart就可以组合一个HTML和Plain,要注意指定subtype是alternative:
msg = MIMEMultipart('alternative')
msg['From'] = ...
msg['To'] = ...
msg['Subject'] = ...
msg.attach(MIMEText('hello', 'plain', 'utf-8'))
msg.attach(MIMEText('<html><body><h1>Hello</h1></body></html>', 'html', 'utf-8'))
# 正常发送msg对象...
- 加密SMTP
使用标准的25端口连接SMTP服务器时,使用的是明文传输,发送邮件的整个过程可能会被窃听。要更安全地发送邮件,可以加密SMTP会话,实际上就是先创建SSL安全连接,然后再使用SMTP协议发送邮件。
某些邮件服务商,例如Gmail,提供的SMTP服务必须要加密传输。我们来看看如何通过Gmail提供的安全SMTP发送邮件。
必须知道,Gmail的SMTP端口是587,因此,修改代码如下:
smtp_server = 'smtp.gmail.com'
smtp_port = 587
server = smtplib.SMTP(smtp_server, smtp_port)
server.starttls()
# 剩下的代码和前面的一模一样:
server.set_debuglevel(1)
...
或者使用smtplib.SMTP构造,只需要在创建SMTP对象后,立刻调用starttls()方法,就创建了安全连接。后面的代码和前面的发送邮件代码完全一样。
- python例子
from email.message import Message
from email.mime.audio import MIMEAudio
from email.mime.base import MIMEBase
from email.mime.image import MIMEImage
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
from email.utils import formataddr
from email import encoders
import os, mimetypes
attach_dir = "./"
outer = MIMEMultipart()
outer['Subject'] = 'Contents of directory %s'%os.path.abspath(attach_dir)
outer['To'] = formataddr(["纪中","jizhong1@staff.weibo.com"]) + ";" + "1792403713@qq.com"
outer['From'] = formataddr(["纪中","jizhong1@staff.weibo.com"])
outer["Cc"]=formataddr(["纪中","jizhong1@staff.weibo.com"])
outer.preamble = 'You will not see this in a MIME-aware mail reader.\n'
for filename in os.listdir(attach_dir):
path = os.path.join(attach_dir, filename)
if not os.path.isfile(path):continue
ctype, encoding = mimetypes.guess_type(path)
if ctype is None or encoding is not None:
ctype = 'application/octet-stream'
maintype, subtype = ctype.split('/', 1)
if maintype == 'text':
with open(path) as fp:
msg = MIMEText(fp.read(), _subtype=subtype)
elif maintype == 'image':
with open(path, 'rb') as fp:
msg = MIMEImage(fp.read(), _subtype=subtype)
elif maintype == 'audio':
with open(path, 'rb') as fp:
msg = MIMEAudio(fp.read(), _subtype=subtype)
else:
with open(path, 'rb') as fp:
msg = MIMEBase(maintype, subtype)
msg.set_payload(fp.read())
encoders.encode_base64(msg)
msg.add_header('Content-Disposition', 'attachment', filename=filename)
outer.attach(msg)
composed = outer.as_string()
五、linux目录结构
树状目录结构:

以下是对这些目录的解释:
| 目录 | 说明 |
|---|---|
/bin |
bin是Binary的缩写,这个目录包含了引导启动所需的命令或普通用户可能用的命令(可能在引导启动后),这些命令都是二进制文件的可执行程序,多是系统中重要的系统文件 |
/boot |
/boot目录存放引导加载器(bootstrap loader)使用的文件,如lilo,核心映像也经常放在这里,而不是放在根目录中。但是如果有许多核心映像,这个目录就可能变得很大,这时使用单独的 文件系统会更好一些。还有一点要注意的是,要确保核心映像必须在ide硬盘的前1024柱面内 |
/dev |
dev是Device(设备)的缩写,/dev目录存放了设备文件,即设备驱动程序,用户通过这些文件访问外部设备。比如用户可以通过访问/dev/mouse来访问鼠标的输入,就像访问其他文件一样1. /dev/console:系统控制台,也就是直接和系统连接的监视器2. /dev/hd:ide硬盘驱动程序接口,如:/dev/hda指的是第一个硬盘,had1则是指/dev/hda的第一个分区,如系统中有其他的硬盘,则依次为/dev/hdb、/dev/hdc、...,如有多个分区则依次为hda1、hda2...3. /dev/sd:scsi磁盘驱动程序接口,如系统有scsi硬盘,就不会访问/dev/had,而会访问/dev/sda4. /dev/fd:软驱设备驱动程序,如/dev/fd0指系统的第一个软盘,也就是通常所说的a盘,/dev/fd1指第二个软盘...,而/dev/fd1 h1440则表示访问驱动器1中的4.5高密盘5. /dev/st:scsi磁带驱动器驱动程序6. /dev/tty:提供虚拟控制台支持,如:/dev/tty1指的是系统的第一个虚拟控制台,/dev/tty2则是系统的第二个虚拟控制台7. /dev/pty:提供远程登陆伪终端支持,在进行telnet登录时就要用到/dev/pty设备8. /dev/ttys:计算机串行接口,对于dos来说就是“com1”口9. /dev/cua:计算机串行接口,与调制解调器一起使用的设备10. /dev/null:“黑洞”,所有写入该设备的信息都将消失。例如:当想要将屏幕上的输出信息隐藏起来时,只要将输出信息输入到/dev/null中即可 |
/etc |
这个目录用来存放所有的系统管理所需要的配置文件和子目录。 |
/home |
用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。 |
/lib |
/lib目录是根文件系统上的程序所需的共享库,存放了根文件系统程序运行所需的共享文件。这些文件包含了可被许多程序共享的代码,以避免每个程序都包含有相同的子程序的副本,故可以使得可执行文件变得更小,节省空间./lib/modules目录包含系统核心可加载各种模块,尤其是那些在恢复损坏的系统时重新引导系统所需的模块(例如网络和文件系统驱动) |
/lost+found |
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。 |
/media |
linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。 |
| `/mnt | 系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。 |
/opt |
这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。 |
/proc |
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。 这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的 ping命令,使别人无法ping你的机器:echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all |
/root |
该目录为系统管理员,也称作超级权限者的用户主目录。 |
/sbin |
s就是Super User的意思,目录用于存储二进制文件,放的是系统管理员使用的系统管理程序。因为其中的大部分文件多是系统管理员使用的基本的系统程序,所以虽然普通用户必要且允许时可以使用,但一般不给普通用户使用 |
/selinux |
这个目录是Redhat/CentOS所特有的目录,Selinux是一个安全机制,类似于windows的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。 |
/srv |
该目录存放一些服务启动之后需要提取的数据。 |
/sys |
这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统sysfs。 sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。该文件系统是内核设备树的一个直观反映。当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。 |
/tmp |
/tmp目录存放程序在运行时产生的信息和数据,但在引导启动后,运行的程序最好使用/var/tmp来代替/tmp,因为前者可能拥有一个更大的磁盘空间 |
/usr |
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与windows下的program files目录。 |
/usr/bin |
系统用户使用的应用程序。 |
/usr/sbin |
超级用户使用的比较高级的管理程序和系统守护程序。 |
/usr/src |
内核源代码默认的放置目录。 |
/var |
这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。 在linux系统中,有几个目录是比较重要的,平时需要注意不要误删除或者随意更改内部文件。 |
/etc |
/etc目录存放着各种系统配置文件,其中包括了用户信息文件/etc/passwd,系统初始化文件/etc/rc等。linux正是靠这些文件才得以正常地运行1. /etc/rc或/etc/rc.d或/etc/rc?.d:启动或改变运行级时运行的脚本或脚本的目录2. /etc/passwd:用户数据库,其中的域给出了用户名、真实姓名、用户起始目录、加密口令和用户的其他信息3. /etc/fdprm:软盘参数表,用以说明不同的软盘格式,可用setfdprm进行设置4. /etc/fstab:指定启动时需要自动安装的文件系统列表,也包括用swapon -a启用的swap区的信息5. /etc/group:类似/etc/passwd,但说明的不是用户信息而是组的信息,包括组的各种数据6. /etc/inittab:init的配置文件7. /etc/issue:包括用户在登录提示符前的输出信息,通常包括系统的一段短说明或欢迎信息,具体内容由系统管理员确定8. /etc/magic:“file”的配置文件,包含不同文件格式的说明,“file”基于它猜测文件类型9. /etc/motd:motd是message of the day的缩写,用户成功登录后自动输出。内容由系统管理员确定,常用于通告信息,如计划关机时间的警告等10. /etc/mtab:当前安装的文件系统列表。由脚本(scritp)初始化,并由mount命令自动更新。当需要一个当前安装的文件系统的列表时使用(例如df命令)11. /etc/shadow:在安装了影子(shadow)口令软件的系统上的影子口令文件。影子口令文件将/etc/passwd文件中的加密口令移动到/etc/shadow中,而后者只对超级用户(root)可读。这使破译口令更困难,以此增加系统的安全性12. /etc/login.defs:login命令的配置文件13. /etc/printcap:类似/etc/termcap,但针对打印机。语法不同14. /etc/profile、/etc/csh.login、/etc/csh.cshrc:登录或启动时bourne或cshells执行的文件。这允许系统管理员为所有用户建立全局缺省环境15. /etc/securetty:确认安全终端,即哪个终端允许超级用户(root)登录。一般只列出虚拟控制台,这样就不可能(至少很困难)通过调制解调器(modem)或网络闯入系统并得到超级用户特权16. /etc/shells:列出可以使用的shell。chsh命令允许用户在本文件指定范围内改变登录的shell。提供一台机器ftp服务的服务进程ftpd检查用户shell是否列在/etc/shells文件中,如果不是,将不允许该用户登录17. /etc/termcap:终端性能数据库。说明不同的终端用什么“转义序列”控制。写程序时不直接输出转义序列(这样只能工作于特定品牌的终端),而是从/etc/termcap中查找要做的工作的正确序列。这样,多数的程序可以在多数终端上运行 |
/bin,/sbin,/usr/bin,/usr/sbin:这是系统预设的执行文件的放置目录,比如ls就是在/bin/ls目录下的。值得提出的是,/bin,/usr/bin是给系统用户使用的指令(除root外的通用户),而/sbin,/usr/sbin则是给root使用的指令。
/var是一个非常重要的目录,系统上跑了很多程序,那么每个程序都会有相应的日志产生,而这些日志就被记录到这个目录下,具体在/var/log目录下,另外mail的预设放置也是在这里。
5.1 /proc目录介绍
proc是Linux系统下一个很重要的目录。它跟/etc,/home等这些系统目录不同,它不是一个真正的文件系统,而是一个虚拟的文件系统。它不存在于磁盘,而是存在于系统内存中。所以当你使用ls -al /proc这条命令来查看proc目录时,会看到其下面的所有文件的大小都为0字节。proc以文件系统的方式为访问系统内核的操作提供接口。很多系统的信息,如内存使用情况,cpu使用情况,进程信息等等这些信息,都可以通过查看/proc下的对应文件来获得。proc文件系统是动态从系统内核读出所需信息的。
- 目录下含有的文件/目录
| 目录 | 说明 |
|---|---|
/proc/cpuinifo |
CPU的信息(型号、家族、缓存大小等) |
/proc/meminfo |
物理内存、交换空间相关信息 |
/proc/cmdline |
系统启动时输入的内核命令行参数 |
/proc/buddyinfo |
每个内存区中的每个order有多少块可用,和内存碎片问题有关 |
/proc/crypto |
内核使用的所有已安装的加密密码及细节 |
/proc/devices |
已经加载的设备并分类 |
/proc/dma |
已注册使用的ISA DMA频道列表 |
/proc/execdomains |
Linux内核当前支持的execution domains |
/proc/fb |
帧缓冲设备列表,包括数量和控制它的驱动 |
/proc/filesystems |
内核当前支持的文件系统类型 |
/proc/interrupts |
x86架构中的每个IRQ中断数 |
/proc/iomem |
每个物理设备当前在系统内存中的映射 |
/proc/ioports |
一个设备的输入输出所使用的注册端口范围 |
/proc/kcore |
代表系统的物理内存,存储为核心文件格式,里边显示的是字节数,等于RAM大小加上4kb |
/proc/kmsg |
记录内核生成的信息,可以通过/sbin/klogd或/bin/dmesg来处理 |
/proc/loadavg |
根据过去一段时间内CPU和IO的状态得出的负载状态,与uptime命令有关 |
/proc/locks |
内核锁住的文件列表 |
/proc/mdstat |
多硬盘,RAID配置信息(md=multiple disks) |
/proc/misc |
其他的主要设备(设备号为10)上注册的驱动 |
/proc/modules |
所有加载到内核的模块列表 |
/proc/mounts |
系统中使用的所有挂载 |
/proc/mtrr |
系统使用的Memory Type Range Registers(MTRRs) |
/proc/partitions |
分区中的块分配信息 |
/proc/pci |
系统中的PCI设备列表 |
/proc/slabinfo |
系统中所有活动的slab缓存信息 |
/proc/stat |
所有的CPU活动信息 |
/proc/sysrq-trigger |
使用echo命令来写这个文件的时候,远程root用户可以执行大多数的系统请求关键命令,就好像在本地终端执行一样。要写入这个文件,需要把/proc/sys/kernel/sysrq不能设置为0。这个文件对root也是不可读的 |
/proc/uptime |
系统已经运行了多久 |
/proc/swaps |
交换空间的使用情况 |
/proc/version |
Linux内核版本和gcc版本 |
/proc/bus |
系统总线(Bus)信息,例如pci/usb等 |
/proc/driver |
驱动信息 |
/proc/fs |
文件系统信息 |
/proc/ide |
ide设备信息 |
/proc/irq |
中断请求设备信息 |
/proc/net |
网卡设备信息 |
/proc/scsi |
scsi设备信息 |
/proc/tty |
tty设备信息 |
/proc/vmstat |
虚拟内存统计信息 |
/proc/vmcore |
内核panic时的内存映像 |
/proc/diskstats |
取得磁盘信息 |
/proc/schedstat |
kernel调度器的统计信息 |
/proc/zoneinfo |
显示内存s空间的统计信息,对分析虚拟内存行为很有用 |
5.2 进程N的信息
| 目录 | 说明 |
|---|---|
/proc/N |
pid为N的进程信息 |
/proc/N/cmdline |
进程启动命令 |
/proc/N/cwd |
链接到进程当前工作目录 |
/proc/N/environ |
进程环境变量列表 |
/proc/N/exe |
链接到进程的执行命令文件 |
/proc/N/fd |
包含进程相关的所有的文件描述符 |
/proc/N/maps |
与进程相关的内存映射信息 |
/proc/N/mem |
指代进程持有的内存,不可读 |
/proc/N/root |
链接到进程的根目录 |
/proc/N/stat |
进程的状态 |
/proc/N/statm |
进程使用的内存的状态 |
/proc/N/status |
进程状态信息,比stat/statm更具可读性 |
/proc/self |
链接到当前正在运行的进程 |
5.3 文件的类型
文件类型缩写及别称
| 文件类型 | 缩写 | 英文 | 其他名称 | 说明 |
|---|---|---|---|---|
| 普通文件 | - | Regular file | 普通意义上的文件,如数据文件、可执行文件等 | |
| 目录文件 | d |
Directory file | Linux中目录也是一种文件,目录文件包括了文件夹中所有文件的名字和在分区中的位置,目录文件的权限意义也较特殊 | |
| 块特殊文件 | b |
Block special file | 块设备文件 | 一种提供带缓冲的固定大小单元读写的设备文件。如硬盘设备(/dev/sda)及硬盘分区(/dev/hda1)等 |
| 字符设备文件 | c |
Character special file | 字符设备文件 | 此种类型文件提供无缓存的变长单元读写。一个设备如果不是块设备,就是字符设备 |
| 先进先出 | p |
FIFO | named pipe,命名管道 | 用于系统进程间通信的文件 |
| 套接字文件 | s |
Socket | 进程之前通过网络进行通信的文件。多数网络连接都是用Socket建立的 | |
| 符号链接 | l |
Symbolic link | 软链接 | 此种文件仅是一个链接 |
stat命令用于查看一个文件有关文件系统的信息,ls命令就可以给出文件的类型