图像算法
一、opencv基础知识
二、opencv基础运算
三、opencv特征
3.1 图像形态学
形态学一般是使用二值图像,进行边界提取,骨架提取,孔洞填充,角点提取,图像重建。基本的算法:膨胀腐蚀,开操作,闭操作,击中击不中变换几种算法进行组合,就可以实现一些非常复杂的功能,而且逻辑严密。
数学形态学是一门建立在集论基础上的学科,是几何形态学分析和描述的有力工具。数学形态学的历史可回溯到19世纪。1964年法国的Matheron和Serra在积分几何的研究成果上,将数学形态学引入图像处理领域,并研制了基于数学形态学的图像处理系统。1982年出版的专著《Image Analysis and Mathematical Morphology》是数学形态学发展的重要里程碑,表明数学形态学在理论上趋于完备及应用上不断深入。数学形态学蓬勃发展,由于其并行快速,易于硬件实现,已引起了人们的广泛关注。目前,数学形态学已在计算机视觉、信号处理与图像分析、模式识别、计算方法与数据处理等方面得到了极为广泛的应用。
数学形态学可以用来解决抑制噪声、特征提取、边缘检测、图像分割、形状识别、纹理分析、图像恢复与重建、图像压缩等图像处理问题。
- 数学形态学的定义和分类
数学形态学是以形态结构元素为基础对图像进行分析的数学工具。它的基本思想是用具有一定形态的结构元素去度量和提取图像中的对应形状以达到对图像分析和识别的目的。数学形态学的应用可以简化图像数据,保持它们基本的形状特征,并除去不相干的结构。数学形态学的基本运算有4个:膨胀、腐蚀、开启和闭合。它们在二值图像中和灰度图像中各有特点。基于这些基本运算还可以推导和组合成各种数学形态学实用算法。
基础知识
数学形态学中的集合表示图像中的对象。例如,在二值图像中,所有白色像素的集合是该图像的一个完整的形态学描述。问题集合是二维整数空间Z^2的元素。
基本集合定义:
- 集合:用大写字母表示,空集记为\empty
- 元素:用小写字母表示
- 子集: A ⊆ B
- 并集: C = A⋃B
- 交集: D = A⋂B
- 补集:𝐴
- A^c= {𝑥|𝑥 ∉ 𝐴}
- 位移:(𝐴)௫= {𝑦|𝑦 = 𝑎 + 𝑥, 𝑎 ∈ 𝐴}
- 映像:𝐴መ = {𝑥|𝑥 = −𝑎, 𝑎 ∈ 𝐴}
- 差集:A − B = x x ∈ 𝐴, 𝑥 ∉ 𝐵 = A⋂𝐵
二值形态学
数学形态学中二值图像的形态变换是一种针对集合的处理过程。其形态算子的实质是表达物体或形状的集合与结构元素间的相互作用,结构元素的形状就决定了这种运算所提取的信号的形状信息。形态学图像处理是在图像中移动一个结构元素,然后将结构元素与下面的二值图像进行交、并等集合运算。基本的形态运算是腐蚀和膨胀。
在形态学中,结构元素是最重要最基本的概念。结构元素在形态变换中的作用相当于信号处理中的“滤波窗口”。用B(x)代表结构元素,对工作空间E中的每一点x,腐蚀和膨胀的定义为:
用B(x)对E进行腐蚀的结果就是把结构元素B平移后使B包含于E的所有点构成的集合。用B(x)对E进行膨胀的结果就是把结构元素B平移后使B与E的交集非空的点构成的集合。先腐蚀后膨胀的过程称为开运算。它具有消除细小物体,在纤细处分离物体和平滑较大物体边界的作用。先膨胀后腐蚀的过程称为闭运算。它具有填充物体内细小空洞,连接邻近物体和平滑边界的作用。
可见,二值形态膨胀与腐蚀可转化为集合的逻辑运算,算法简单,适于并行处理,且易于硬件实现,适于对二值图像进行图像分割、细化、抽取骨架、边缘提取、形状分析。但是,在不同的应用场合,结构元素的选择及其相应的处理算法是不一样的,对不同的目标图像需设计不同的结构元素和不同的处理算法。结构元素的大小、形状选择合适与否,将直接影响图像的形态运算结果。因此,很多学者结合自己的应用实际,提出了一系列的改进算法。如梁勇提出的用多方位形态学结构元素进行边缘检测算法既具有较好的边缘定位能力,又具有很好的噪声平滑能力。许超提出的以最短线段结构元素构造准圆结构元素或序列结构元素生成准圆结构元素相结合的设计方法,用于骨架的提取,可大大减少形态运算的计算量,并可同时满足尺度、平移及旋转相容性,适于对形状进行分析和描述。
- 腐蚀
- 膨胀
开运算:先腐蚀后膨胀,具有消除细小物体,在纤细处分离物体和平滑较大物体边界的作用
- 闭运算:先膨胀后腐蚀,具有填充物体内细小空洞,连接邻近物体和平滑边界的作用


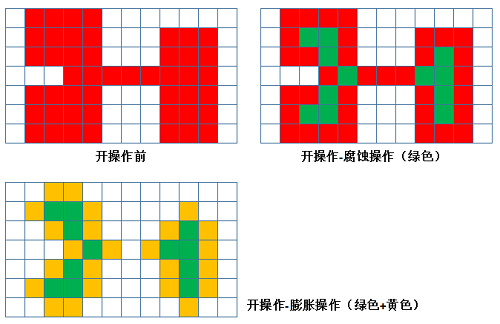
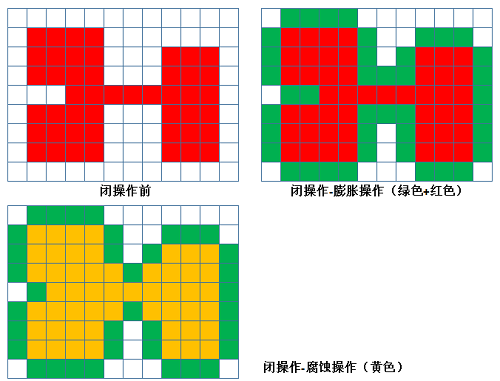
灰度数学形态学
二值数学形态学可方便地推广到灰度图像空间。只是灰度数学形态学的运算对象不是集合,而是图像函数。以下设f(x,y)是输入图像,b(x,y)是结构元素。用结构元素b对输入图像y进行膨胀和腐蚀运算分别定义为:
对灰度图像的膨胀(或腐蚀)操作有两类效果:
- 如果结构元素的值都为正的,则输出图像会比输入图像亮(或暗);
- 根据输入图像中暗(或亮)细节的灰度值以及它们的形状相对于结构元素的关系,它们在运算中或被消减或被除掉。灰度数学形态学中开启和闭合运算的定义与在二值数学形态学中的定义一致。用b对f进行开启和闭合运算的定义为:
模糊数学形态学
将模糊集合理论用于数学形态学就形成了模糊形态学。模糊算子的定义不同,相应的模糊形态运算的定义也不相同。在此,选用Shinba的定义方法。模糊性由结构元素对原图像的适应程度来确定。用有界支撑的模糊结构元素对模糊图像的腐蚀和膨胀运算按它们的隶属函数定义为:
其中,x,y\in Z^2代表空间坐标,u_a,u_b分别代表图像和结构元素的隶属函数。从上式的结果可知,经模糊形态腐蚀膨胀运算后的隶属函数均落在[0,1]的区间内。模糊形态学是传统数学形态学从二值逻辑向模糊逻辑的推广,与传统数学形态学有相似的计算结果和相似的代数特性。模糊形态学重点研究n维空间目标物体的形状特征和形态变换,主要应用于图像处理领域,如模糊增强、模糊边缘检测、模糊分割等。
- opencv相关函数
图像腐蚀:被扫描道到原始图像中的像素点,只有当卷积核对应的元素值均为1时,其值才为1,否则值为0
函数erode:dst = cv2.erode(src, kernel, iterations)
参数
- src:源图像
- kernel:卷积核 kernel = np.ones((5, 5), np.uint8)
- iterations:迭代次数
返回值
- dst : 处理结果
图像膨胀:被扫描道到原始图像中的像素点,当卷积核对应的元素值只要有一个为1时,其值就为1,否则值为0
函数dilate:dst = cv2.dilate(src, kernel, iterations)
参数
- src : 源图像
- kernel : 卷积核
- iterations : 迭代次数
返回值
- dst : 处理结果
综合的函数
函数morphologyEx:result = cv2.morphologyEx(img, type, kernel)
参数
- img : 源图像
- type : 图像形态学方法
- 开运算:cv2.MORPH_OPEN (可以去除噪声,并保持原有形状)
- 闭运算:cv2.MORPH_CLOSE (关闭前景物体内的小孔,或物体上的小黑点)
- 梯度运算:cv2.MORPH_GRADIENT (梯度(image)=膨胀(image)-腐蚀(image),得到轮廓图像)
- 礼帽运算:cv2.MORPH_TOPHAT (礼帽(image)=image-开运算(image),得到噪声图像)
- 黑帽运算:cv2.MORPH_BLACKHAT (黑帽(image)=闭运算(image)-image,得到图像内部的小孔或者景色中的小黑点)
- kernel:卷积核
返回值
- result:morphologyEx函数运算结果
import sys
import cv2
import numpy as np
import matplotlib.pyplot as plt
filename = "WX20190927-154211@2x.png"
img = cv2.imread(filename, 0) # 直接读为灰度图像
print(img.shape)
kernel = np.ones((17,17),np.uint8)
plt.figure(figsize=(int(sys.argv[1]),int(sys.argv[2])))
plt.subplot(4,2,1)
plt.imshow(img,'gray') # 显示原图像
plt.xticks([]),plt.yticks([]),plt.title('orignal')
erosion = cv2.erode(img,kernel,1)
plt.subplot(4,2,2),plt.imshow(erosion,'gray') # 显示腐蚀图像
plt.xticks([]),plt.yticks([]),plt.title("erosion")
erosion = cv2.dilate(img,kernel,1)
plt.subplot(4,2,3),plt.imshow(erosion,'gray') # 显示膨胀图像
plt.xticks([]),plt.yticks([]),plt.title("dilate")
erosion = cv2.morphologyEx(img,cv2.MORPH_OPEN,kernel)
plt.subplot(4,2,4),plt.imshow(erosion,'gray') # 显示开运算
plt.xticks([]),plt.yticks([]),plt.title("morph_open")
erosion = cv2.morphologyEx(img,cv2.MORPH_CLOSE,kernel)
plt.subplot(4,2,5),plt.imshow(erosion,'gray') # 显示闭运算
plt.xticks([]),plt.yticks([]),plt.title("morph_close")
erosion = cv2.morphologyEx(img,cv2.MORPH_GRADIENT,kernel)
plt.subplot(4,2,6),plt.imshow(erosion,'gray') # 显示梯度运算
plt.xticks([]),plt.yticks([]),plt.title("morph_gradient")
erosion = cv2.morphologyEx(img,cv2.MORPH_TOPHAT,kernel)
plt.subplot(4,2,7),plt.imshow(erosion,'gray') # 显示闭运算
plt.xticks([]),plt.yticks([]),plt.title("morph_tophat")
erosion = cv2.morphologyEx(img,cv2.MORPH_BLACKHAT,kernel)
plt.subplot(4,2,8),plt.imshow(erosion,'gray') # 显示闭运算
plt.xticks([]),plt.yticks([]),plt.title("morph_blackhat")
plt.savefig("xingtaixue.png")
# plt.show()

- 数学形态学在图像处理中的主要应用
近年来,数学形态学在图像处理方面得到了日益广泛的应用。下面主要就数学形态学在边缘检测、图像分割、图像细化以及噪声滤除等方面的应用做简要介绍。
边缘检测
边缘检测是大多数图像处理必不可少的一步,提供了物体形状的重要信息。对于二值图像,边缘检测是求一个集合A的边界,记为B(A):
对于灰度图像,边缘检测是求一幅图像的形态学梯度,记为g。
数学形态学运算用于边缘检测,存在着结构元素单一的问题。它对与结构元素同方向的边缘敏感,而与其不同方向的边缘(或噪声)会被平滑掉,即边缘的方向可以由结构元素的形状确定。但如果采用对称的结构元素,又会减弱对图像边缘的方向敏感性。所以在边缘检测中,可以考虑用多方位的形态结构元素,运用不同的结构元素的逻辑组合检测出不同方向的边缘。
梁勇等人构造了8个方向的多方位形态学结构元素,应用基本形态运算,得到8个方向的边缘检测结果,再把这些结果进行归一化运算、加权求和,得到最终的图像边缘。该算法在保持图像细节特征和平滑边缘等方面,取得了较好的效果。
边缘检测效果:


图像分割
基于数学形态学的图像分割算法是利用数学形态学变换,把复杂目标X分割成一系列互不相交的简单子集X_1,X_2,\dots,X_N,即(对目标X的分割过程可按下面的方法完成):
首先求出X的最大内接“圆”X_1,然后将X_1从X中减去,再求X-X_1的最大内接“圆”X_2,…,依此类推,直到最后得到的集合为空集为止。下面以二值图像为例,介绍用数学形态学方法求解子集X_1,X_2,\dots,X_N的过程。
数学形态学用于图像分割的缺点是对边界噪声敏感。为了改善这一问题,刘志敏等人提出了基于图像最大内切圆的数学形态学形状描述图像分割算法和基于目标最小闭包结构元素的数学形态学形状描述图像分割算法,并使用该算法对二值图像进行了分割,取得了较好的效果。邓世伟等人提出一种基于数学形态学的深度图像分割算法。作者首先利用形态学算子获得分别含有阶跃边缘与屋脊边缘的凸脊和凹谷图像,然后利用控制区域生长过程得到最终的分割结果。与传统方法相比,该方法速度快,抗噪性能好。
形态骨架提取
形态骨架描述了物体的形状和方向信息。它具有平移不变性、逆扩张性和等幂性等性质,是一种有效的形状描述方法。二值图像A的形态骨架可以通过选定合适的结构元素B,对A进行连续腐蚀和开启运算来求取,设S(A)代表A的骨架。蒋刚毅等人运用数学形态学方法,对交通标志的内核形状提取形态骨架函数,将其作为用于模式匹配的形状特征。
形态骨架函数完整简洁地表达了形态骨架的所有信息,因此,根据形态骨架函数的模式匹配能够实现对不同形状物体的识别。算法具有位移不变性,因而使识别更具稳健性。


形态学算法对于提取交叉的物体,会产生断裂,一般会在提取之后紧跟连接操作。
噪声滤除
对图像中的噪声进行滤除是图像预处理中不可缺少的操作。将开启和闭合运算结合起来可构成形态学噪声滤除器。对于二值图像,噪声表现为目标周围的噪声块和目标内部的噪声孔。用结构元素B对集合A进行开启操作,就可以将目标周围的噪声块消除掉;用B对A进行闭合操作,则可以将目标内部的噪声孔消除掉。该方法中,对结构元素的选取相当重要,它应当比所有的噪声孔和噪声块都要大。
对于灰度图像,滤除噪声就是进行形态学平滑。实际中常用开启运算消除与结构元素相比尺寸较小的亮细节,而保持图像整体灰度值和大的亮区域基本不变;用闭合运算消除与结构元素相比尺寸较小的暗细节,而保持图像整体灰度值和大的暗区域基本不变。将这两种操作综合起来可达到滤除亮区和暗区中各类噪声的效果。同样的,结构元素的选取也是个重要问题。
- 选取结构元素的方法
分析表明,各种数学形态学算法的应用可分解为形态学运算和结构元素选择两个基本问题,形态学运算的规则已由定义确定,于是形态学算法的性能就取决于结构元素的选择,亦即结构元素决定着形态学算法的目的和性能。因此如何自适应地优化确定结构元素,就成为形态学领域中人们长期关注的研究热点和技术难点。目前较多采用多个结构元素对图像进行处理的方法。
多结构元素运算
在许多形态学应用中,往往只采用一个结构元素,这通常不能产生满意的结果。在模式识别中,如果要提取某个特定的模式,只采用一个结构元素,那么,只有与结构元素形状、大小完全相同的模式才能被提取,而与此结构元素表示的模式即使有微小差别的其他模式的信息都不能获取。
解决此问题的一个有效方法之一就是将形态学运算与集合运算结合起来,同时采用多个结构元素,分别对图像进行运算,然后将运算后的图像合并起来,即多结构元素形态学运算。
用遗传算法选取结构元素
遗传算法的思想来源于自然界物竞天择、优胜劣汰、适者生存的演化规律和生物进化原理,并引用随机统计理论而形成,具有高效并行全局优化搜索能力,能有效地解决机器学习中参数的复杂优化和组合优化等难题。
近年来不少国外学者已进行了这方面的探索与研究,Ehrgardt设计了形态滤波的遗传算法,用于二值图像的去噪和根据二值纹理特性消除预定目标;Huttumen利用遗传算法构造了软式形态滤波器及其参数优化的设计方法,以实现灰度图像的降噪功能。余农、李予蜀等人用遗传算法在自然景象的目标检测与提取方面进行了研究,通过自适应优化训练使结构元素具有图像目标的形态结构特征,从而赋予结构元素特定的知识,使形态滤波过程融入特有的智能,以实现对复杂变化的图像具有良好的滤波性能和稳健的适应能力。其实质是解决滤波器设计中知识获取和知识精炼的机器学习问题。
- 数学形态学存在的问题与进一步的研究方向
数学形态学是一门建立在集论基础之上的学科,是几何形状分析和描述的有力工具。近年来,数学形态学在数字图像处理、计算机视觉与模式识别等领域中得到了越来越广泛的应用,渐渐形成了一种新的数字图像分析方法和理论,引起了国内外相关领域研究人员的广泛关注。目前,数学形态学存在的问题及研究方向主要集中在以下几个方面:
- 形态运算实质上是一种二维卷积运算,当图像维数较大时,特别是用灰度形态学、软数学形态学、模糊形态学等方法时,运算速度很慢,因而不适于实时处理。
- 由于结构元素对形态运算的结果有决定性的作用,所以,需结合实际应用背景和期望合理选择结构元素的大小与形状。
- 软数学形态学中关于结构元素核心、软边界的定义,及对加权统计次数*的选择也具有较大的灵活性,应根据图像拓扑结构合理选择,没有统一的设计标准。
- 为达到最佳的滤波效果,需结合图像的拓扑特性选择形态开、闭运算的复合方式。
- 对模糊形态学,不同的模糊算子会直接影响模糊形态学的定义及其运算结果。
- 有待进一步将数学形态学与神经网络、模糊数学结合研究灰度图像、彩色图像的处理和分析方法。
- 有待进一步研究开发形态运算的光学实现及其它硬件实现方法。
- 有待将形态学与小波、分形等方法结合起来对现有图像处理方法进行改进,进一步推广应用。所以如何实现灰度形态学、软数学形态学、模糊软数学形态学的快速算法,如何改善形态运算的通用性,增强形态运算的适应性,并结合数学形态学的最新应用进展,将其应用到图像处理领域,丰富和发展利用数学形态学的图像处理与分析方法,成为数学形态学今后的发展方向。
数学形态学对图像的处理具有直观上的简明性和数学上的严谨性,在定量描述图像的形态特征上具有独特的优势,为基于形状细节进行图像处理提供了强有力的手段。建立在集合理论基础上的数学形态学,主要通过选择相应的结构元素采用膨胀、腐蚀、开启、闭合#种基本运算的组合来处理图像。数学形态学在图像处理中的应用广泛,有许多实用的算法,但在每种算法中结构元素的选取都是一个重要的问题。
四、opencv特征学习
使用Haar分类器进行面部检测
六、图像分割传统方法
https://zhuanlan.zhihu.com/p/30732385
import cv2 import numpy as np
image_name = input("Enter the name of the picture:")
def detect(image_name): print("正在识别"+image_name+'...') # Load the image and convert it to grayscale image = cv2.imread(image_name) gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute the Scharr gradient magnitude representation of the iamges
# in both the x and y direction
# 原来代码下面是cv2.cv.CV_32F会报错->AttributeError: module 'cv2' has no attribute 'cv'
# 在新版本变为cv2.CV_32F
gradX = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 1, dy = 0, ksize = -1)
gradY = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 0, dy = 1, ksize = -1)
# substract the y-gradient from the x-gradient
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
# blur and threhold the image
# 这里(13,13)是kernel matrix size,自己可以改变看看识别效果
blurred = cv2.blur(gradient, (13, 13))
# 这里的阀值200,255也可以根据图片自定义
(_, thresh) = cv2.threshold(blurred, 200, 255, cv2.THRESH_BINARY)
# construct a closing kernel and apply it to the thresholded image
# (20, 15)也是一个参数,用来获取需要的kernel
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (20, 15))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# perform a series of erosions and dilations
closed = cv2.erode(closed, None, iterations = 4)
closed = cv2.dilate(closed, None, iterations = 4)
# Find the contours in the thresholded image, then sort the contours
# by their area, keeping only the largest one
# ValueError: too many values to unpack (expected 2)
(img,cnts, _) = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
# 原文这里使用cv2.cv.BoxPoints,新版本已经移除,换为cv2.boxPoints
box = np.int0(cv2.boxPoints(rect))
# draw a bounding box around the detected barcode
# and display the image
cv2.drawContours(image, [box], -1, (0,255,0), 3)
cv2.imshow(image_name, image)
cv2.waitKey(0)
print("Done...\n##################################")
imgs_pro.py
-- coding: utf-8 --
""" Created on Mon Dec 26 23:22:01 2016
@author: Administrator """ import os from bar_code import detect
切换到测试图片文件夹
os.chdir('test-imgs')
找到所有的测试图片文件名
image_names = os.listdir()
if name=='main': for image_name in image_names: detect(image_name)
https://blog.csdn.net/zmdsjtu/article/details/80736258
https://blog.csdn.net/stdcoutzyx/article/details/34842233
基于Haar特征的Adaboost级联人脸检测分类器,简称haar分类器。通过这个算法的名字,我们可以看到这个算法其实包含了几个关键点:Haar特征、Adaboost、级联。
1 算法要点 Haar分类器 = Haar-like特征 + 积分图方法 + AdaBoost +级联;
Haar分类器算法的要点如下:
a) 使用Haar-like特征做检测。
b) 使用积分图(IntegralImage)对Haar-like特征求值进行加速。
c) 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
d) 使用筛选式级联把分类器级联到一起,提高准确率。
2 历史 在2001年,Viola和Jones两位大牛发表了经典的《Rapid Object Detectionusing a Boosted Cascade of Simple Features》和《Robust Real-Time Face Detection》,在AdaBoost算法的基础上,使用Haar-like小波特征和积分图方法进行人脸检测,他俩不是最早使用提出小波特征的,但是他们设计了针对人脸检测更有效的特征,并对AdaBoost训练出的强分类器进行级联。这可以说是人脸检测史上里程碑式的一笔了,也因此当时提出的这个算法被称为Viola-Jones检测器。又过了一段时间,RainerLienhart和Jochen Maydt两位大牛将这个检测器进行了扩展,最终形成了OpenCV现在的Haar分类器。
AdaBoost是Freund和Schapire在1995年提出的算法,是对传统Boosting算法的一大提升。Boosting算法的核心思想,是将弱学习方法提升成强学习算法,也就是“三个臭皮匠顶一个诸葛亮”
Haar特征
什么是特征,特征就是分类器的输入。把它放在下面的情景中来描述,假设在人脸检测时我们需要有这么一个子窗口在待检测的图片窗口中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用我们训练好的级联分类器对该特征进行筛选,一旦该特征通过了所有强分类器的筛选,则判定该区域为人脸。
那么这个特征如何表示呢?好了,这就是大牛们干的好事了。后人称这他们搞出来的这些东西叫Haar-Like特征。
Viola大牛在[1]中提出的haar特征如下:
Rainer大牛改进了这些特征,提出了更多的haar特征。如下图所示:
这些所谓的特征不就是一堆堆带条纹的矩形么,到底是干什么用的?我这样给出解释,将上面的任意一个矩形放到人脸区域上,然后,将白色区域的像素和减去黑色区域的像素和,得到的值我们暂且称之为人脸特征值,如果你把这个矩形放到一个非人脸区域,那么计算出的特征值应该和人脸特征值是不一样的,而且越不一样越好,所以这些方块的目的就是把人脸特征量化,以区分人脸和非人脸。
4 Adaboost算法 本节旨在介绍AdaBoost在Haar分类器中的应用,所以只是描述了它在Haar分类器中的特性,而实际上AdaBoost是一种具有一般性的分类器提升算法,它使用的分类器并不局限某一特定算法。
[1]中给出的Adaboost算法流程如下图。
由adaboost在haar特征上构建分类器的流程可知,adaboost算法就是构建多个简单的分类器,每个简单的分类器都建立在之前分类器的基础上(对之前分类器分错了的样例提高其权重),然后将这些分类器加权,得到一个强大的分类器。
Adaboost的每一步训练出的分类器,如下图所示。其中,f表示特征的值,theta表示阈值,p则表示不等式的方向。这样的一个分类器就是基于一个特征的弱分类器。
更进一步,adaboost的一般算法框架如下。可以看到,Discrete Adaboost和GentleAdaboost在分类器的计算上和权重的更新上是有差别的。还有一种是RealAdaboost,即分类器输出的是一个概率而不只是+1与-1。[3]中就比较了这三种Adaboost的变种的效果。
5 级联 什么是级联分类器?级联分类器就是如下图所示的一种退化了的决策树。为什么说是退化了的决策树呢?是因为一般决策树中,判断后的两个分支都会有新的分支出现,而级联分类器中,图像被拒绝后就直接被抛弃,不会再有判断了。
级联强分类器的策略是,将若干个强分类器由简单到复杂排列,希望经过训练使每个强分类器都有较高检测率,而误识率可以放低,比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20约等于98%,错误接受率也仅为0.5^20约等于0.0001%。这样的效果就可以满足现实的需要了。文献[1]中给出了一种由简单到复杂设计级联分类器的方法,那就是添加特征法,对于第一个分类器,只用少数几个特征,之后的每个分类器都在上一个的基础上添加特征,直到满足该级的要求。
训练级联分类器的目的就是为了检测的时候,更加准确,这涉及到Haar分类器的另一个体系,检测体系,检测体系是以现实中的一幅大图片作为输入,然后对图片中进行多区域,多尺度的检测,所谓多区域,是要对图片划分多块,对每个块进行检测,由于训练的时候用的照片一般都是20*20左右的小图片,所以对于大的人脸,还需要进行多尺度的检测,多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高,而另一种方法,是不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。
6 积分图 积分图是用来加速计算haar特征的方法。Haar特征的计算所需要的基本数据就是区域内像素的和。而仅仅对于24*24的图片来说,它的不同类型的haar特征数目就有11W个(参考[3])。为了快速的计算出这些特征的值,就有了积分图表示图像的方法。
什么是积分图?对于与图像边界平行的haar特征来说,积分图就是与图像大小一样的一个二维数组。该数组中,(x,y)位置的值是原始图像中从(0,0)到(x,y)处的像素值的和。对于45度偏向的haar特征来说,也类似。如下图所示:
对于a、c图所示的haar特征。计算公式如下:
其中,SAT即为积分图中的值,RecSum即为(x,y)处的长宽为(w,h)的区域的和。有了RecSum后,就可以计算haar特征了。
相似的,b,d图所示的haar特征计算公式如下:
意义类似,不一一解释了。
积分图的好处在于,只对图片进行一次累计计算,就可以很方便的计算出haar特征值了。
7 总结 基于Haar特征的Adaboost级联分类器,在人脸的识别效果上并没有比其他算法高,其亮点在于检测速度。而速度的提升,有如下几方面的因素。第一:使用的特征简单,haar特征只需计算像素的和就可以了。第二:即便是如此简单的特征,还添加了积分图进行加速。第三,级联分类器的设定,使得大量的没有人脸的子窗口被抛弃。
参考文献 [1]. Viola P, Jones M. Rapid object detection using a boosted cascade of simple features[C]//Computer Vision and Pattern Recognition, 2001. CVPR 2001. Proceedings of the 2001 IEEE Computer Society Conference on. IEEE, 2001, 1: I-511-I-518 vol. 1. [2]. Lienhart R, Maydt J. An extended set of haar-like features for rapid object detection[C]//Image Processing. 2002. Proceedings. 2002 International Conference on. IEEE, 2002, 1: I-900-I-903 vol. 1. [3]. Lienhart R, Kuranov A, Pisarevsky V. Empirical analysis of detection cascades of boosted classifiers for rapid object detection[M]//Pattern Recognition. Springer Berlin Heidelberg, 2003: 297-304. ———————————————— 版权声明:本文为CSDN博主「张雨石」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/stdcoutzyx/java/article/details/34842233
'''
以 Haar 特征分类器为基础的面部检测技术
将面部检测扩展到眼部检测等。
以 Haar 特征分类器为基础的对 检测技术是一种 常有效的对 检测 技术 2001 年 Paul_Viola 和 Michael_Jones 提出 。它是基于机器学习的 使用大 的正 样本图像 练得到一个 cascade_function 最后再用它 来做对 检测。
现在我们来学习 检测。开始时 算法 大 的正样本图像 图 像 和 样本图像 不含 的图像 来 练分类器。我们 从其中提取特 征。下图中的 Haar 特征会 使用。它们就像我们的卷积核。每一个特征是一 个值 个值等于 色矩形中的像素值之后减去白色矩形中的像素值之和。
那么我们怎样从超过160000+ 个特征中 出最好的特征呢 ?
使用 Adaboost。
OpenCV 自带了训练器和检测器。如果你想自己训练一个分类器来检测 汽车飞机等的
可以使用 OpenCV 构建。
Cascade Classifier Training :http://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html
'''
import numpy as np
import cv2
# 运行之前,检查cascade文件路径是否在你的电脑上
face_cascade = cv2.CascadeClassifier('/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml')
eye_cascade = cv2.CascadeClassifier('/usr/local/share/OpenCV/haarcascades/haarcascade_eye.xml')
# img = cv2.imread('../data/sachin.jpg')
# img = cv2.imread('../data/kongjie_hezhao.jpg')
img = cv2.imread('../data/airline-stewardess-bikini.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# cv2.imshow('gray', gray)
# Detects objects of different sizes in the input image.
# The detected objects are returned as a list of rectangles.
# cv2.CascadeClassifier.detectMultiScale(image, scaleFactor, minNeighbors, flags, minSize, maxSize)
# scaleFactor – Parameter specifying how much the image size is reduced at each image
# scale.
# minNeighbors – Parameter specifying how many neighbors each candidate rectangle should
# have to retain it.
# minSize – Minimum possible object size. Objects smaller than that are ignored.
# maxSize – Maximum possible object size. Objects larger than that are ignored.
# faces = face_cascade.detectMultiScale(gray, 1.3, 5)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30), flags=cv2.CASCADE_SCALE_IMAGE)#改进
print("Detected ", len(faces), " face")
for (x, y, w, h) in faces:
img = cv2.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
roi_color = img[y:y + h, x:x + w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex, ey, ew, eh) in eyes:
cv2.rectangle(roi_color, (ex, ey), (ex + ew, ey + eh), (0, 255, 0), 2)
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
https://zhuanlan.zhihu.com/p/45625323